
Comprensione dei Tipi di Informazione: Sicurezza Ispirata dai Dati in DataSunrise
Introduzione
DataSunrise presenta la sicurezza ispirata dai dati, offrendo capacità uniche e potenti per una rapida scoperta dei dati su ogni richiesta di dati per una fonte dati specifica. Sebbene questo approccio crei un certo overhead di tempo di esecuzione, fornisce una protezione del database estremamente flessibile.
I Tipi di Informazione sono stati introdotti per la prima volta in DataSunrise con la funzionalità di Scoperta dei Dati Sensibili, che scansiona database e sistemi di archiviazione come S3 per i dati sensibili.
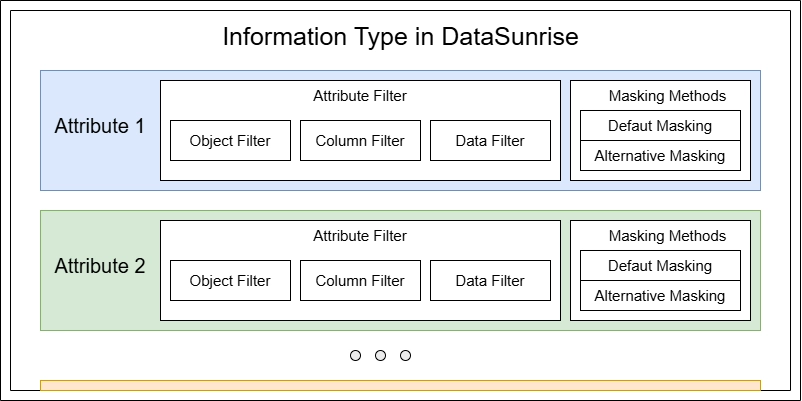
I Tipi di Informazione offrono funzionalità oltre alla Scoperta dei Dati di base. Consentono il rilevamento dei tipi di dati in tempo reale e possono attivare automaticamente regole di protezione o audit attraverso la Sicurezza Ispirata dai Dati con ogni query di database. Inoltre, facilitano l’etichettatura delle tracce di audit, rendendo più facile tracciare specifici eventi di accesso ai dati sia nelle Tracce Transazionali che nei file log.
Scoprire i Tipi di Informazione
Le proprietà dei dati devono essere memorizzate in un’entità per l’analisi. A volte questi dati hanno una struttura rigorosa con nomi di colonne, nomi di tabelle e tipi. Altre volte, possono apparire come JSON, file CSV, testo semplice o persino immagini di documenti scansionati. DataSunrise consente di cercare tutti questi oggetti per dati sensibili.
Questo porta a descrizioni flessibili dei Tipi di Informazione. Ad esempio, i dati delle email possono avere diverse proprietà:
- Il nome della colonna contiene “email”
- Il nome della tabella contiene “email”
- I dati corrispondono all’espressione regolare “.*@.*“
Per essere classificati come informazione email, i dati devono soddisfare più requisiti. Questo introduce un’altra importante entità di DataSunrise chiamata Attributo di Informazione. Un Tipo di Informazione è fondamentalmente una raccolta di attributi che i dati devono corrispondere per essere considerati di un tipo specifico.
Quando si cerca dati sensibili in un semplice file di testo senza colonne e tabelle, il set di attributi può essere diverso. Ad esempio, il Tipo di Informazione email testo semplice potrebbe richiedere solo la corrispondenza regex, senza ulteriori attributi necessari.
Tipi di Informazione Disponibili in DataSunrise
DataSunrise include numerosi Tipi di Informazione integrati, ciascuno associato a standard di sicurezza popolari (GDPR, HIPAA, SOX e altri). Sebbene questa associazione non sia obbligatoria per tipi personalizzati, aiuta a tracciare l’attività e raccogliere dati sull’uso per audit di conformità.
Gli utenti possono creare Tipi di Informazione personalizzati, che spaziano da semplici a complessi. Il tipo email integrato, ad esempio, include attributi che corrispondono ai nomi di colonne e a complessi schemi di corrispondenza per il contenuto delle email.
DataSunrise offre molteplici Tipi di Informazione sulle Date per soddisfare varie convenzioni di formattazione delle date. È importante notare che diversi Tipi di Informazione possono essere utilizzati per identificare lo stesso tipo di dati quando sono memorizzati in formati diversi.
