
Scoperta dei Dati
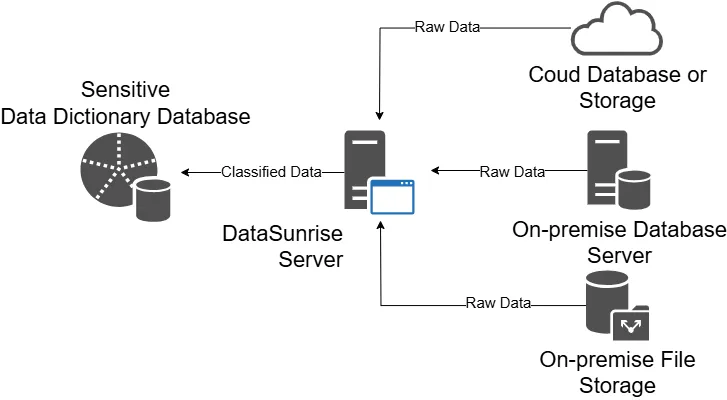
Si è mai chiesto quali metriche sono disponibili nei suoi dati? Sono disponibili metriche sul Tasso di Abbandono e sul Tasso di Ritenzione? O forse sta lottando con le procedure di conformità, chiedendosi ‘Sono a rischio di fughe di dati sensibili?’ La scoperta dei dati è un processo cruciale che aiuta le aziende e le organizzazioni a dare un senso ai loro vasti asset di dati. Comprende l’analisi dei dati provenienti da diversi luoghi per individuare tendenze, modelli e tipi di dati.
Le aziende possono scoprire intuizioni importanti e migliorare la business intelligence comprendendo meglio i loro dati. Questo aiuta anche con la sicurezza dei dati, la governance e la privacy. Quando i pipeline di dati falliscono, la scoperta dei dati aiuta a capire cosa è andato storto con i dati.
Il Potere della Scoperta dei Dati
Oggi, le organizzazioni possono avere una quantità schiacciante di dati da gestire. Questo può comportare la presenza di “dati oscuri” che restano inutilizzati. I dati oscuri possono potenzialmente creare rischi legali e di sicurezza. Ci sono diversi motivi per implementare la scoperta dei dati.

Gli analisti possono utilizzare i cataloghi dei dati e i dizionari per trovare e organizzare i dati sparsi. Possono poi pulire e combinare i dati per scoprire intuizioni importanti.
Migliorare la Scoperta dei Dati con l’IA e il Machine Learning
DataSunrise sfrutta efficacemente gli strumenti di ML per la sicurezza dei dati. L’Intelligenza Artificiale (IA) sta trasformando i processi di scoperta dei dati nella governance dei dati. Utilizzando l’IA e il machine learning, le organizzazioni possono semplificare i loro sforzi di esplorazione dei dati. Questo porta a intuizioni più rapide e decisioni più efficienti.
L’IA migliora la scoperta dei dati in diversi modi chiave:
- Automatizzare la classificazione dei dati
- Identificare modelli e anomalie
- Suggerire fonti di dati rilevanti
Gli algoritmi di machine learning eccellono nel categorizzare grandi quantità di informazioni. Questa classificazione automatizzata dei dati fa risparmiare tempo e riduce gli errori umani. È particolarmente utile quando si trattano grandi set di dati.
Scoperta dei Dati nella Data Science
La scoperta dei dati costituisce la base dei progetti di data science di successo. È il processo di trovare e comprendere le fonti di dati disponibili. Attraverso questa esplorazione, i data scientist scoprono intuizioni e modelli preziosi. Una scoperta dei dati efficace coinvolge diversi passaggi chiave:
- Identificare le fonti di dati rilevanti
- Valutare la qualità e la completezza dei dati
- Eseguire un’analisi iniziale dei dati
La classificazione dei dati gioca un ruolo vitale in questo processo. Categorizzando le informazioni, i scientist possono meglio organizzare e prioritizzare il loro lavoro. Questa classificazione aiuta a gestire correttamente i dati sensibili.
DataSunrise offre un eccellente supporto per l’archiviazione dei dati e i magazzini comunemente utilizzati nella data science, tra cui Snowflake, Amazon Redshift, e Athena, solo per citarne alcuni.
