
Semplificare il Flusso di Dati
Per le aziende orientate ai dati, un’elaborazione efficiente dei dati è fondamentale per ottenere preziose intuizioni e prendere decisioni consapevoli. Tuttavia, quando si tratta di informazioni sensibili, è essenziale bilanciare velocità ed efficienza con la privacy e la sicurezza dei dati. Questo articolo esamina le modalità per semplificare i flussi di dati utilizzando metodi ETL ed ELT, proteggendo al contempo la privacy dei dati.
Comprendere gli Approcci per Semplificare l’Elaborazione dei Dati
Prima di approfondire ETL ed ELT, esaminiamo i comuni approcci per semplificare l’elaborazione dei dati:
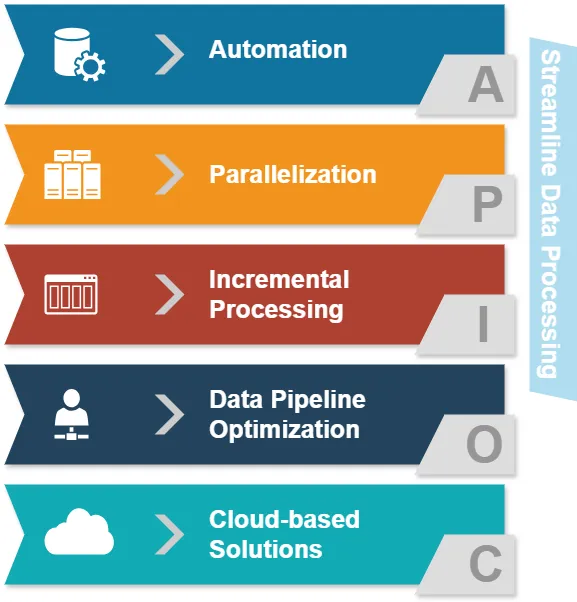
- Automazione: Ridurre le operazioni manuali nei compiti di elaborazione dei dati.
- Parallelizzazione: Elaborare simultaneamente più flussi di dati.
- Elaborazione incrementale: Aggiornare solo i dati modificati anziché l’intero dataset.
- Ottimizzazione della pipeline dei dati: Garantire un flusso di dati fluido tra le diverse fasi.
- Soluzioni basate su Cloud: Sfruttare infrastrutture scalabili per l’elaborazione dei dati.
Questi approcci mirano a migliorare l’efficienza nell’elaborazione dei dati. Ora, vediamo come ETL ed ELT si inseriscono in questo contesto.
ETL vs. ELT: Confronto in Sintesi
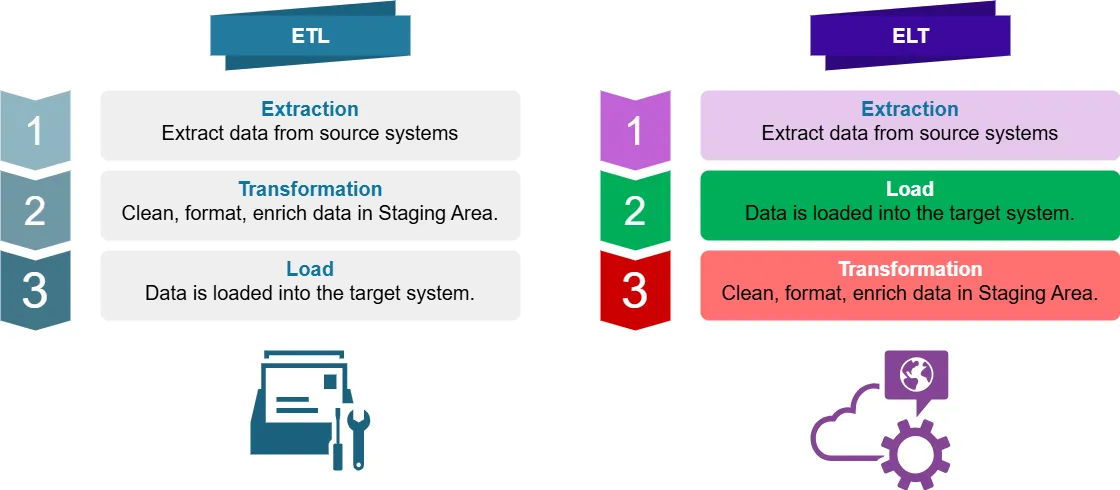
Che Cos’è ETL?