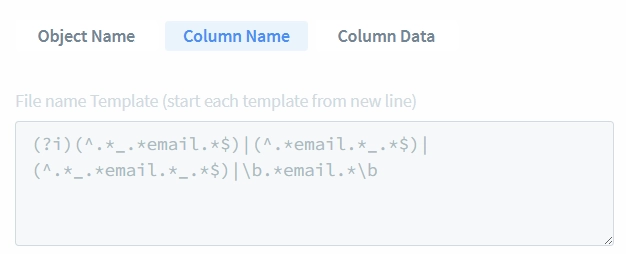
Per una corrispondenza più semplice dei Tipi di Informazione, raccomandiamo di creare tipi personalizzati con attributi più flessibili. Nella nostra pratica, la maggior parte degli utenti crea un tipo di dati email personalizzato che richiede solo che il contenuto dei dati corrisponda a un semplice schema di espressione regolare come “@.*”.
I tipi personalizzati consentono di aggiungere nuovi Tipi di Informazione per il rilevamento e di controllare quanto strettamente questi Tipi di Informazione corrispondono ai modelli di dati. È possibile creare Tipi di Informazione che richiedono più Attributi, ciascuno contenente nomi di colonne e modelli di dati, oppure creare Tipi di Informazione più semplici con un solo Attributo che verifica solo il modello di dati.
Come Creare un Tipo di Informazione Personalizzato
Passo 1 – Aggiungi Nuovo Tipo di Informazione
- Naviga su Data Discovery – Tipi di Informazione
- Premi il pulsante “+ Aggiungi Tipo di Informazione” e inserisci un nome adatto per il tuo Tipo di Informazione personalizzato.
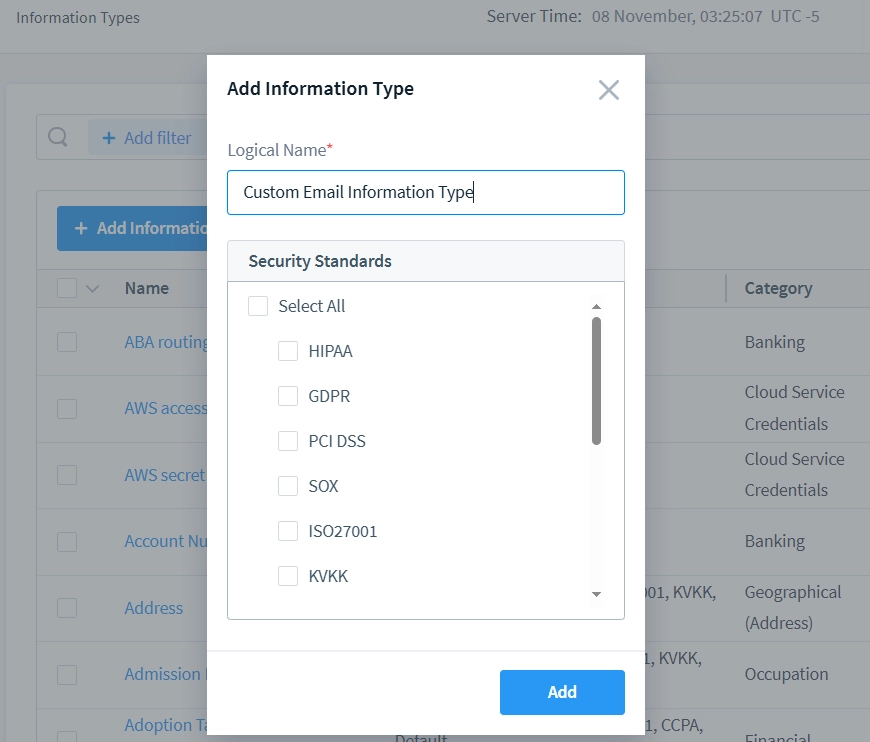
- Dopo aver impostato il nome del Tipo di Informazione, apparirà nell’elenco nella pagina “Tipi di Informazione”. Clicca sul nuovo Tipo di Informazione per modificare i suoi parametri interni e Attributi. Usiamo il ‘Tipo di Informazione Email Personalizzato’ come esempio.
