Come Applicare il Masking Statico in Apache Cloudberry
L’implementazione del masking statico per Apache Cloudberry è diventata essenziale per proteggere le informazioni sensibili negli ambienti non di produzione. Secondo una recente ricerca di IBM, il costo medio di una violazione dei dati ha raggiunto i 4,88 milioni di dollari nel 2024, rendendo le pratiche robuste di sicurezza dei dati più critiche che mai.
Apache Cloudberry, un database MPP open source basato su PostgreSQL, richiede strategie complete di protezione dei dati per tutelare le informazioni sensibili durante i flussi di lavoro di sviluppo e testing. Le organizzazioni possono sfruttare l’architettura di Cloudberry e le funzionalità di caricamento dati implementando tecniche di masking adeguate.
Questa guida fornisce passaggi pratici per implementare il masking statico mediante approcci nativi ed esplora come DataSunrise automatizza e potenzia la protezione dei dati negli ambienti Apache Cloudberry.
Comprendere il Masking Statico in Apache Cloudberry
Il masking statico dei dati crea una copia sanificata del database sostituendo permanentemente i dati sensibili con valori realistici ma fittizi. A differenza del masking dinamico, che maschera i dati in tempo reale, il masking statico trasforma fisicamente i dati in una istanza di database separata.
Questo approccio si rivela particolarmente prezioso per lo sviluppo e il testing con dataset realistici, per ambienti analitici che devono evitare l’esposizione di PII (informazioni personali identificabili), per la condivisione di dati con terze parti a scopo di test di integrazione e per sistemi di formazione che richiedono dati rappresentativi senza compromettere la privacy. Le organizzazioni che implementano il masking statico dovrebbero considerare anche strategie di gestione dei dati di test per massimizzarne l’efficacia.
Masking Statico Nativo in Apache Cloudberry
Apache Cloudberry eredita le capacità di manipolazione dati di PostgreSQL. Sebbene manchi di un masking statico integrato, è possibile implementare un masking efficace utilizzando le funzionalità native di PostgreSQL. Tuttavia, le organizzazioni devono essere consapevoli dei potenziali rischi di sicurezza quando si lavora con dati sensibili in ambienti non di produzione.
Prerequisiti
Prima di implementare il masking statico, assicurarsi di avere un’istanza Apache Cloudberry attiva con privilegi amministrativi, un database di destinazione separato per la copia mascherata e conoscenze SQL di base.
Passo 1: Implementare Funzioni di Masking
Creare funzioni personalizzate di masking per i tipi di dati più comuni:
-- Mascherare indirizzi email
CREATE OR REPLACE FUNCTION mask_email(email TEXT)
RETURNS TEXT AS $$
BEGIN
RETURN CASE WHEN email IS NULL THEN NULL
ELSE 'masked_' || md5(email)::text || '@example.com' END;
END;
$$ LANGUAGE plpgsql IMMUTABLE;
-- Mascherare carte di credito (mantenere prime 4 e ultime 4 cifre)
CREATE OR REPLACE FUNCTION mask_credit_card(card_number TEXT)
RETURNS TEXT AS $$
BEGIN
RETURN CASE WHEN card_number IS NULL THEN NULL
ELSE substring(card_number from 1 for 4) ||
repeat('*', length(card_number) - 8) ||
substring(card_number from length(card_number) - 3) END;
END;
$$ LANGUAGE plpgsql IMMUTABLE;
Passo 2: Copiare e Mascherare i Dati
-- Copiare e mascherare la tabella clienti
INSERT INTO cloudberry_masked.customer_data (
customer_id, email, credit_card
)
SELECT
customer_id,
mask_email(email),
mask_credit_card(credit_card)
FROM cloudberry_production.customer_data;
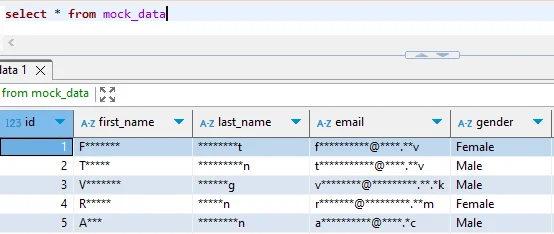
Passo 3: Verificare i Dati Mascherati
-- Confrontare dati originali e mascherati
SELECT customer_id, email FROM cloudberry_production.customer_data LIMIT 3;
SELECT customer_id, email FROM cloudberry_masked.customer_data LIMIT 3;
Limitazioni dell’Approccio Nativo
L’approccio nativo presenta diverse sfide per organizzazioni con requisiti avanzati. Il processo manuale richiede SQL personalizzato e dispendioso in termini di tempo per ogni tabella, mentre la mancanza di una scoperta automatizzata impedisce l’identificazione automatica dei dati sensibili attraverso gli schemi. Le funzioni di masking di base potrebbero non soddisfare le esigenze delle normative di conformità, e senza un audit trail completo, le organizzazioni non hanno tracciabilità delle operazioni di masking. Inoltre, le prestazioni possono degradare significativamente con grandi dataset distribuiti nell’architettura MPP di Cloudberry.
