Come Applicare il Mascheramento Statico in Percona Server
Il mascheramento statico in Percona Server per MySQL è un approccio pratico per proteggere informazioni sensibili prima che i dati lascino gli ambienti di produzione. Percona Server è ampiamente utilizzato per carichi di lavoro transazionali, pipeline di analisi e applicazioni rivolte ai clienti, che spesso memorizzano dati regolamentati come identificativi personali, dettagli di contatto e attributi finanziari. In questo contesto, il mascheramento statico agisce come un controllo fondamentale all’interno di strategie più ampie di sicurezza dei dati.
Una volta che i set di dati di produzione sono copiati in ambienti di sviluppo, test, analisi o supporto, i controlli di accesso tradizionali perdono efficacia. A quel punto, la trasformazione permanente dei dati diventa il modo più affidabile per prevenire esposizioni, preservando comunque l’integrità dello schema e la coerenza relazionale. Questo approccio supporta direttamente le moderne pratiche di sicurezza del database, dove la protezione deve persistere anche oltre i confini della produzione. Percona Server per MySQL stesso è comunemente scelto in questi scenari per via delle sue prestazioni e funzionalità enterprise, come descritto nella documentazione ufficiale di Percona Server.
Questo articolo spiega come applicare il mascheramento statico in Percona Server per MySQL utilizzando tecniche SQL native e come piattaforme centralizzate come DataSunrise estendono queste capacità con flussi di lavoro di mascheramento ripetibili basati su policy, allineati ai moderni requisiti di conformità dei dati.
Quando è Necessario il Mascheramento Statico in Percona Server per MySQL
Gli ambienti Percona spesso svolgono simultaneamente diversi scopi operativi. Una singola istanza di database può supportare il debug delle applicazioni, il controllo qualità e test di regressione, analisi aziendale, sperimentazioni di data science e indagini di supporto di routine. Sebbene queste attività si basino su schemi realistici e relazioni di dati, non richiedono l’accesso a valori personali o finanziari reali. In pratica, il mascheramento statico diventa un controllo chiave all’interno di strategie più ampie di sicurezza dei dati che mirano a ridurre le esposizioni non necessarie.
Una volta che i dati di produzione vengono riutilizzati al di fuori del loro ambiente originale, mantenere i valori originali introduce rischi significativi. Anche quando sono applicati permessi basati sui ruoli, i dataset copiati sono spesso accessibili a una platea più ampia di utenti e memorizzati in sistemi meno controllati. A questo punto, i soli controlli di accesso tradizionali non sono più sufficienti, motivo per cui il mascheramento statico viene comunemente applicato come parte di pratiche comprensive di sicurezza del database.
Il mascheramento statico diventa obbligatorio quando i dati di produzione sono replicati in ambienti non di produzione, condivisi con fornitori terzi o appaltatori, oppure usati per test e carichi di lavoro analitici senza una chiara necessità aziendale di valori reali. Inoltre, quadri normativi come GDPR, HIPAA e PCI DSS richiedono esplicitamente di minimizzare l’uso di dati sensibili reali al di fuori dei sistemi di produzione, allineando il mascheramento statico ai consolidati principi di compliance dei dati.
A differenza del mascheramento dinamico, il mascheramento statico sostituisce permanentemente i valori sensibili nel dataset. Questa trasformazione irreversibile assicura che anche in caso di fallimento dei controlli di accesso o di ulteriori copie dei dati, le informazioni originali non possano essere recuperate. Di conseguenza, il mascheramento statico integra altri meccanismi di protezione, incluso il mascheramento dinamico dei dati, eliminando i rischi di esposizione a livello stesso dei dati.
Tecniche Native di Mascheramento Statico in Percona Server per MySQL
Percona Server per MySQL non include un motore di mascheramento statico integrato. Di conseguenza, il mascheramento statico viene solitamente implementato tramite trasformazioni SQL esplicite eseguite sui dataset copiati negli ambienti non di produzione. Queste operazioni modificano i dati in modo permanente e sono tipicamente effettuate subito dopo la replicazione o l’esportazione.
