
Guida Completa al Mascheramento dei Dati per la Sicurezza e la Privacy nei Dataframe

Introduzione
Avrà incontrato i nostri articoli sul mascheramento dei dati dal punto di vista dell’archiviazione dei dati, dove abbiamo discusso tecniche di mascheramento statico, dinamico e in-loco. Tuttavia, la procedura di mascheramento nella scienza dei dati differisce leggermente. Mentre è ancora necessario mantenere la privacy e fornire protezione dei dati del dataframe, miriamo anche a derivare intuizioni basate sui dati. La sfida è mantenere i dati informativi garantendo al contempo la loro riservatezza.
Poiché le organizzazioni si affidano in gran parte alla scienza dei dati per intuizioni e decisioni, la necessità di tecniche di protezione dei dati robuste non è mai stata così grande. Questo articolo approfondisce l’argomento cruciale del mascheramento dei dati nei dataframes, esplorando come questa procedura protegga i dati sensibili mantenendo la loro utilità per l’analisi.
Comprendere il Mascheramento dei Dati nella Scienza dei Dati
Il mascheramento dei dati è un processo critico nel campo della protezione dei dati. Anche se non approfondiremo troppo i suoi aspetti generali, è essenziale comprendere il suo ruolo nella scienza dei dati.
Nel contesto della scienza dei dati, le tecniche di mascheramento svolgono un ruolo vitale nel preservare le caratteristiche statistiche dei dataset mentre nascondono le informazioni sensibili. Questo equilibrio è cruciale per mantenere l’utilità dei dati garantendo privacy e conformità con i requisiti normativi.
Mascheramento con Conservazione del Formato: Equilibrio tra Utilità e Privacy
Le tecniche di mascheramento con conservazione del formato sono particolarmente preziose nelle applicazioni di scienza dei dati. Questi metodi aiutano a mantenere i parametri statistici del dataset proteggendo efficacemente le informazioni sensibili. Preservando il formato e la distribuzione dei dati originali, i ricercatori e gli analisti possono lavorare con dataset mascherati che assomigliano da vicino ai dati autentici, garantendo la validità dei loro risultati senza comprometterne la privacy.
Che Cos’è un Dataframe?
Prima di entrare nelle procedure di mascheramento, chiarifichiamo cos’è un dataframe. Nella scienza dei dati, un dataframe è una struttura di dati etichettata bidimensionale con colonne di tipi potenzialmente diversi. È simile a un foglio di calcolo o a una tabella SQL ed è uno strumento fondamentale per la manipolazione e l’analisi dei dati in molti linguaggi di programmazione, in particolare in Python con librerie come Pandas.
Mascheramento dei Dati nei Dataframe
Quando si tratta di proteggere le informazioni sensibili nei dataframe, ci sono due approcci principali:
- Mascheramento durante la formazione del dataframe
- Applicazione di tecniche di mascheramento dopo la creazione del dataframe
Esploriamo entrambi i metodi nel dettaglio.
Mascheramento Durante la Formazione del Dataframe
Questo approccio implica l’applicazione di tecniche di mascheramento mentre i dati vengono caricati nel dataframe. È particolarmente utile quando si lavora con grandi dataset o quando si desidera garantire che i dati sensibili non entrino mai nel suo ambiente di lavoro in forma grezza.
Esempio: Mascheramento Durante l’Importazione di CSV
Ecco un semplice esempio con Python e pandas per mascherare i dati sensibili mentre si importa un file CSV:
import pandas as pd
import hashlib
def mask_sensitive_data(value):
return hashlib.md5(str(value).encode()).hexdigest()
# Lettura del file CSV con funzione di mascheramento applicata alla colonna 'ssn'
df = pd.read_csv('employee_data.csv', converters={'ssn': mask_sensitive_data})
print(df.head())
In questo esempio, stiamo usando una funzione hash per mascherare la colonna ‘ssn’ (Numero di Sicurezza Sociale) mentre i dati vengono letti nel dataframe. Il risultato sarà un dataframe dove la colonna ‘ssn’ contiene valori hash invece dei dati sensibili originali.
