Offuscamento dei Dati in Vertica
L’offuscamento dei dati in Vertica è un approccio pratico per proteggere le informazioni sensibili mantenendo l’usabilità dei dataset analitici. Vertica è ampiamente adottata per analytics su larga scala, reporting e data science, dove sono essenziali alte prestazioni nelle query e accesso flessibile. Tuttavia, appena attributi sensibili come identificatori personali, dati finanziari o informazioni aziendali regolamentate compaiono nelle tabelle analitiche, la visibilità illimitata introduce rischi significativi di conformità e sicurezza.
A differenza della crittografia, che protegge i dati a riposo o in transito, l’offuscamento si focalizza sul controllo di ciò che gli utenti effettivamente vedono nei risultati delle query. Negli ambienti Vertica, dove le stesse tabelle servono più team e strumenti, l’offuscamento dei dati aiuta le organizzazioni a ridurre l’esposizione senza duplicare i dati o modificare le query esistenti. Di conseguenza, i team mantengono agilità analitica pur applicando una protezione coerente in linea con i principi della privacy dei dati.
Questo articolo spiega come l’offuscamento dei dati sia implementato in Vertica utilizzando controlli centralizzati, tecniche di mascheramento dinamico e auditing, con DataSunrise che agisce come livello di applicazione grazie alle sue capacità di Data Compliance.
Perché l’Offuscamento dei Dati è Importante in Vertica
L’architettura di Vertica è ottimizzata per il throughput analitico. L’archiviazione colonnare, gli strati ROS/WOS e l’esecuzione basata su proiezioni permettono un’elaborazione veloce di grandi dataset. Allo stesso tempo, queste caratteristiche rendono difficile applicare una protezione dei dati granulare utilizzando metodi tradizionali.
In pratica, diverse situazioni aumentano la necessità di offuscamento:
- Tabelle analitiche che combinano metriche con PII o dati di pagamento.
- Cluster Vertica condivisi accessibili da analisti, applicazioni e automazione.
- Query SQL esplorative che espongono più dati del previsto.
- Esportazioni a valle o report creati direttamente dai risultati grezzi delle query.
Il controllo d’accesso nativo basato sui ruoli di Vertica determina chi può eseguire query su una tabella. Tuttavia, non limita quali valori delle colonne compaiono nel set di risultati. Una volta eseguita la query, Vertica restituisce tutti i dati selezionati in forma chiara. Pertanto, l’offuscamento dei dati colma questa lacuna trasformando i valori sensibili prima che raggiungano il client, integrando i controlli d’accesso avanzati.
Per informazioni sul modello di esecuzione di Vertica, vedere la documentazione ufficiale Architettura di Vertica.
Architettura Centralizzata per l’Offuscamento in Vertica
Le organizzazioni generalmente implementano l’offuscamento dati in Vertica utilizzando un modello gateway centralizzato. In questa architettura, le applicazioni client si connettono attraverso un livello intermediario invece che direttamente al database. Tale livello ispeziona le query SQL, valuta le regole di protezione e applica l’offuscamento in modo coerente.
Molti team utilizzano DataSunrise Data Compliance per implementare questo modello. DataSunrise opera come un proxy trasparente davanti a Vertica, applicando le regole di offuscamento senza modificare schemi, proiezioni o logiche applicative. Inoltre, si integra con il monitoraggio dell’attività del database per fornire visibilità continua.
Di conseguenza, questo approccio consente:
- Offuscamento uniforme attraverso strumenti BI, script e servizi.
- Controllo basato su policy in base a utente, ruolo o contesto applicativo.
- Configurazione centralizzata con applicazione coerente.
- Auditing con impatto minimo sulle prestazioni di Vertica.
Mascheramento Dinamico come Tecnica di Offuscamento
Il mascheramento dinamico dei dati è la tecnica principale per l’offuscamento in Vertica. Invece di modificare permanentemente i dati memorizzati, il mascheramento dinamico riscrive i valori sensibili nei risultati delle query in fase di esecuzione. Nel contempo, Vertica continua a memorizzare e processare internamente i valori originali.