Mascheramento Statico a Livello di Colonna con Istruzioni UPDATE
La tecnica di mascheramento statico più comune prevede di sovrascrivere colonne sensibili con valori deterministici o parzialmente offuscati. Questo approccio preserva la struttura dello schema e i tipi di dato rimuovendo il contenuto reale.
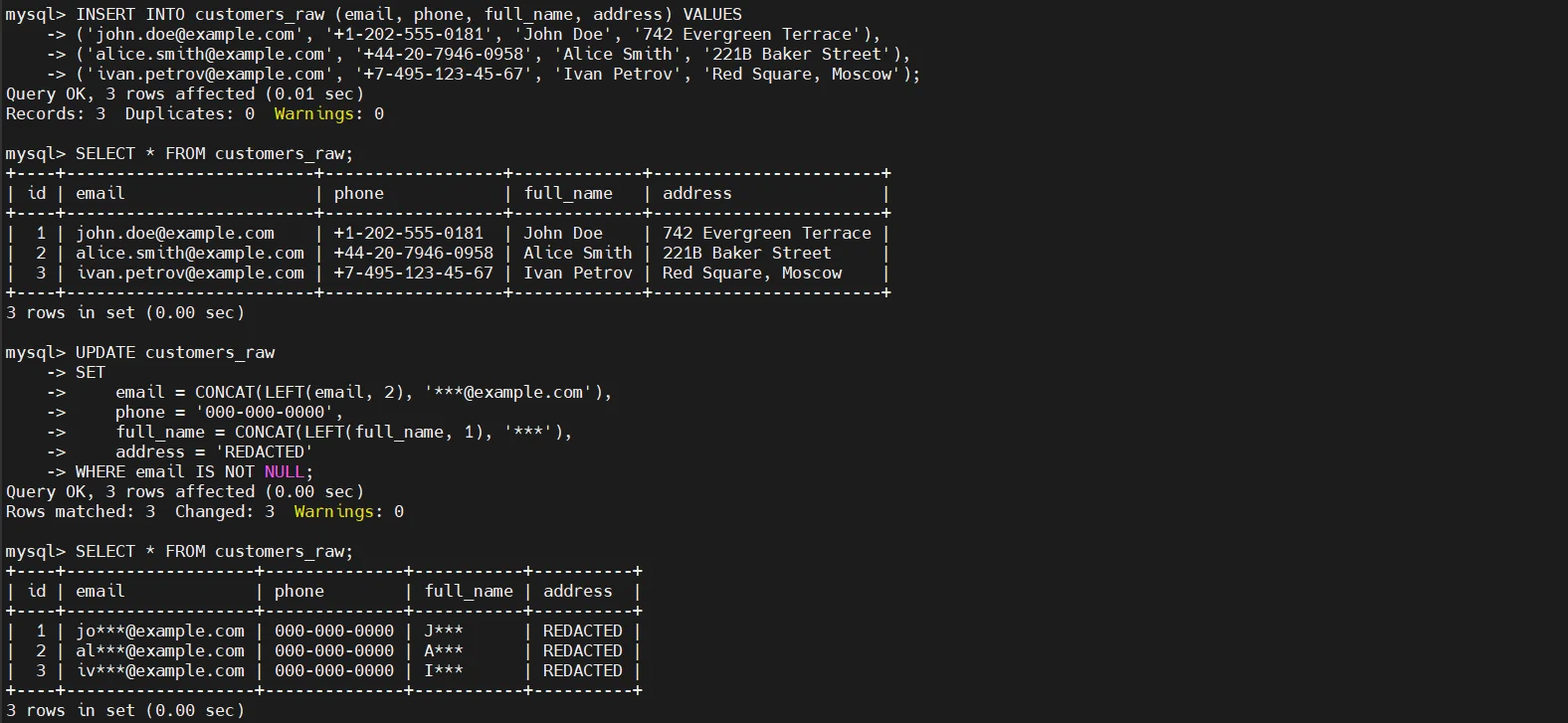
Questo metodo è semplice ed efficace, ma modifica permanentemente il dataset. Una volta eseguito, i valori originali non possono essere ripristinati, rendendo questo approccio adatto solo alle copie non di produzione.