L’output del codice dovrebbe essere il seguente:
index nome età ssn stipendio dipartimento 0 Tim Hernandez 37 6d528… 144118.53 Marketing 1 Jeff Jones 29 5787e… 73994.32 IT 2 Nathan Watts 64 86975… 45936.64 Vendite …
Applicazione di Tecniche di Mascheramento dopo la Creazione del Dataframe
Questo metodo implica la ricerca e il mascheramento dei dati sensibili all’interno di un dataframe esistente. È utile quando è necessario lavorare inizialmente con i dati originali, ma si desidera proteggerli prima di condividere o memorizzare i risultati.
Esempio: Mascheramento delle Colonne di un Dataframe Esistente
Ecco un esempio di come mascherare colonne specifiche in un dataframe esistente:
import pandas as pd
import numpy as np
# Creare un dataframe di esempio
df = pd.DataFrame({
'nome': ['Alice', 'Bob', 'Charlie'],
'età': [25, 30, 35],
'ssn': ['123-45-6789', '987-65-4321', '456-78-9012']
})
# Funzione per mascherare SSN
def mask_ssn(ssn):
return 'XXX-XX-' + ssn[-4:]
# Applicare il mascheramento alla colonna 'ssn'
df['ssn'] = df['ssn'].apply(mask_ssn)
print(df)
Questo script crea un dataframe di esempio e quindi applica una funzione personalizzata di mascheramento alla colonna ‘ssn’. Il risultato è un dataframe dove sono visibili solo le ultime quattro cifre dell’SSN, mentre il resto è mascherato con caratteri ‘X’.
Questo output è il seguente:
nome età ssn
0 Alice 25 XXX-XX-6789
1 Bob 30 XXX-XX-4321
2 Charlie 35 XXX-XX-9012
Tecniche Avanzate di Mascheramento per i Dataframe
Man mano che approfondiamo la protezione dei dati del dataframe, è importante esplorare tecniche di mascheramento più sofisticate che possono essere applicate a vari tipi di dati e scenari.
Mascheramento dei Dati Numerici
Quando si lavora con dati numerici, preservare le proprietà statistiche durante il mascheramento può essere cruciale. Ecco un esempio di come aggiungere rumore ai dati numerici mantenendo la loro media e deviazione standard:
import pandas as pd
import numpy as np
# Creare un dataframe di esempio con dati numerici
df = pd.DataFrame({
'id': range(1, 1001),
'stipendio': np.random.normal(50000, 10000, 1000)
})
# Funzione per aggiungere rumore mantenendo la media e la dev.
def add_noise(column, noise_level=0.1):
noise = np.random.normal(0, column.std() * noise_level, len(column))
return column + noise
# Applicare rumore alla colonna stipendio
df['stipendio_mascherato'] = add_noise(df['stipendio'])
print("Statistiche originali dello stipendio:")
print(df['stipendio'].describe())
print("\nStatistiche dello stipendio mascherato:")
print(df['stipendio_mascherato'].describe())
Questo script crea un dataframe di esempio con dati di stipendio, quindi applica una funzione di aggiunta di rumore per mascherare gli stipendi. I dati mascherati risultanti mantengono proprietà statistiche simili a quelle originali, rendendoli utili per l’analisi proteggendo i valori individuali.
Nota che non ci sono grandi cambiamenti nei parametri statistici mentre i dati sensibili sono preservati poiché abbiamo aggiunto il rumore ai dati.
