
Rimescolamento dei nomi
Introduzione
Le organizzazioni spesso faticano a proteggere i dati sensibili pur avendo bisogno di set di dati realistici per test e sviluppo. Qui entrano in gioco tecniche come il mascheramento dei dati e il rimescolamento dei nomi.
Ecco una curiosità: l’Amministrazione della Sicurezza Sociale degli Stati Uniti pubblica dati annuali sui nomi dei neonati, con circa 30.000–35.000 nomi unici utilizzati ogni anno. Questo tipo di dataset è ideale per generare dati di test credibili, ma anonimizzati.
Questo articolo esplora come funziona il rimescolamento dei nomi, come viene implementato e perché è efficace per creare ambienti di test sicuri.
DataSunrise offre avanzate capacità di mascheramento dei dati, inclusi rimescolamenti intelligenti, che preservano il realismo garantendo al contempo la privacy. La nostra piattaforma aiuta le organizzazioni a soddisfare i requisiti di conformità e a proteggere i dati sensibili senza sacrificare le funzionalità.
Con DataSunrise, puoi selezionare casualmente valori da lessici personalizzati, creati manualmente o estratti da database attivi. Questo consente sia il rimescolamento deterministico che la sostituzione casuale per la generazione di dati di test sicuri e di alta qualità.
Cos’è il Mascheramento dei Dati?
Prima di addentrarci nel rimescolamento dei nomi, diamo una breve occhiata al mascheramento dei dati. Il mascheramento dei dati è un metodo usato per creare una versione strutturalmente simile ma non autentica dei dati di un’organizzazione. Sostituisce informazioni sensibili con dati realistici, ma fittizi. Questo permette alle aziende di utilizzare i dati mascherati per test, sviluppo e analisi senza rischiare l’esposizione di informazioni riservate.
Normative sul Mascheramento dei Dati e Conformità
I quadri normativi mandano sempre più spesso a proteggere i dati attraverso tecniche di mascheramento. Il GDPR richiede misure di sicurezza appropriate per il trattamento dei dati personali. L’HIPAA impone la protezione delle informazioni sanitarie negli ambienti non di produzione. Lo standard PCI DSS proibisce l’uso di dati reali dei titolari di carta per i test. Il CCPA permette ai consumatori di controllare l’uso delle informazioni personali. Gli standard di settore spesso richiedono l’anonimizzazione dei dati di test. Le organizzazioni sanitarie affrontano rigorosi requisiti sulla privacy dei dati dei pazienti. Le istituzioni finanziarie devono proteggere i dettagli finanziari dei clienti durante lo sviluppo. Le sanzioni per il mancato rispetto della conformità possono raggiungere milioni di dollari. Il mascheramento dei dati fornisce prove documentate della conformità alla privacy. Le normative richiedono spesso valutazioni formali del rischio per la gestione dei dati. Audit di conformità regolari verificano la corretta implementazione del mascheramento. Le aziende devono dimostrare misure di sicurezza ragionevoli attraverso tecniche come il rimescolamento.
Comprendere il Rimescolamento dei Nomi
Cos’è il rimescolamento dei nomi?
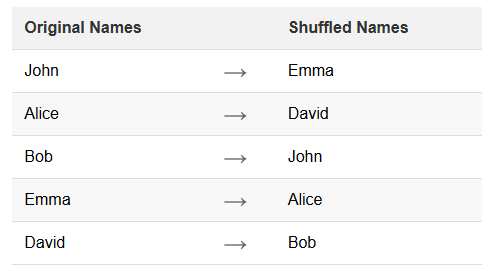
Il rimescolamento dei nomi è una tecnica specifica di mascheramento dei dati. Consiste nel riordinare i dati esistenti all’interno di un dataset. Questo metodo mantiene l’integrità e il realismo dei dati, oscurando le identità individuali. Il rimescolamento è particolarmente utile per proteggere le informazioni personali nei database.