La pagina di Modifica del Tipo di Informazione contiene tre sottosezioni principali:
- La sezione Attributi ti permette di impostare i parametri di corrispondenza effettiva per il Tipo di Informazione. Puoi creare uno o più attributi, e ciascun attributo può contenere requisiti per l’oggetto database, il nome della colonna e lo schema dati. Il Tipo di Informazione corrisponde se corrisponde qualsiasi singolo attributo. Per gli attributi inclusi, tutte le condizioni (oggetto, schema del nome della colonna e schema dati) devono essere soddisfatte se specificate.
- La sezione Standard di Sicurezza ti consente di collegare il Tipo di Informazione a Standard di Sicurezza. Questo è utilizzato dalla funzionalità di Conformità durante i compiti di scoperta, poiché la funzionalità di Conformità opera in base agli standard di sicurezza.
- La sezione Gestisci Tag ti aiuta a trovare facilmente le voci di log delle regole nei registri o nei rapporti. Puoi creare tag personalizzati per questo scopo.
Passo 2 – Aggiungi Attributo al Tipo di Informazione
- Creiamo un semplice attributo per il “Tipo di Informazione Email Personalizzato.” Premi il pulsante “+ Aggiungi Attributo” per iniziare. Lo imposteremo per adattarsi a dati che seguono uno schema email di base: “.*@.*“
Nota: Questo schema è eccessivamente semplificato e corrisponderà in modo errato a voci non valide come “@.” o “!!!@…”. In ambienti di produzione, dovrebbe essere utilizzato uno schema di validazione delle email più robusto.
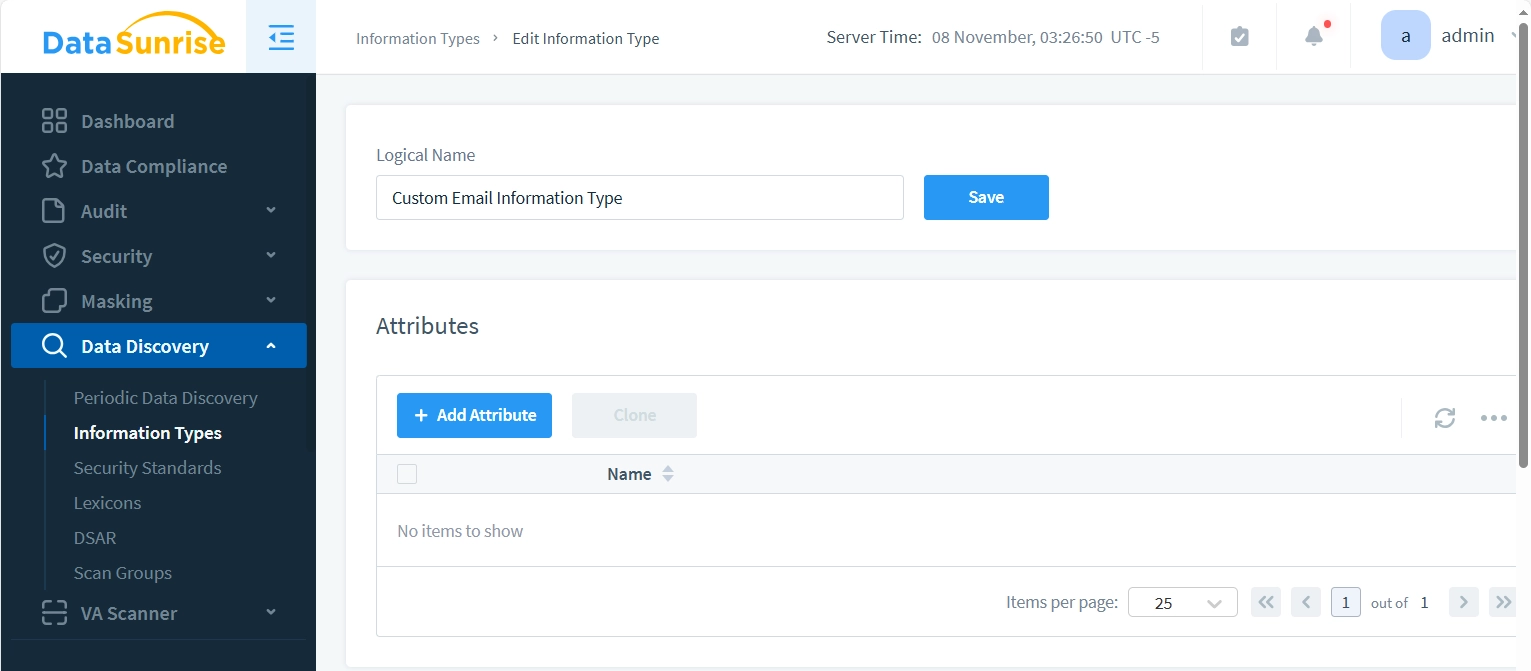
La nuova finestra di dialogo degli attributi appare con due pannelli: “Attributo” a sinistra e “Test” a destra. Il pannello Attributo viene utilizzato per configurare le impostazioni del nuovo attributo, mentre il pannello Test consente di verificare queste impostazioni durante la creazione.