DataSunrise fornisce capacità integrate di mascheramento dinamico dei dati che valutano ogni query in base alle regole di policy. Queste regole possono considerare:
- L’utente o ruolo del database.
- L’applicazione client o il tipo di connessione.
- L’ambiente, come produzione o analisi.
- La classificazione di sensibilità delle singole colonne.
Poiché l’offuscamento avviene solo a livello di risultato, l’integrità analitica rimane intatta. Aggregazioni, join, filtri e calcoli operano ancora su valori reali internamente, mentre all’utente vengono restituiti dati mascherati. Questo approccio si allinea con più ampie strategie di sicurezza dei dati.
Configurazione delle Regole di Offuscamento in Vertica
Il primo passo per applicare l’offuscamento dati consiste nel definire una regola che miri all’istanza Vertica e identifichi quali dati debbano essere trasformati. Gli amministratori specificano gli schemi o le tabelle da proteggere e selezionano le colonne che necessitano di offuscamento.
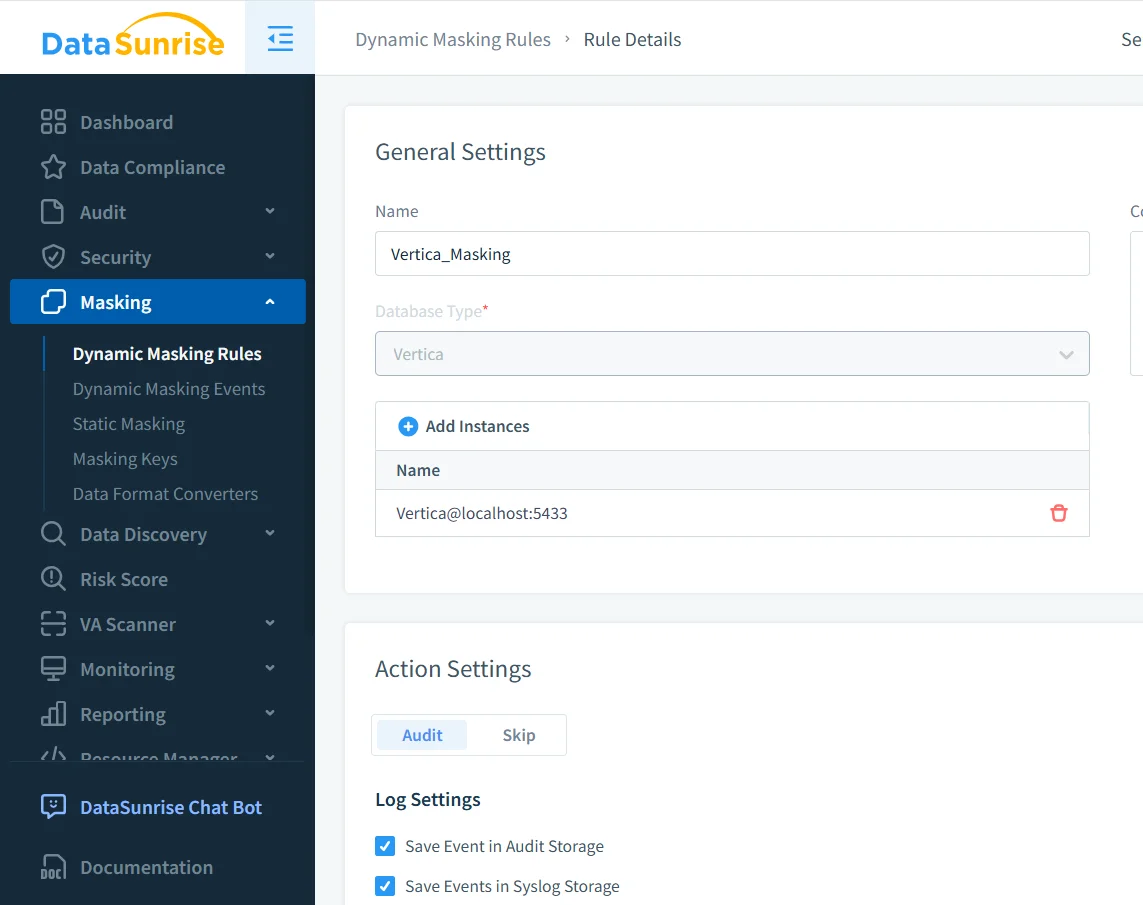
A questo punto, gli amministratori abilitano anche l’auditing per gli eventi di offuscamento. Di conseguenza, il sistema registra ogni trasformazione per verifiche di conformità e troubleshooting, integrandosi con i log di audit.