Statistiche originali dello stipendio: count 1000.000000 mean 49844.607421 std 9941.941468 min 18715.835478 25% 43327.385866 50% 49846.432943 75% 56462.098573 max 85107.367406 Name: stipendio, dtype: float64 Statistiche dello stipendio mascherato: count 1000.000000 mean 49831.697951 std 10035.846618 min 17616.814547 25% 43129.152589 50% 49558.566315 75% 56587.690976 max 83885.686201 Name: stipendio_mascherato, dtype: float64
Le distribuzioni normali ora appaiono così:
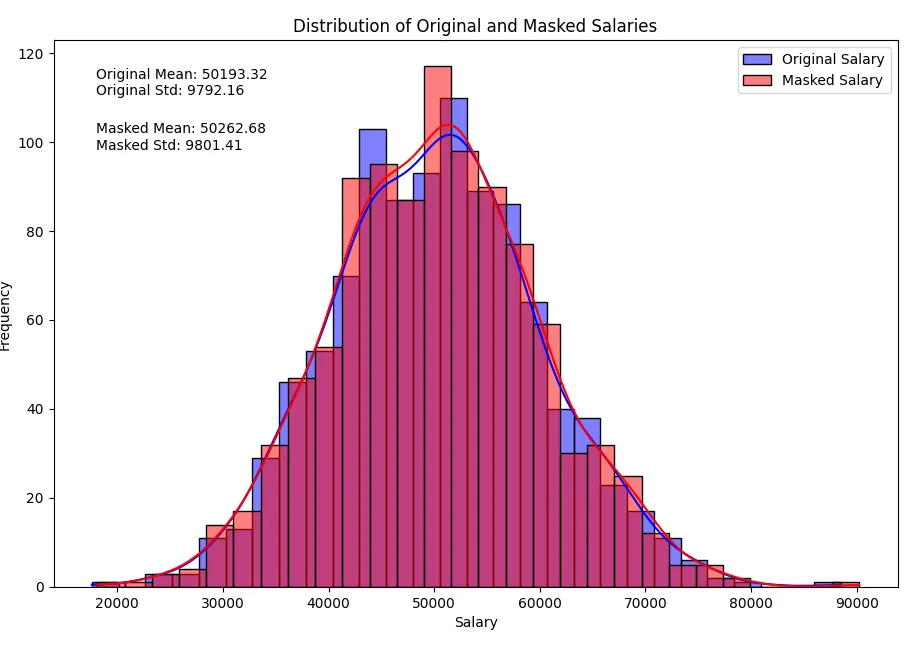
Mascheramento dei Dati Categoriali
Per i dati categoriali, potremmo voler preservare la distribuzione delle categorie mentre mascheriamo i valori individuali. Ecco un approccio utilizzando la mappatura dei valori:
import pandas as pd
import numpy as np
# Creare un dataframe di esempio con dati categoriali
df = pd.DataFrame({
'id': range(1, 1001),
'dipartimento': np.random.choice(['HR', 'IT', 'Vendite', 'Marketing'], 1000)
})
# Creare un dizionario di mappatura
dept_mapping = {
'HR': 'Dept A',
'IT': 'Dept B',
'Vendite': 'Dept C',
'Marketing': 'Dept D'
}
# Applicare mappatura per mascherare i nomi dei dipartimenti
df['dipartimento_mascherato'] = df['dipartimento'].map(dept_mapping)
print(df.head())
print("\nDistribuzione originale dei dipartimenti:")
print(df['dipartimento'].value_counts(normalize=True))
print("\nDistribuzione dei dipartimenti mascherata:")
print(df['dipartimento_mascherato'].value_counts(normalize=True))
Questo esempio dimostra come mascherare i dati categoriali (nomi dei dipartimenti) mantenendo la distribuzione originale delle categorie.
Se sfoglia i dati, potrebbero apparire come segue. Nota che le lunghezze delle barre sono uguali per i dati mascherati e non mascherati, mentre le etichette sono differenti.