Dal momento che la data science utilizza pesantemente dati semi-strutturati, DataSunrise supporta la scoperta dei dati in formati grezzi (CSV, JSON) situati in storage come S3 o nel suo filesystem.
Potenziare la Business Intelligence con la Scoperta dei Dati
La scoperta dei dati svolge un ruolo fondamentale nel potenziare le iniziative di business intelligence.
Fornire agli analisti gli strumenti e le tecniche giuste aiuta le organizzazioni a prendere decisioni migliori, migliorare i processi e trovare opportunità di crescita.
I dashboard possono essere modificati per adattarsi a diversi gruppi di persone, come i dirigenti e i dipendenti di prima linea. In questo modo, tutti possono trovare facilmente le informazioni di cui hanno bisogno per prendere decisioni.
Sicurezza dei Dati e Conformità con la Scoperta dei Dati Basata su Python
Ok, Lei potrebbe dire, ci sono decine di strumenti Python open-source disponibili sul mercato. Tutto quello di cui ho bisogno è prenderne un paio e creare la mia catena di strumenti per la scoperta dei dati.
E questa è un’idea totalmente valida per un paio di ragioni. Conoscerà tutto sui suoi strumenti e sarà in grado di implementare qualsiasi scoperta dei dati desidera in futuro. Inoltre, questo semplice costo totale di proprietà della catena di strumenti è solo il suo tempo per scrivere qualche codice.
L’inconveniente possibile è il seguente: potrebbe volerci un po’ di tempo per implementare tutte le varianti desiderate. Potrebbe lottare con la difficoltà della scalabilità e del supporto del suo sistema man mano che nuovi database vengono rilasciati e cambiano il loro comportamento dei driver.
Ecco il codice per scoprire le email in un database PostgreSQL. Dovrebbe funzionare con i suoi parametri di connessione al database. Potrebbe notare che, pur non essendo scienza missilistica, richiede comunque una certa conoscenza delle infrastrutture e di Python. E questo codice non memorizza i risultati della ricerca.
import psycopg2
import re
# Definire i parametri di connessione
db_params = {
'dbname': 'mydatabase01',
'user': 'postgres',
'password': 'pass',
'host': 'localhost'
}
# Connettersi al database
try:
conn = psycopg2.connect(**db_params)
print("Connesso al database")
except Exception as e:
print(f"Impossibile connettersi al database: {e}")
exit()
# Funzione per trovare indirizzi email in uno schema
def find_emails_in_schema(schema):
try:
cursor = conn.cursor()
# Query per trovare tutte le tabelle nello schema specificato
cursor.execute(f"""
SELECT table_name
FROM information_schema.tables
WHERE table_schema = '{schema}'
""")
tables = cursor.fetchall()
email_pattern = re.compile(r'[\w\.-]+@[\w\.-]+')
for table in tables:
table_name = table[0]
# Query per selezionare tutte le colonne dalla tabella
cursor.execute(f"""
SELECT column_name
FROM information_schema.columns
WHERE table_schema = '{schema}'
AND table_name = '{table_name}'
""")
columns = cursor.fetchall()
# Selezionare tutti i dati dalla tabella
cursor.execute(f'SELECT * FROM {schema}.{table_name}')
rows = cursor.fetchall()
for row in rows:
for column, value in zip(columns, row):
if value and isinstance(value, str):
if email_pattern.search(value):
print(f'Trovata email: {value} nella tabella: {table_name}, colonna: {column[0]}')
except Exception as e:
print(f"Errore nel trovare le email: {e}")
finally:
cursor.close()
# Specificare lo schema da cercare
schema_name = 'public'
find_emails_in_schema(schema_name)
# Chiudere la connessione
conn.close()
Il codice stampa righe come la seguente:
Trovata email: [email protected] nella tabella: mock_data, colonna: email
Strumenti DataSunrise
DataSunrise include tutte le funzionalità necessarie per la scoperta dei dati sensibili (o di qualsiasi altro tipo). Di seguito, forniamo alcuni esempi dalla sua interfaccia utente.
Il seguente è un elenco di Tipi di Informazioni. È possibile creare quanti tipi di informazioni personalizzati si desidera, ciascuno con uno o più attributi per la scoperta. Si possono anche usare decine di tipi predefiniti se si preferisce.
