
Utilizzare lo Schema delle Informazioni di Redshift per Migliorare le Prestazioni del Database

Introduzione
Questo articolo approfondisce lo schema del database Redshift, concentrandosi specificamente sulla sua implementazione dello schema di informazioni. Esploreremo come si confronta con strumenti simili in altri sistemi di database, come Microsoft SQL Server e PostgreSQL. Alla fine di questa guida, avrà una solida comprensione di come sfruttare le tabelle di sistema di Redshift per ottimizzare le sue strategie di gestione dei dati.
Che Cos’è il Information Schema in MS SQL Server?
Prima di entrare nei dettagli di Redshift, iniziamo con un punto di riferimento familiare: lo schema delle informazioni di Microsoft SQL Server.
Comprendere le Basi
In MS SQL Server, lo schema delle informazioni è un insieme di viste che forniscono metadati sugli oggetti in un database. È un modo standardizzato per accedere alle informazioni su tabelle, colonne, viste e altri oggetti del database.
Per esempio, per visualizzare tutte le tabelle in un database utilizzando lo schema delle informazioni di MS SQL Server, potrebbe usare una query come questa:
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE';
Questa query restituirebbe un elenco di tutte le tabelle di base nel database corrente.
Schema del Database di Redshift: Strumenti di Informazione
Ora, rivolgiamoci a Redshift, un magazzino di dati su scala petabyte di Amazon Web Services. Sebbene Redshift sia basato su PostgreSQL, ha le sue tabelle di sistema e viste che servono uno scopo simile allo schema delle informazioni in altri sistemi di database.
Tabelle di Sistema in Redshift
Redshift fornisce un insieme di tabelle di sistema che memorizzano i metadati sui dati del cloud, le sue tabelle e altri oggetti. Queste tabelle di sistema sono prefissate con “PG_”, “STL_”, “STV_” o “SVV_”.
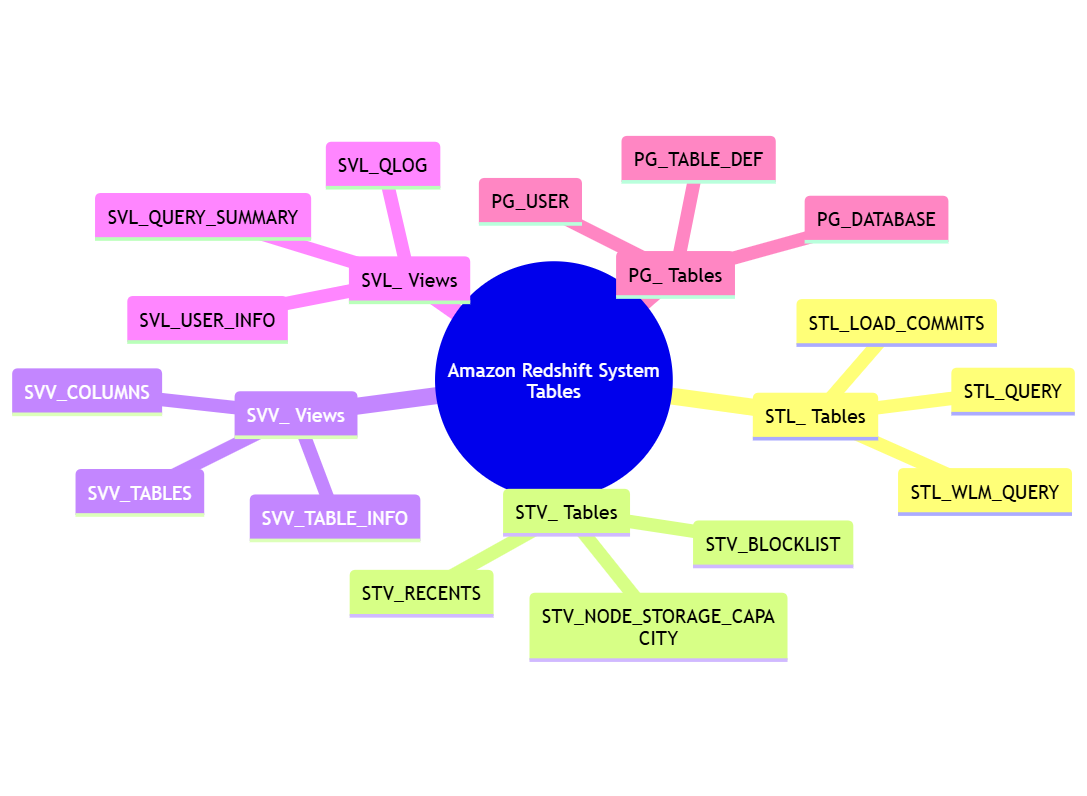
Ecco alcune delle principali tabelle di sistema in Redshift:
- PG_TABLE_DEF: Contiene informazioni sulle definizioni delle tabelle.
- SVV_COLUMNS: Fornisce una vista di tutte le colonne nel database.
- SVV_TABLES: Offre una vista di tutte le tabelle nel database.
Vediamo un esempio di come utilizzare queste tabelle:
SELECT tablename, "column", type, encoding FROM pg_table_def WHERE schemaname = 'public';
Questa query restituirà informazioni su tutte le colonne nelle tabelle all’interno dello schema ‘public’, inclusi i loro nomi, tipi di dati e codifiche.