Una volta definita la regola, gli amministratori specificano quali colonne devono essere offuscate e in che modo. A seconda del caso d’uso, possono applicarsi formati diversi, come mascheramento parziale, sostituzione con token o anonimizzazione completa supportata da tecniche di data masking.
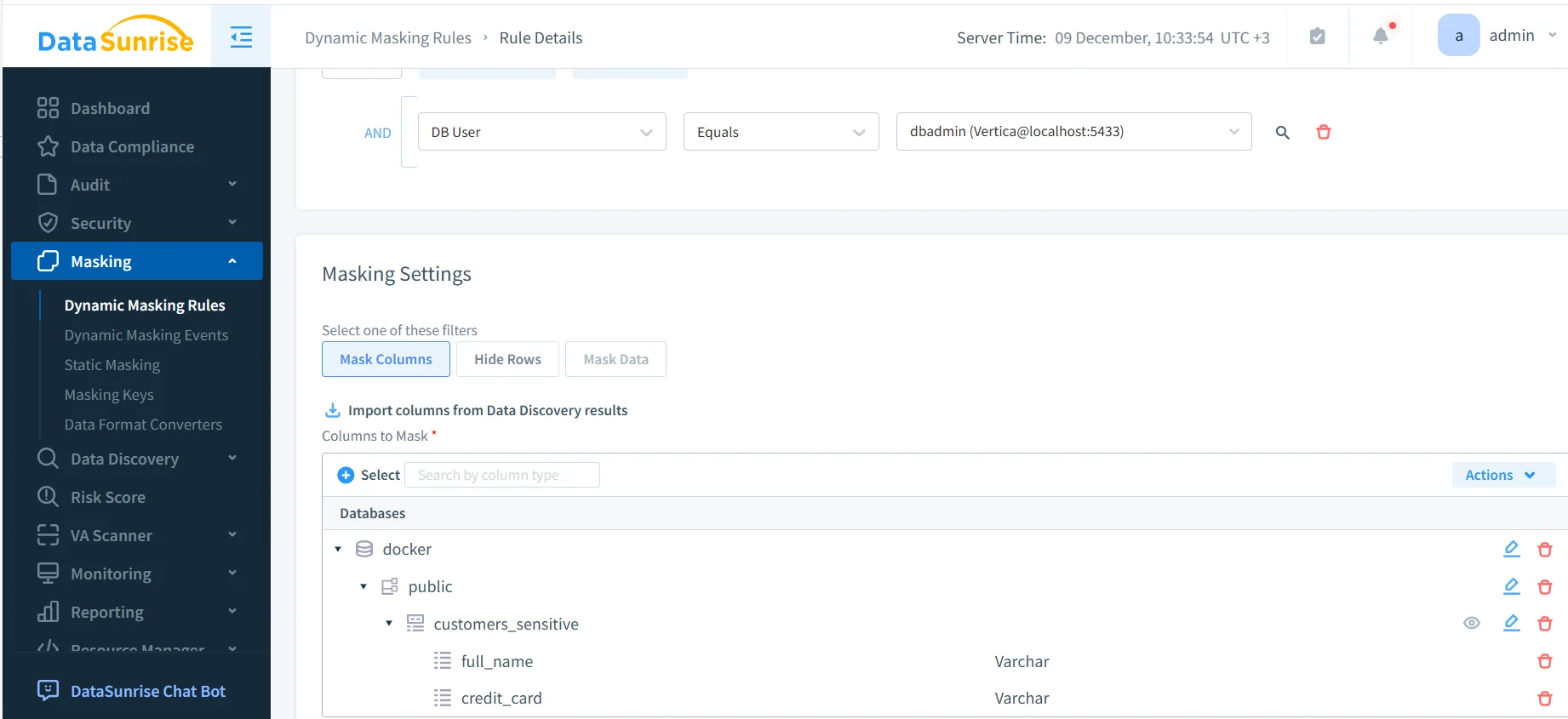
Risultati Offuscati nelle Query Analitiche
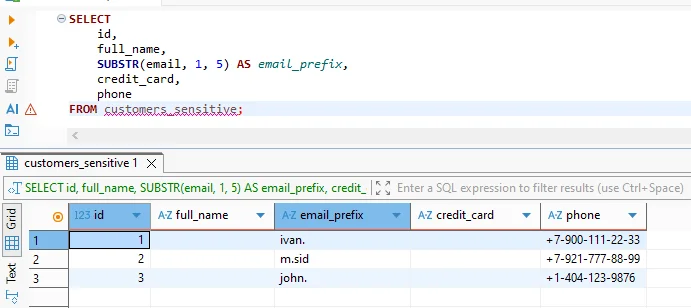
Dal punto di vista degli analisti e delle applicazioni, l’offuscamento dei dati è trasparente. Le query vengono scritte usando SQL standard e Vertica le esegue normalmente. Tuttavia, i valori restituiti riflettono la policy di offuscamento.
I risultati offuscati supportano ancora join, filtri, aggregazioni e raggruppamenti. Pertanto, la tecnica si adatta a dashboard BI, analisi esplorative e flussi di lavoro di feature engineering per machine learning regolati da regole di governance dei dati.
Poiché le policy seguono l’utente e il contesto di esecuzione, i team evitano di mantenere dataset separati o riscrivere report. Al contrario, le stesse tabelle Vertica servono in sicurezza più pubblici con differenti livelli di visibilità.
Auditing dell’Accesso ai Dati Offuscati
Un offuscamento efficace richiede visibilità. Le organizzazioni devono dimostrare quando i valori sensibili sono stati trasformati e chi ha avuto accesso ai dati.
DataSunrise registra automaticamente eventi di audit per ogni query offuscata, includendo:
- L’utente del database e l’applicazione client.
- La dichiarazione SQL eseguita.
- La regola di offuscamento applicata.
- Timestamp e contesto di esecuzione.