Masking Statico Avanzato con DataSunrise
DataSunrise offre un masking dei dati completo che potenzia significativamente le capacità native di Apache Cloudberry. La piattaforma implementa le migliori pratiche di sicurezza dei database offrendo funzionalità avanzate per la protezione dei dati sensibili.
Vantaggi Principali
- Scoperta Dati Automatica: identifica i dati sensibili secondo i framework GDPR, HIPAA e PCI DSS utilizzando tecniche avanzate di data discovery
- Molteplici Algoritmi di Masking: offre diversi tipi di masking tra cui randomizzazione, sostituzione e cifratura preservante il formato
- Masking In-Place Senza Codice: configura ed esegui il masking senza script SQL complessi grazie alla funzionalità In-Place Masking
- Integrità Referenziale: mantiene automaticamente le relazioni di chiavi esterne e le relazioni tra tabelle nei dati mascherati
- Audit Trail Completo: registra tutte le operazioni di masking per soddisfare i requisiti di compliance
- Supporto Multipiattaforma: applica politiche uniformi su oltre 40 piattaforme di database
Passaggi di Implementazione con DataSunrise
1. Connettere l’Istanza Apache Cloudberry
Collega il tuo database tramite l’interfaccia di DataSunrise utilizzando host, porta e credenziali di autenticazione.
2. Scoprire i Dati Sensibili
Accedi al modulo di Data Discovery, seleziona la tua istanza Apache Cloudberry, scegli i modelli regolatori (GDPR, HIPAA, PCI DSS) ed esegui la scansione per identificare automaticamente i dati sensibili.
3. Configurare le Regole di Masking
Seleziona il database o schema target, scegli gli algoritmi di masking appropriati per ogni tipo di dato, configura la preservazione dell’integrità referenziale e imposta le opzioni di consistenza del masking.
4. Eseguire il Masking In-Place
Seleziona i database di origine e destinazione, rivedi il piano di masking, esegui l’operazione e monitora i progressi in tempo reale tramite la dashboard DataSunrise.
5. Verificare i Risultati
DataSunrise fornisce report di validazione che mostrano record mascherati, algoritmi applicati e metriche di copertura compliance.
Best Practice per il Masking Statico in Apache Cloudberry
| Area di Pratica | Raccomandazione |
|---|---|
| Classificazione dei Dati | Identificare tutti i dati sensibili nell’intero cluster Cloudberry; prioritizzare in base ai requisiti normativi e all’impatto sul business; implementare controlli di accesso adeguati e documentare i flussi dei dati |
| Selezione degli Algoritmi | Utilizzare masking preservante il formato per la compatibilità applicativa; scegliere il masking deterministico per la coerenza o casuale per maggiore sicurezza; garantire che gli algoritmi rispettino i requisiti normativi e considerare la cifratura del database per protezioni aggiuntive |
| Ottimizzazione delle Prestazioni | Processare grandi tabelle in batch; sfruttare l’architettura MPP di Cloudberry per esecuzioni parallele; programmare il masking durante le ore di minor utilizzo per ridurre l’impatto |
| Sicurezza e Conformità | Mantenere log dettagliati delle attività di masking; limitare l’accesso tramite controlli di accesso basati sui ruoli (RBAC); stabilire programmi di aggiornamento regolari; validare la conformità tramite reporting automatizzato |
Conclusione
Sebbene la base PostgreSQL di Apache Cloudberry fornisca capacità di trasformazione di base, le implementazioni native richiedono uno sforzo manuale significativo e mancano di funzionalità enterprise. DataSunrise offre un masking completo tramite scoperta automatizzata, algoritmi intelligenti e gestione centralizzata delle policy.
Con varie opzioni di distribuzione che supportano ambienti cloud, on-premise e ibridi, DataSunrise fornisce la flessibilità necessaria per le architetture dati moderne.
Proteggi i tuoi dati con DataSunrise
Metti in sicurezza i tuoi dati su ogni livello con DataSunrise. Rileva le minacce in tempo reale con il Monitoraggio delle Attività, il Mascheramento dei Dati e il Firewall per Database. Applica la conformità dei dati, individua le informazioni sensibili e proteggi i carichi di lavoro attraverso oltre 50 integrazioni supportate per fonti dati cloud, on-premises e sistemi AI.
Inizia a proteggere oggi i tuoi dati critici
Richiedi una demo Scarica ora