Query dello Schema del Database di Redshift
Per ottenere una visione completa del suo schema di database Redshift, può utilizzare query che combinano informazioni da più tabelle di sistema. Ecco un esempio:
SELECT
n.nspname AS schema_name,
c.relname AS table_name,
a.attname AS column_name,
t.typname AS data_type
FROM
pg_catalog.pg_class c
JOIN
pg_catalog.pg_namespace n ON n.oid = c.relnamespace
JOIN
pg_catalog.pg_attribute a ON a.attrelid = c.oid
JOIN
pg_catalog.pg_type t ON t.oid = a.atttypid
WHERE
c.relkind = 'r' -- Solo tabelle regolari
AND n.nspname NOT IN ('pg_catalog', 'information_schema')
AND a.attnum > 0 -- Escludi colonne di sistema
ORDER BY
schema_name, table_name, a.attnum;
Questa query fornisce una vista dettagliata del suo schema di database Redshift, inclusi i nomi degli schemi, i nomi delle tabelle, i nomi delle colonne e i tipi di dati.
Confronto tra Redshift e Strumenti di Informazione di PostgreSQL
Dato che Redshift è basato su PostgreSQL, è naturale chiedersi quali siano le somiglianze e le differenze nei loro strumenti di schema informativo.
Information Schema di PostgreSQL
PostgreSQL, come MS SQL Server, ha un INFORMATION_SCHEMA che è conforme allo standard SQL. Fornisce viste che offrono informazioni su tutti gli oggetti del database.
Per esempio, per elencare tutte le tabelle in PostgreSQL, potrebbe usare:
SELECT table_name FROM information_schema.tables WHERE table_schema = 'public';
Redshift vs PostgreSQL
Sebbene Redshift sia basato su PostgreSQL, non include il standard INFORMATION_SCHEMA. Invece, fornisce le sue tabelle di sistema e viste. Questo è dovuto alla natura specializzata di Redshift come magazzino di dati colonnare, che richiede diversi strumenti di ottimizzazione e gestione.
Tuttavia, molti dei concetti sono simili. Per esempio, dove PostgreSQL ha information_schema.tables, Redshift ha SVV_TABLES. Entrambi forniscono metadati sulle tabelle nel database, ma i dettagli su quali informazioni sono disponibili e come vengono accessibili possono differire.
Utilizzare le Tabelle di Sistema di Redshift per Ottimizzare le Prestazioni
Comprendere le tabelle di sistema di Redshift può aiutare a ottimizzare le prestazioni del suo database. Esploriamo alcune applicazioni pratiche.
Identificare il Data Skew
Il data skew si verifica quando i dati sono distribuiti in modo disomogeneo tra i segmenti in Redshift. Questo può causare problemi di prestazioni. È possibile utilizzare le tabelle di sistema per identificare il data skew:
SELECT
trim(name) AS table,
slice,
count(*) AS num_values,
cast(100 * ratio_to_report(count(*)) over () AS decimal(5,2)) AS pct_of_total
FROM svv_diskusage
WHERE name IN ('your_table_name')
GROUP BY name, slice
ORDER BY name, slice;
Questa query mostra la distribuzione dei dati tra i segmenti per una tabella specifica, aiutando a identificare potenziali problemi di skew.
Monitorare le Prestazioni delle Query
Le tabelle STL_QUERY e SVL_QUERY_SUMMARY di Redshift possono aiutarla a monitorare le prestazioni delle query:
SELECT q.query, q.starttime, q.endtime, q.elapsed/1000000 AS elapsed_seconds, s.segment, s.step, s.maxtime/1000000 AS step_seconds, s.rows, s.bytes FROM stl_query q JOIN svl_query_summary s ON q.query = s.query WHERE q.starttime >= DATEADD(hour, -1, GETDATE()) ORDER BY q.query, s.segment, s.step;
Questa query fornisce informazioni dettagliate sulle query eseguite nell’ultima ora, inclusi il loro tempo di esecuzione e l’utilizzo delle risorse.
Best Practices per Utilizzare lo Schema delle Informazioni di Redshift
Per sfruttare al meglio le tabelle e le viste di sistema di Redshift, consideri le seguenti best practices:
- Monitori regolarmente le statistiche delle tabelle utilizzando SVV_TABLE_INFO per assicurarsi che le sue tabelle siano ottimizzate.
- Utilizzi STL_ALERT_EVENT_LOG per identificare e affrontare proattivamente i problemi di prestazioni.
- Faccia uso di SVV_VACUUM_PROGRESS per monitorare e gestire le operazioni di VACUUM.
- Utilizzi SVV_DATASHARE_OBJECTS per gestire la condivisione dei dati tra i cluster Redshift.
Ricordi, mentre queste tabelle di sistema forniscono preziose informazioni, interrogarle frequentemente può influire sulle prestazioni. Le utilizzi con giudizio e consideri di memorizzare i risultati in cache dove appropriato.
Conclusione
Comprendere e utilizzare efficacemente gli strumenti dello schema delle informazioni di Redshift è cruciale per gestire e ottimizzare il suo magazzino di dati. Sebbene differisca dallo standard INFORMATION_SCHEMA presente in SQL Server e PostgreSQL, le tabelle e le viste di sistema di Redshift offrono potenti capacità per monitorare, diagnosticare e ottimizzare il suo database.
Sfruttando questi strumenti, può ottenere approfondimenti significativi nel suo schema di database Redshift, monitorare le prestazioni e prendere decisioni informate sulla gestione dei dati e l’ottimizzazione delle query. Come con qualsiasi strumento potente, utilizzi queste capacità saggiamente per bilanciare la raccolta di informazioni con le prestazioni complessive del sistema.
Per chi cerca strumenti avanzati di sicurezza e conformità del database, consideri di esplorare DataSunrise. Le nostre soluzioni user-friendly e flessibili offrono una protezione completa del database. Visiti il nostro sito web per una demo online e scopra come può migliorare la sicurezza del suo database oggi.