ETL sta per Extract, Transform, Load. È un processo tradizionale di data integration in cui i dati vengono:
- Estratti dai sistemi sorgente
- Trasformati (puliti, formattati, arricchiti) in un’area di staging
- Caricati nel sistema di destinazione (ad es., data warehouse)
Che Cos’è ELT?
ELT sta per Extract, Load, Transform. È un approccio moderno in cui i dati vengono:
- Estratti dai sistemi sorgente
- Caricati direttamente nel sistema di destinazione
- Trasformati all’interno del sistema di destinazione
Differenze Chiave nell’Elaborazione Ottimale dei Dati
Per l’intelligence aziendale, la principale differenza tra ETL ed ELT risiede nel luogo e nel momento in cui avviene la trasformazione dei dati. Ciò influenza l’elaborazione ottimale dei dati in diversi modi:
- Potenza di elaborazione: l’ETL si basa su server di trasformazione separati, mentre l’ELT sfrutta la potenza del sistema di destinazione.
- Flessibilità dei dati: l’ELT preserva i dati grezzi, consentendo trasformazioni più agili.
- Tempo di elaborazione: l’ELT può essere più rapido per dataset di grandi dimensioni grazie alla capacità di elaborazione parallela.
- Privacy dei dati: l’ETL può offrire un maggiore controllo sui dati sensibili durante la trasformazione.
Dove Si Applicano ETL ed ELT?
L’ETL è comunemente utilizzato in:
- Data warehousing tradizionale
- Sistemi con capacità di archiviazione o elaborazione limitate
- Scenari che richiedono trasformazioni complesse dei dati prima del caricamento
L’ELT è spesso preferito per:
- Data warehouse basati su Cloud
- Ambienti di Big Data
- Elaborazione dei dati in tempo reale o quasi in tempo reale
- Situazioni in cui la preservazione dei dati grezzi è fondamentale
Semplificare i Flussi di Dati: Esempi con Python e Pandas
Esaminiamo alcuni esempi di elaborazione dei dati semplificata e non semplificata utilizzando Python e Pandas.
Approccio Non Semplificato
import pandas as pd
# Leggere i dati dal CSV
df = pd.read_csv('large_dataset.csv')
# Eseguire molteplici trasformazioni
df['new_column'] = df['column_a'] + df['column_b']
df = df[df['category'] == 'important']
df['date'] = pd.to_datetime(df['date'])
# Scrivere i dati trasformati in un nuovo CSV
df.to_csv('transformed_data.csv', index=False)
Questo approccio legge l’intero dataset in memoria, esegue le trasformazioni e poi scrive il risultato. Per dataset di grandi dimensioni, questo può essere intensivo in termini di memoria e lento.
Approccio Semplificato
import pandas as pd
# Utilizzare chunk per elaborare dataset di grandi dimensioni
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
# Eseguire trasformazioni su ciascun chunk
chunk['new_column'] = chunk['column_a'] + chunk['column_b']
chunk = chunk[chunk['category'] == 'important']
chunk['date'] = pd.to_datetime(chunk['date'])
# Aggiungere il chunk trasformato al file di output
chunk.to_csv('transformed_data.csv', mode='a', header=False, index=False)
Questo approccio semplificato elabora i dati in chunk, riducendo l’utilizzo di memoria e consentendo l’elaborazione parallela. È più efficiente per dataset di grandi dimensioni e può essere facilmente integrato nei flussi di lavoro ETL o ELT.
