
Che Cos’è il Partizionamento?
Man mano che i database crescono in dimensioni e complessità, le prestazioni e la manutenibilità spesso ne risentono. Il partizionamento offre una soluzione suddividendo i grandi oggetti del database—come tabelle e indici—in segmenti più piccoli e gestibili. Questa tecnica è ampiamente utilizzata per accelerare l’esecuzione delle query, ridurre i costi di archiviazione e semplificare la gestione del ciclo di vita dei dati in sistemi aziendali e piattaforme basate su Cloud.
I principali vantaggi includono una migliore controllabilità, prestazioni e disponibilità. Questo approccio consente agli amministratori di ottimizzare e mantenere in modo indipendente le diverse parti del database, migliorando l’efficienza delle query e il tempo di attività del sistema, oltre a permettere strategie di gestione più mirate.
- In alcuni casi, questo metodo migliora le prestazioni quando si accede alle tabelle partizionate.
- Può anche definire colonne principali negli indici, riducendo la dimensione degli indici e aumentando l’efficienza dell’accesso alla memoria. Quando una grande parte di una sezione viene utilizzata nel set di risultati, la scansione di quella sezione risulta molto più veloce rispetto alla scansione di dati sparsi.
- Caricamenti e cancellazioni massivi sono possibili semplicemente aggiungendo o rimuovendo sezioni, migliorando così le prestazioni.
- Le informazioni raramente utilizzate possono essere spostate su sistemi di archiviazione a costi inferiori.
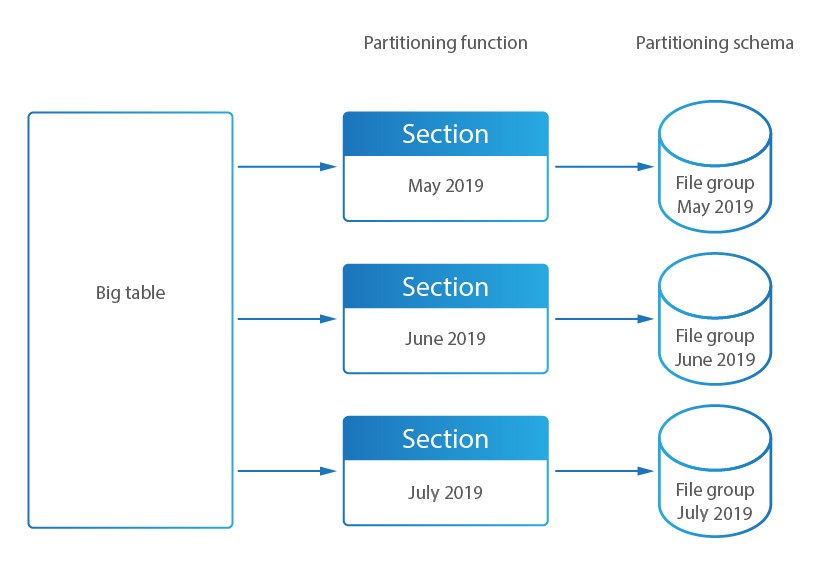
In DataSunrise, le grandi tabelle di Audit Storage sono suddivise in sezioni più piccole per migliorare l’accesso e le prestazioni. Il Database Activity Monitoring di DataSunrise memorizza i risultati direttamente in questo database interno.
- Gli amministratori possono gestire i dati più facilmente suddividendoli in segmenti basati sul tempo, che possono poi archiviare o escludere dalle query.
- La velocità di lettura/scrittura migliora notevolmente durante l’interazione con le tabelle di archiviazione.
- La cancellazione dei log di audit obsoleti diventa più rapida ed efficiente.
DataSunrise supporta questa tecnica per le seguenti piattaforme di database Audit Storage:
- PostgreSQL
- MySQL
- MS SQL Server
Parametri del Partizionamento
Può essere trovato in Impostazioni di Sistema -> Parametri aggiuntivi.