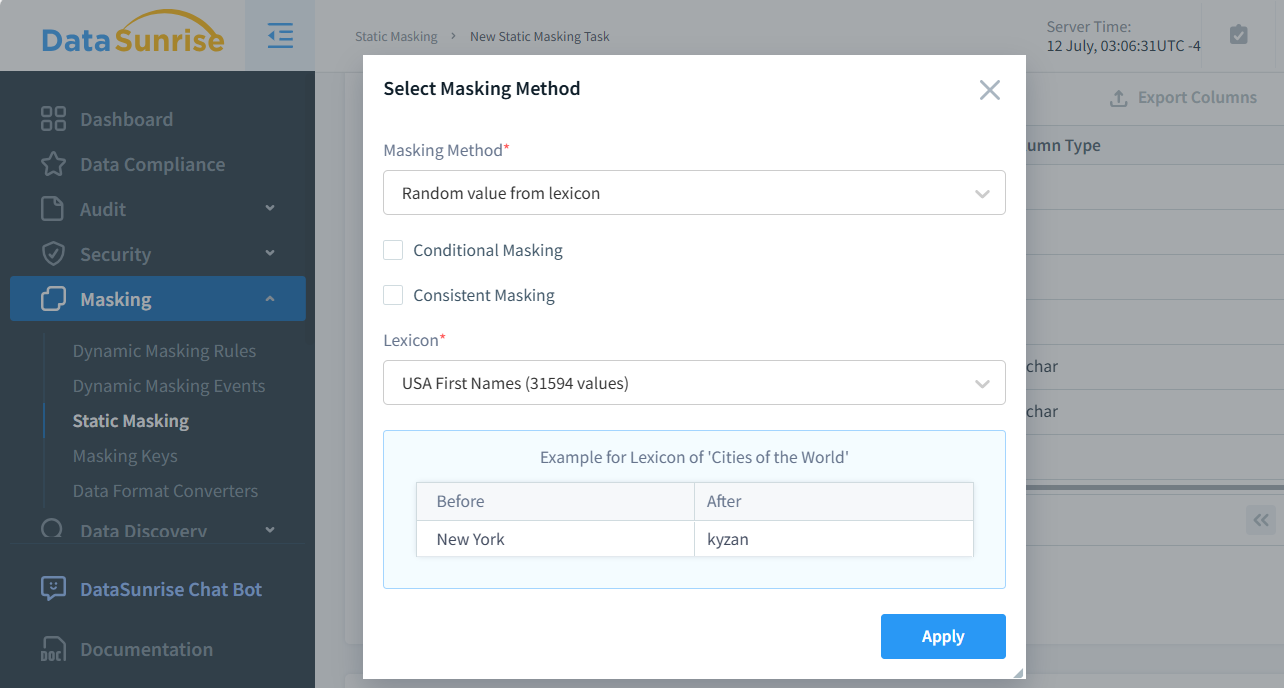
Come menzionato nell’Introduzione, DataSunrise ti permette di creare una selezione casuale di valori basata su un lessico per il mascheramento. La figura sottostante mostra la selezione di questo metodo di mascheramento nell’interfaccia utente di DataSunrise. Come puoi vedere, sono disponibili 31.594 valori, il che è molto più affidabile che semplicemente mescolare un set dato. Questa maggiore affidabilità è dovuta al fatto che, quando ci sono n valori unici in una colonna, la probabilità che un valore venga mappato su se stesso è 1/n.