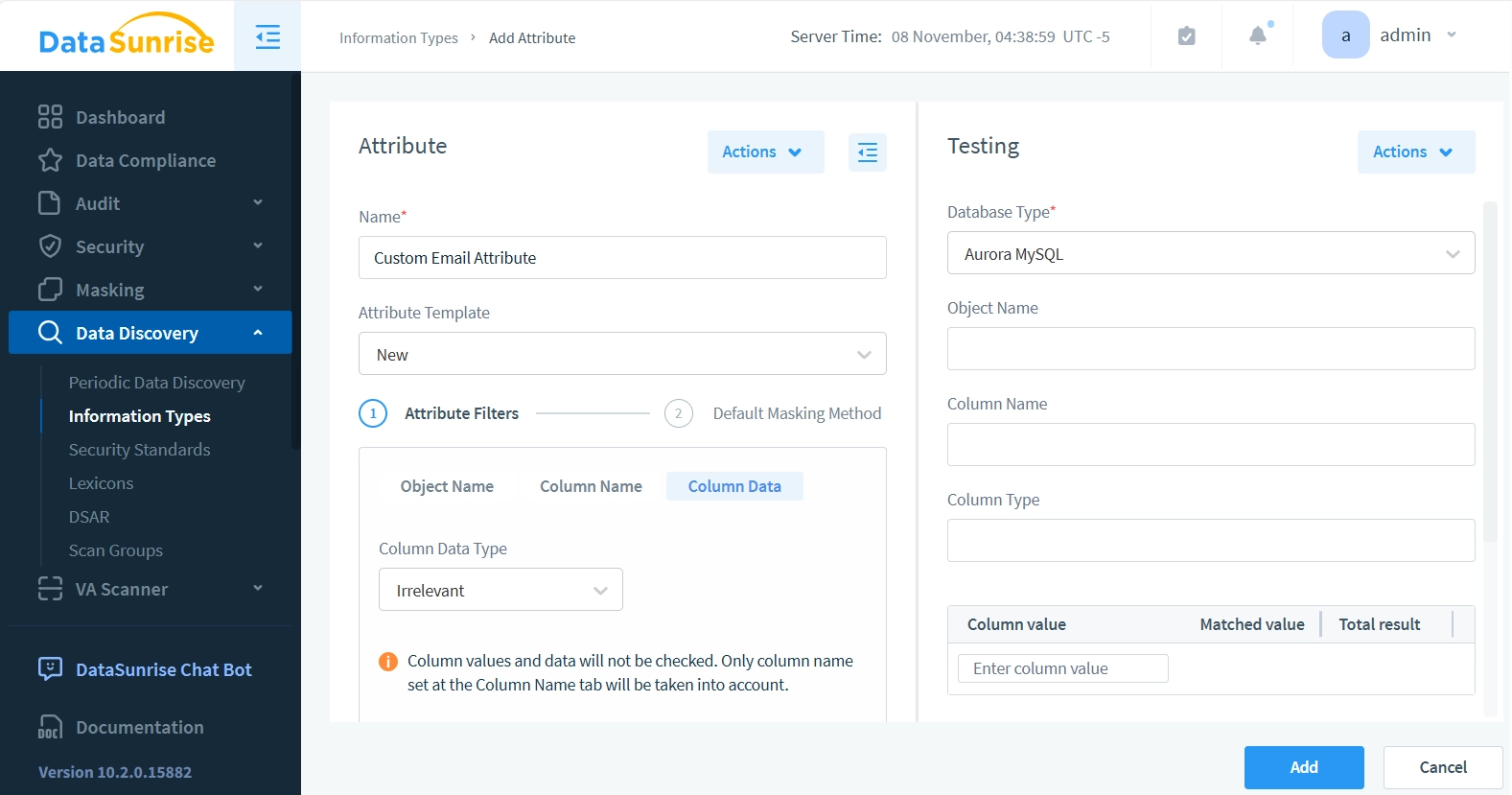
- Nel pannello “Attributo”, inserisci “Attributo Email Personalizzato” nel campo Nome. Per Modello di Attributo, manterremo l’opzione predefinita “Nuovo”, poiché non abbiamo ancora altri modelli disponibili.