Questi record di audit si integrano con il Monitoraggio delle Attività del Database e supportano la conformità a regolamenti come GDPR, HIPAA e SOX. Alimentano inoltre i workflow di Compliance Manager.
Confronto tra Tecniche di Offuscamento dei Dati in Vertica
| Tecnica | Descrizione | Idoneità per Vertica |
|---|---|---|
| Offuscamento statico | Creazione di dataset offuscati permanentemente | Alta manutenzione, flessibilità limitata |
| Offuscamento basato su viste | Applicazione di trasformazioni tramite viste SQL | Facilmente aggirabile con accesso diretto |
| Offuscamento a livello applicativo | Logica di offuscamento in BI o applicazioni | Applicazione incoerente |
| Offuscamento dinamico | Riscrittura dei risultati in fase di query | Centralizzato e scalabile |
Best Practice per l’Offuscamento dei Dati in Vertica
- Identificare le colonne sensibili con scoperta automatizzata.
- Applicare l’offuscamento a livello di query invece di copiare i dati.
- Testare le regole con carichi analitici reali.
- Revisionare regolarmente i log di audit per accessi inattesi.
- Allineare le policy di offuscamento con più ampie strategie di sicurezza dei dati.
Conclusione
L’offuscamento dei dati in Vertica offre un modo flessibile e scalabile per proteggere le informazioni sensibili negli ambienti analitici. Applicando trasformazioni in modo dinamico al momento della query, le organizzazioni riducono il rischio di esposizione senza sacrificare prestazioni o usabilità.
Con DataSunrise che agisce come livello centralizzato di applicazione, Vertica rimane una piattaforma analitica potente mentre i dati sensibili restano protetti su dashboard, script e pipeline di machine learning.