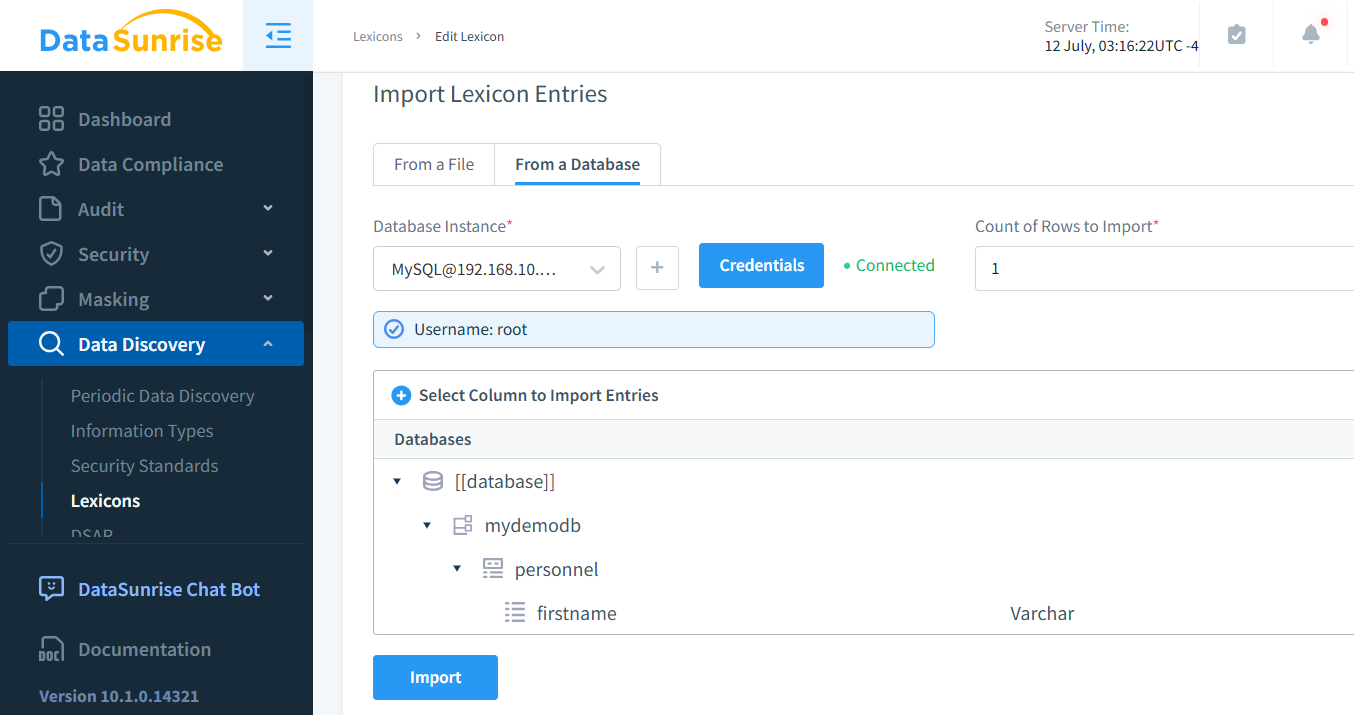
Se preferisci mappare con valori esistenti, puoi facilmente ottenere questo risultato creando un lessico personalizzato. Questo approccio è particolarmente vantaggioso in situazioni in cui i valori rimescolati non corrispondono a nomi propri americani, poiché permette un mascheramento dei dati più contestualmente appropriato.
Come funziona il rimescolamento dei nomi?
Il processo è semplice:
- Seleziona una colonna contenente nomi (nomi propri, cognomi, o entrambi).
- Riordina casualmente i valori all’interno di quella colonna.
- Sostituisci i valori originali con quelli rimescolati.
Questa tecnica mantiene inalterate la distribuzione e le caratteristiche dei dati originali. Tuttavia, interrompe la connessione tra le persone e le loro informazioni.
Implementare il rimescolamento dei nomi in R e Python
Esploriamo come implementare il rimescolamento dei nomi più semplice in due popolari linguaggi di programmazione: Python e R.
È importante notare che il livello di usabilità offerto da DataSunrise è senza pari in questo contesto. Creare una soluzione flessibile e tutto-in-uno con poche righe di codice non è fattibile utilizzando linguaggi di programmazione standard. Il nostro obiettivo qui è evidenziare le capacità di strumenti specializzati come DataSunrise rispetto ai linguaggi di programmazione generici.
Rimescolamento dei nomi in Python
Python offre modi semplici ed efficienti per mescolare i dati. Ecco un esempio che utilizza pandas, una potente libreria per la manipolazione dei dati:
import pandas as pd
import numpy as np
# Crea un dataset di esempio
data = pd.DataFrame({
'FirstName': ['John', 'Alice', 'Bob', 'Emma', 'David'],
'LastName': ['Smith', 'Johnson', 'Williams', 'Brown', 'Jones'],
'Age': [32, 28, 45, 36, 51],
'Salary': [50000, 60000, 75000, 65000, 80000]
})
# Rimescola la colonna FirstName
data['FirstName'] = np.random.permutation(data['FirstName'])
# Rimescola la colonna LastName
data['LastName'] = np.random.permutation(data['LastName'])
print(data)
Questo script crea un dataset di esempio e rimescola sia la colonna FirstName che LastName. Il risultato mantiene i nomi originali ma ne randomizza l’ordine, mascherando efficacemente le identità individuali.