Ora ci concentreremo su due aree chiave: Filtri Attributo e Metodo di Mascheramento Predefinito.
- Per i Filtri Attributo, lascia inalterati i campi Nome dell’Oggetto e Nome della Colonna. Seleziona solo l’opzione Dati della Colonna. Questo significa che il nostro attributo ignorerà i modelli di Nome dell’Oggetto del Database e Nome della Colonna, concentrandosi esclusivamente sulla verifica se la stringa di dati contiene uno schema simile a un’email (con un carattere @).
- Imposta il Tipo di Dati della Colonna su “Solo Stringhe” e il Metodo di Ricerca su “Testo Non Strutturato”.
- Inserisci “.*@.*” nel campo “Modello per il Contenuto della Colonna (inizia ogni modello da una nuova linea)”. Prima di salvare l’attributo o di utilizzarlo in regole o compiti, possiamo testare se corrisponde correttamente agli schemi email.
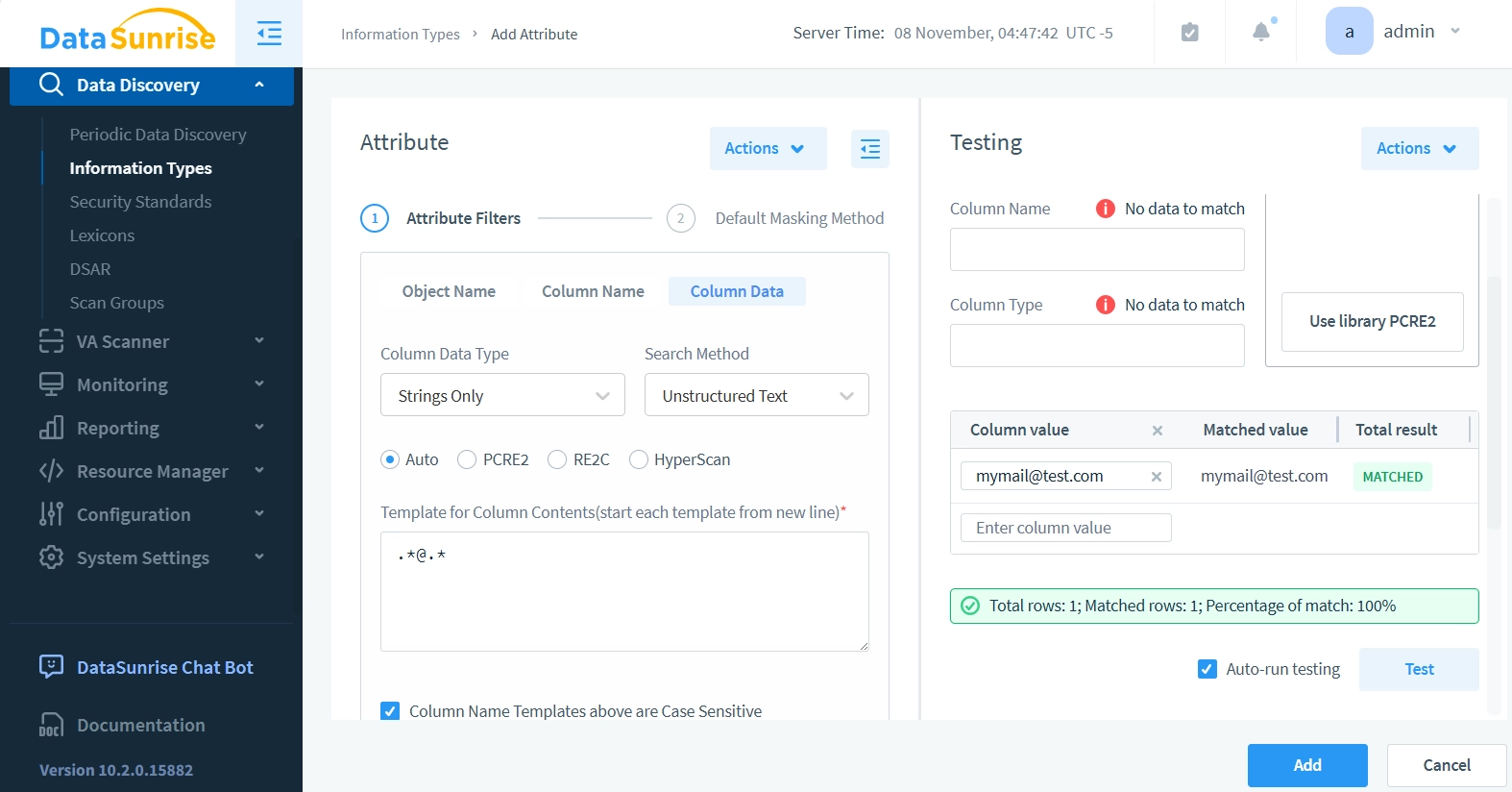
- Ora utilizziamo il pannello Test a destra. Lascia invariati tutti i campi precedenti e inserisci un’email di esempio come “[email protected]” nel campo Valore della Colonna. Fai clic sul pulsante Test – i risultati dovrebbero mostrare che l’Attributo rileva con successo le email nei dati della colonna.