- Partitions Length (days) – Definisce la durata di ogni sezione (o minuti se AuditPartitionShort = 1). Si trova in Impostazioni di Sistema -> Audit Storage. Cambiare questo parametro ripristina la struttura: le sezioni esistenti vengono rimosse e sostituite con nuove.
- AuditPartitionCountCreatedInAdvance – Numero di partizioni preparate in anticipo. Questi slot vuoti consentono una scrittura dei dati senza interruzioni.
- AuditPartitionFirstEndDateTime – Specifica il limite superiore temporale della prima sezione. Utile per allineare le partizioni con un chiaro riferimento temporale (ad esempio, lunedì 00:00:00).
Partizionamento per Conformità e Conservazione
Molte normative in materia di dati richiedono la cancellazione o l’archiviazione tempestive dei dati sensibili. Il partizionamento rende più semplice la gestione del ciclo di vita dei dati isolando i record più vecchi in segmenti distinti. Ciò consente una cancellazione più rapida, un’archiviazione più agevole e una migliore preparazione all’audit, soprattutto in settori soggetti a politiche di conservazione rigorose, come sanità, finanza e telecomunicazioni.
Partizionamento in Ambienti Dati Moderni
In ambienti big data, la segmentazione dei dati è fondamentale. Molte piattaforme Cloud offrono ora opzioni di partizionamento automatico. AWS Redshift utilizza stili di distribuzione per un’ottimale organizzazione dei dati. Azure Synapse impiega metodi di distribuzione per migliorare le prestazioni delle query. La logica basata sul partizionamento funziona bene anche con data lake che gestiscono petabyte di informazioni. Essa consente query più rapide nelle applicazioni BI e supporta l’accesso basato sul tempo a dati storici o di archivio. Strategie appropriate aiutano a ridurre i costi di archiviazione e a conformarsi alle politiche di conservazione.
Strategie Efficaci per la Distribuzione dei Dati
La creazione di strategie efficaci per la distribuzione del database richiede una pianificazione attenta basata sui modelli di accesso e sui requisiti aziendali. L’organizzazione per intervalli funziona meglio per valori sequenziali come le date, permettendo ai team di accedere rapidamente ai dati recenti mentre archiviano le informazioni più vecchie.
La distribuzione per hash distribuisce i dati in modo uniforme su segmenti di archiviazione, ideale per il bilanciamento del carico in ambienti ad alta concorrenza. Gli approcci basati su liste organizzano i record per valori categorici specifici, rendendoli perfetti per la segmentazione geografica o dipartimentale.
Molte organizzazioni implementano metodi ibridi, combinando più tecniche di distribuzione per massimizzare i benefici in termini di prestazioni, minimizzando al contempo il carico di manutenzione. Un’analisi regolare di pruning garantisce che le query prendano di mira costantemente solo i segmenti di dati necessari, offrendo prestazioni ottimali man mano che i volumi di dati crescono.
Gestione del Partizionamento in DataSunrise
DataSunrise supporta la segmentazione automatica dei dati: crea le tabelle necessarie (per PostgreSQL), mantiene funzioni, schemi, filegroups e indici aggiornati (per MS SQL) e adatta le chiavi per conformarsi ai modelli di partizionamento nativi (per MySQL). DataSunrise gestisce l’intero ciclo di vita delle sezioni, dalla creazione alla pulizia.
Il sistema esegue SELECT tramite la tabella master, mentre indirizza gli INSERT/UPDATE verso sezioni specifiche (ad eccezione di MS SQL Server), migliorando così le prestazioni di scrittura.
Nomi delle Partizioni e delle Tabelle
PostgreSQL crea tabelle figlie come partizioni utilizzando il formato <table_name>_p<datetime>, dove <datetime> rappresenta il limite superiore nel formato YYYYMMDDhhmm.
MySQL utilizza meccanismi nativi per il partizionamento. Genera nomi di partizione utilizzando il formato p<datetime>, seguendo la stessa convenzione temporale.
MS SQL Server applica il partizionamento utilizzando un approccio basato su schemi anziché tabelle figlie.