Rimescolamento dei nomi in R
Anche R fornisce metodi semplici per il rimescolamento dei dati. Ecco un esempio:
# Crea un dataset di esempio
data <- data.frame(
FirstName = c("John", "Alice", "Bob", "Emma", "David"),
LastName = c("Smith", "Johnson", "Williams", "Brown", "Jones"),
Age = c(32, 28, 45, 36, 51),
Salary = c(50000, 60000, 75000, 65000, 80000)
)
# Rimescola la colonna FirstName
data$FirstName <- sample(data$FirstName)
# Rimescola la colonna LastName
data$LastName <- sample(data$LastName)
print(data)
Questo script in R ottiene lo stesso risultato dell’esempio in Python. Rimescola le colonne FirstName e LastName, mantenendo l’integrità dei dati mentre maschera le identità individuali.
Rimescolamento dei nomi: Vantaggi e Considerazioni
Il rimescolamento dei nomi è una tecnica popolare di anonimizzazione dei dati che sostituisce i nomi originali con alternative rimescolate per proteggere la privacy preservando l’utilità dei dati. Di seguito una panoramica dei suoi principali vantaggi e considerazioni:
| Vantaggio | Considerazione |
|---|---|
| Mantiene il realismo dei dati I valori rimescolati assomigliano al dataset originale, rendendo i dati utili per test e analisi. |
Rischi di Unicità Nomi rari o unici potrebbero comunque essere identificabili dopo il rimescolamento. |
| Mantiene la distribuzione dei dati I pattern di frequenza rimangono invariati, supportando l’integrità statistica. |
Coerenza tra le tabelle Assicurarsi che lo stesso nome venga mappato in modo coerente tra le tabelle correlate per evitare problemi referenziali. |
| Semplice da implementare Gli algoritmi di rimescolamento sono semplici e facili da applicare. |
Perdita contestuale Altri campi dati potrebbero comunque rivelare l’identità anche se i nomi sono rimescolati. |
| Opzionalmente reversibile Con una chiave o una tabella di mapping, il processo può essere invertito se necessario. |
Gestione della chiave richiesta La reversibilità introduce rischi se la chiave di rimescolamento o il mapping non viene conservato in modo sicuro o correttamente dismesso. |
Best practice per il rimescolamento dei nomi
Per massimizzare l’efficacia del rimescolamento dei nomi:
- Utilizza dataset di grandi dimensioni: più il dataset è grande, più il rimescolamento sarà efficace.
- Combina le tecniche: utilizza il rimescolamento dei nomi insieme ad altri metodi di mascheramento per una protezione migliore.
- Applicazione coerente: applica il rimescolamento in maniera coerente su tutti i dati correlati.
- Aggiornamenti regolari: rimescola periodicamente i dati per prevenire il reverse engineering.
Rimescolamento dei nomi nella creazione di dati di test
Il rimescolamento dei nomi è particolarmente prezioso nella creazione di dati di test. Consente a sviluppatori e tester di lavorare con dati realistici senza compromettere la privacy. Ecco perché è fondamentale:
- Test realistici: I nomi rimescolati mantengono le caratteristiche dei dati reali.
- Conformità alla privacy: Aiuta a soddisfare le normative sulla protezione dei dati.
- Sviluppo semplificato: Gli sviluppatori possono utilizzare dati che imitano da vicino gli ambienti di produzione.
Conclusione
Il rimescolamento dei nomi è una potente tecnica di mascheramento dei dati. Offre un equilibrio tra l’utilità dei dati e la protezione della privacy. Implementando il rimescolamento dei nomi, le organizzazioni possono creare dati di test realistici proteggendo al contempo le informazioni sensibili. Con l’aumentare delle preoccupazioni per la privacy dei dati, metodi come il rimescolamento diventeranno sempre più importanti nella gestione dei dati.
Per coloro che cercano soluzioni avanzate di mascheramento dei dati, DataSunrise offre strumenti flessibili e facili da usare per la sicurezza dei database. Il nostro completo strumento di mascheramento dei dati dinamico e statico include capacità robuste di rimescolamento e crittografia. Visita il sito web di DataSunrise per una demo online ed esplora come le nostre soluzioni possano migliorare le tue strategie di protezione dei dati.