Passo 3 – Impostazioni di Mascheramento Attributo
- Fai clic su ‘2. Metodo di Mascheramento Predefinito’ per continuare con la configurazione del metodo di mascheramento. Questo cambia il pannello Attributo alla configurazione del mascheramento.
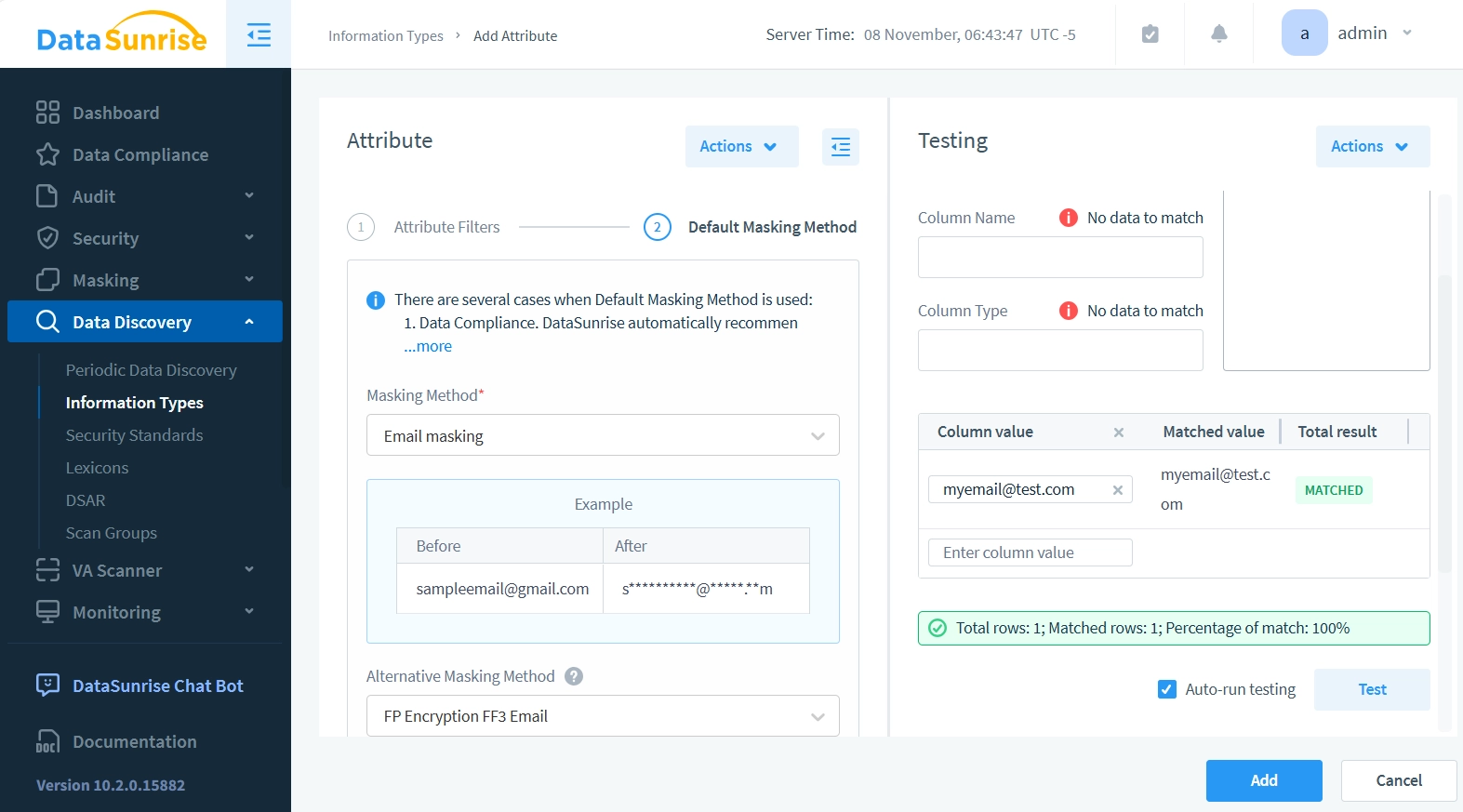
- Imposta il menu a tendina Metodo di Mascheramento su Mascheramento Email. Il Metodo di Mascheramento Predefinito è utilizzato negli strumenti di Conformità dei Dati, nel Mascheramento Dinamico Ispirato dai Dati e nel Mascheramento Statico. DataSunrise applica questo metodo di mascheramento quando non ci sono vincoli chiave che devono essere mantenuti per preservare l’integrità del database mascherato.
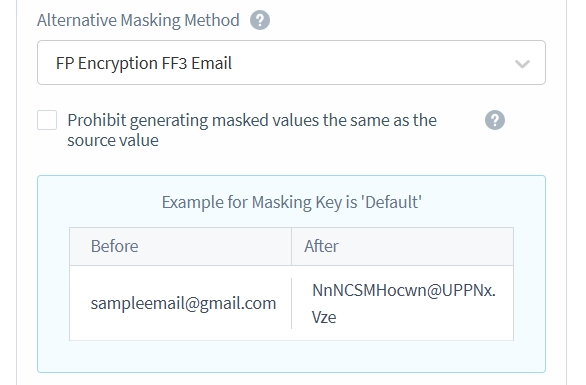
- Imposta il menu a tendina Metodo Alternativo di Mascheramento su FP Encryption FF3 Email. I metodi di mascheramento alternativi sono necessari quando si mantiene l’integrità referenziale della tabella. Non è possibile semplicemente mascherare le chiavi esterne con stringhe casuali, poiché ciò romperebbe riferimenti tra tabelle. Il mascheramento deve assicurare che i riferimenti da altre tabelle puntino ancora alle righe corrette dopo l’applicazione del mascheramento. Allo stesso modo, le chiavi primarie devono rimanere uniche e mantenere le loro relazioni referenziali con altre tabelle anche dopo il mascheramento.
Nell’esempio di Mascheramento Statico di seguito, le colonne ’email’ e ‘contact_email’ sono mascherate utilizzando metodi diversi a causa di vincoli chiave. Ad esempio, l’indirizzo email di John Doe, che ha un vincolo di chiave esterna, viene mascherato come ‘[email protected]’. Nel frattempo, il suo contact_email, che non ha vincoli, viene mascherato utilizzando il metodo predefinito, apparendo come ‘j***.***@.**m’.
Importante: Sebbene questa configurazione sia compatibile con i database tradizionali, alcuni sistemi di archiviazione come Amazon S3 e i file di testo non strutturato non seguono l’organizzazione tipica dei database con colonne e oggetti. Per questi tipi di archiviazione, prestare attenzione quando si utilizzano filtri per nomi di oggetto e nomi di colonna, poiché potrebbero impedire la corretta corrispondenza dei dati.