Privacy dei Dati con ETL ed ELT
Quando si tratta di dati sensibili, la privacy è fondamentale. Sia ETL che ELT possono essere progettati per gestire in modo sicuro informazioni sensibili:
ETL e Privacy dei Dati
- Mascheramento Dinamico dei Dati: Applicare tecniche di mascheramento durante la fase di trasformazione.
- Crittografia: Crittografare i dati sensibili prima di caricarli nel sistema di destinazione.
- Controllo degli accessi: Implementare controlli di accesso rigorosi sul server di trasformazione.
Esempio di mascheramento dei dati in ETL:
import pandas as pd
def mask_sensitive_data(df):
df['email'] = df['email'].apply(lambda x: x.split('@')[0][:3] + '***@' + x.split('@')[1])
df['phone'] = df['phone'].apply(lambda x: '***-***-' + x[-4:])
return df
# Processo ETL
df = pd.read_csv('source_data.csv')
df = mask_sensitive_data(df)
# Ulteriori trasformazioni...
df.to_csv('masked_data.csv', index=False)
ELT e Privacy dei Dati
- Crittografia a livello di colonna: Crittografare le colonne sensibili prima del caricamento.
- Mascheramento Dinamico dei Dati: Applicare le regole di mascheramento nel sistema di destinazione.
- Controllo degli accessi basato sui ruoli: Implementare politiche di accesso dettagliate nel data warehouse.
Esempio di crittografia a livello di colonna in ELT:
import pandas as pd
from cryptography.fernet import Fernet
def encrypt_column(df, column_name, key):
f = Fernet(key)
df[column_name] = df[column_name].apply(lambda x: f.encrypt(x.encode()).decode())
return df
# Generare la chiave di crittografia (in pratica, conservare e gestire questa chiave in modo sicuro)
key = Fernet.generate_key()
# Processo ELT
df = pd.read_csv('source_data.csv')
df = encrypt_column(df, 'sensitive_column', key)
# Caricare i dati nel sistema di destinazione
df.to_sql('target_table', engine) # Supponendo che 'engine' sia la connessione al database
# Trasformare i dati all'interno del sistema di destinazione
Ottimizzare i Flussi di Dati per Dati Sensibili
Per semplificare i flussi di dati mantenendo la privacy dei dati, consideri le seguenti migliori pratiche:
- Classificazione dei dati: Identificare e categorizzare i dati sensibili nelle prime fasi del processo.
- Minimizzare lo spostamento dei dati: Ridurre il numero di trasferimenti dei dati sensibili tra i sistemi.
- Utilizzare protocolli sicuri: Impiegare la crittografia per i dati in transito e a riposo.
- Implementare la governance dei dati: Stabilire politiche chiare per la gestione e l’accesso ai dati.
- Audit regolari: Condurre revisioni periodiche dei flussi di lavoro di elaborazione dei dati.
Conclusione
È importante semplificare i flussi di dati. È altresì necessario garantire che le informazioni sensibili siano protette con misure di privacy robuste. Entrambi gli approcci ETL ed ELT presentano vantaggi unici e le organizzazioni possono ottimizzarli in termini di prestazioni e sicurezza.
Questo articolo discute le modalità con cui le organizzazioni possono creare flussi di dati sicuri. Questi flussi proteggono le informazioni sensibili e consentono di ottenere preziose intuizioni. Le organizzazioni possono utilizzare strategie e migliori pratiche per raggiungere tale obiettivo.
Ricordi che la scelta tra ETL ed ELT dipende dal caso d’uso specifico, dal volume dei dati e dai requisiti di privacy. È importante rivedere e aggiornare regolarmente le strategie di elaborazione dei dati. Ciò garantirà che esse siano in linea con le esigenze in evoluzione della Sua azienda e conformi alle leggi sulla protezione dei dati.
Per strumenti facili da usare che migliorano la sicurezza nel database e la conformità nei processi di dati, consulti le opzioni di DataSunrise. Visiti il nostro sito web su DataSunrise per vedere una demo e scoprire come possiamo migliorare l’elaborazione dei Suoi dati. Ci impegniamo a mantenere i Suoi dati sicuri e protetti.