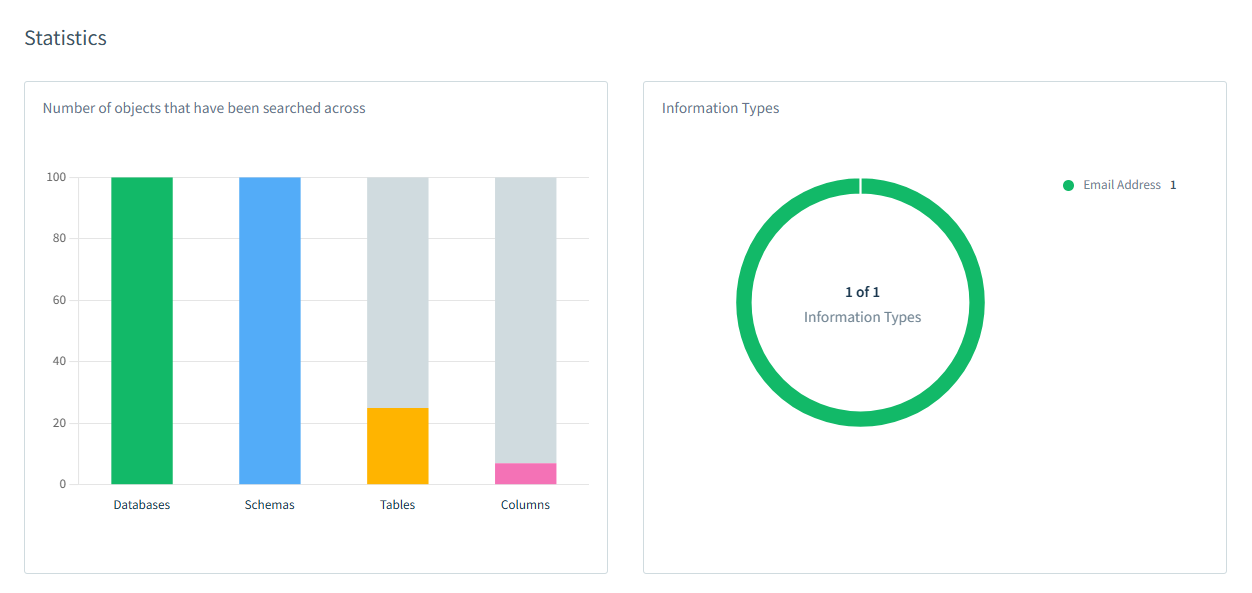
Dopo che il compito di scoperta è terminato, si può vedere un’informazione dettagliata sui risultati. Inoltre, si può stimare la quantità di dati scoperti rispetto alla quantità totale nei suoi schemi, tabelle o colonne. L’immagine qui sotto mostra che gli indirizzi email sono stati trovati nel 100% dei database target, nel 100% degli schemi, nel 22% delle tabelle e in meno del 5% delle colonne.
Conclusione
La scoperta dei dati è un processo critico che consente alle organizzazioni di sbloccare tutto il potenziale dei loro asset di dati.
Le aziende possono utilizzare tecnologie avanzate come l’IA, il machine learning e l’analisi dei dati per comprendere meglio i loro dati. Analizzando i dati si possono scoprire modelli e tendenze, aiutando a prendere decisioni migliori e promuovere l’innovazione.
Queste tecnologie possono anche aiutare a generare nuove idee, scoprendo opportunità nascoste e prevedendo le tendenze future del mercato.
Inoltre, le tecnologie avanzate possono aiutare a proteggere le informazioni sensibili, implementando robuste misure di sicurezza come crittografia, controlli di accesso e sistemi di rilevamento delle minacce. Proteggere i dati aiuta a evitare violazioni e attacchi informatici, mantenendo le informazioni al sicuro.
Utilizzare tecnologie avanzate può aiutare le aziende a utilizzare meglio i loro dati, essere più innovative e proteggere le informazioni sensibili. Questo può portare a un miglioramento delle prestazioni e a un vantaggio competitivo sul mercato.
Man mano che i dati crescono, è importante che le organizzazioni investano in strumenti di scoperta dei dati per rimanere al passo.
DataSunrise fornisce una vasta gamma di mezzi per scoprire i dati. Contatti il nostro team per prenotare una demo e imparare come farlo ora.