- Fai clic sul pulsante ‘Aggiungi’ per collegare l’Attributo al Tipo di Informazione.
Testare i Tipi di Informazione con Metodi di Mascheramento Alternativi
L’esempio seguente dimostra come DataSunrise implementa sia metodi di mascheramento Predefiniti che Alternativi. Esaminiamolo attraverso la creazione di tabelle di esempio:
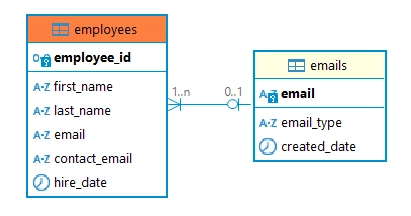
-- Creazione della tabella emails (Tabella Genitore)
CREATE TABLE emails (
email VARCHAR(50) PRIMARY KEY,
email_type VARCHAR(20),
created_date DATE
);
-- Creazione della tabella employees con contact_email aggiuntivo
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(30),
last_name VARCHAR(30),
email VARCHAR(50),
contact_email VARCHAR(50),
hire_date DATE,
FOREIGN KEY (email) REFERENCES emails(email)
);
-- Inserimento dati nella tabella emails
INSERT INTO emails VALUES
('[email protected]', 'corporate', '2023-01-15'),
('[email protected]', 'corporate', '2023-02-20'),
...
('[email protected]', 'corporate', '2023-05-01');
-- Inserimento dati nella tabella employees con email di contatto
INSERT INTO employees VALUES
(1, 'John', 'Doe', '[email protected]', '[email protected]', '2023-01-16'),
(2, 'Sarah', 'Smith', '[email protected]', '[email protected]', '2023-02-21'),
...
(5, 'Peter', 'Jones', '[email protected]', '[email protected]', '2023-05-02');
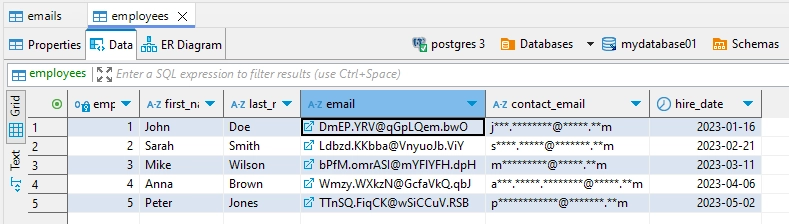
Mascheramento Statico con Mascheramento Predefinito e Alternativo
Il mascheramento statico consente agli utenti di mascherare automaticamente i dati sensibili identificati durante il processo di scoperta. Questo approccio automatizzato, noto come Modalità Automatica, determina quali tabelle di origine trasferire e quali colonne mascherare. Il sistema implementa due strategie di mascheramento distinte: una per i campi dati standard e un’altra per gli elementi di dati relazionali (come chiavi esterne e primarie). Questo approccio duale garantisce la coerenza dei dati pur mantenendo l’integrità referenziale tra le relazioni del database.
Durante l’esecuzione del Compito di Mascheramento Statico sulla tabella ’employees’, diversi metodi di mascheramento sono stati applicati ai campi email. La colonna ’email’ vincolata, che funge da chiave esterna, ha mantenuto il suo formato attraverso il mascheramento a formato preservato. Nel frattempo, la colonna ‘contact_email’ non vincolata ha subito un semplice mascheramento carattere, dove solo la porzione centrale delle email è stata oscurata.
Conclusione
Questo articolo ha fornito un’esplorazione approfondita dei Tipi di Informazione di DataSunrise. Ti abbiamo guidato attraverso i principali passaggi per la creazione dei Tipi di Informazione e la definizione dei loro attributi. I Tipi di Informazione sono principalmente utilizzati nella Scoperta dei Dati per identificare i dati sensibili basati su proprietà specifiche definite dai loro attributi. Inoltre, questi Tipi di Informazione sono attivamente utilizzati durante l’accesso ai dati attraverso una funzione chiamata Sicurezza Ispirata dai Dati, che consente il mascheramento dei dati, il blocco e l’etichettatura degli eventi nei log.
Abbiamo anche esaminato casi d’uso per il mascheramento predefinito e discusso come i metodi di mascheramento alternativi possono essere applicati quando i compiti di mascheramento statico incontrano vincoli chiave nel database mascherato.