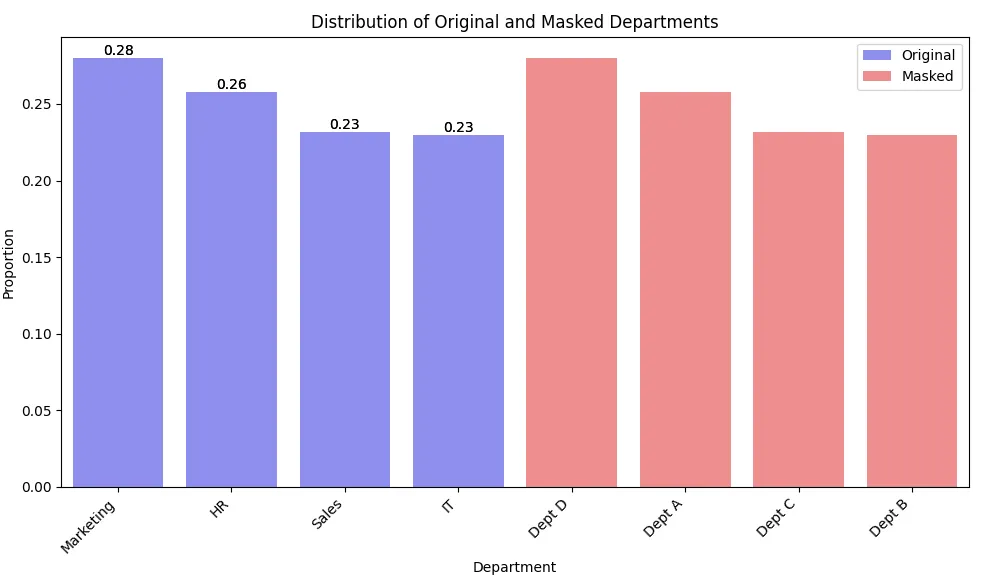
sfide nella Protezione dei Dati del Dataframe
Le procedure di mascheramento offrono strumenti potenti per proteggere i dati sensibili nei dataframe, ma presentano le proprie sfide:
- Mantenere l’Utilità dei Dati: Trovare il giusto equilibrio tra protezione dei dati e utilità per l’analisi può essere complesso.
- Coerenza tra i Dataset: Garantire che i valori mascherati siano coerenti tra più dataframe correlati o tabelle di database è cruciale per mantenere l’integrità dei dati.
- Impatto sulle Prestazioni: Alcuni metodi di mascheramento possono essere computazionalmente costosi, soprattutto per i grandi dataset.
- Reversibilità: In alcuni casi, potrebbe essere necessario smascherare i dati, che richiede una gestione scrupolosa delle chiavi o degli algoritmi di mascheramento.
Best Practices di Mascheramento dei Dati nella Scienza dei Dati
Per affrontare queste sfide ed assicurare un mascheramento efficace nei dataframe, consideri le seguenti best practices:
- Comprendere i Suoi Dati: Prima di applicare qualsiasi tecnica di mascheramento, analizzi a fondo i Suoi dati per comprendere la loro struttura, relazioni e livelli di sensibilità.
- Scegliere Tecniche Appropriate: Scelga metodi di mascheramento adatti ai Suoi tipi di dati specifici e requisiti di analisi.
- Preservare l’Integrità Referenziale: Quando maschera dataset correlati, assicuri che i valori mascherati mantengano le relazioni necessarie tra tabelle o dataframe.
- Audit Regolare: Revisiti e aggiorni periodicamente le Sue procedure di mascheramento per assicurarsi che soddisfino gli standard di protezione dei dati e le normative in evoluzione.
- Documentare il Suo Processo: Mantenga una documentazione chiara delle Sue procedure di mascheramento per la conformità e scopi di risoluzione dei problemi.
Conclusione
Il mascheramento dovrebbe preservare la proprietà dei dati di produrre intuizioni guidate dai dati. Il mascheramento dei dati nei dataframe è un aspetto critico della moderna scienza dei dati, bilanciando la necessità di un’analisi approfondita con l’imperativo della protezione dei dati. Comprendendo varie tecniche di mascheramento e applicandole in modo giudizioso, gli scienziati dei dati possono lavorare con informazioni sensibili mantenendo la privacy e la conformità.
Come abbiamo esplorato, ci sono due approcci al mascheramento dei dati nei dataframe, ciascuno con i propri punti di forza e considerazioni. Che Lei stia mascherando i dati durante l’importazione o applicando tecniche a dataframe esistenti, la chiave è scegliere metodi che preservino l’utilità dei Suoi dati proteggendo efficacemente le informazioni sensibili.
Ricordi, la protezione dei dati è un processo continuo. Man mano che le tecniche di scienza dei dati evolvono e emergono nuove sfide di privacy, restare informati e adattabili nel Suo approccio alla protezione dei dati del dataframe sarà cruciale.