Mascheramento Basato su Hash per Identificatori
Quando è necessario preservare l’unicità e l’integrità referenziale, l’hashing fornisce una tecnica affidabile di mascheramento statico. I valori hash rimangono coerenti tra le tabelle, consentendo join e confronti continui.
UPDATE users
SET
national_id = SHA2(national_id, 256),
passport_number = SHA2(passport_number, 256)
WHERE national_id IS NOT NULL;
Poiché l’hashing è unidirezionale, gli identificatori originali non possono essere ricostruiti, mentre la logica relazionale rimane intatta tra le tabelle dipendenti.
Mascheramento Randomizzato per Campi Numerici e Date
Per importi finanziari, metriche o timestamp, la randomizzazione entro intervalli controllati aiuta a mantenere distribuzioni realistiche dei dati senza esporre valori reali.
UPDATE payments
SET
amount = FLOOR(RAND() * 1000) + 10,
tax_amount = FLOOR(RAND() * 200),
payment_date = DATE_SUB(
CURDATE(),
INTERVAL FLOOR(RAND() * 365) DAY
),
settlement_date = DATE_ADD(
payment_date,
INTERVAL FLOOR(RAND() * 5) DAY
);
Questo approccio è comunemente utilizzato in ambienti di test e analisi, dove contano tendenze e distribuzioni, ma non i dati transazionali reali.
Considerazioni Pratiche
Pur offrendo flessibilità, il mascheramento statico basato su SQL nativo richiede un’attenta coordinazione. Le dipendenze tra tabelle devono essere gestite manualmente, la logica di mascheramento deve rimanere coerente tra ambienti e errori di esecuzione possono facilmente portare a dataset incompleti o danneggiati. Con l’aumentare dell’ambito di mascheramento, questi script diventano più difficili da mantenere e governare.
Mascheramento Statico Centralizzato per Percona Server per MySQL con DataSunrise
DataSunrise introduce un livello di sicurezza esterno e basato su policy che automatizza il mascheramento statico senza incorporare la logica di trasformazione in script SQL o oggetti di database. Invece di mantenere istruzioni UPDATE personalizzate o stored procedure, le regole di mascheramento sono definite centralmente ed eseguite in modo coerente tra ambienti. Questo assicura che la stessa logica di trasformazione sia applicata ogni volta che i dati di produzione sono preparati per l’uso non di produzione.
Esternalizzando la logica di mascheramento, questo approccio allinea il mascheramento statico a strategie più ampie di sicurezza dei dati e sicurezza del database, dove la protezione è applicata indipendentemente dal codice applicativo e dal design dello schema del database.
Scoperta e Classificazione dei Dati Sensibili
Prima di iniziare qualsiasi operazione di mascheramento, DataSunrise esegue automaticamente la scansione degli schemi di Percona Server per MySQL per identificare i dati sensibili. Il processo di scoperta rileva informazioni personalmente identificabili, attributi finanziari, credenziali e altri elementi regolamentati basandosi su pattern di contenuto reali piuttosto che solo su nomi di colonne o metadati. Questa capacità si basa su moderne tecniche di scoperta dei dati che focalizzano l’attenzione sul contenuto reale dei dati piuttosto che su assunzioni di schema.
Poiché la scoperta si basa sull’analisi del contenuto, rimane efficace anche in schemi poco documentati o con nomenclature incoerenti. Di conseguenza, i campi sensibili sono identificati con precisione prima dell’applicazione delle regole di mascheramento, riducendo il rischio di esposizione accidentale dei dati e rafforzando i controlli complessivi di sicurezza dei dati.
- Identificazione automatica di PII, dati finanziari e credenziali basata sul contenuto dei dati, allineata alle pratiche di protezione delle PII
- Indipendenza da convenzioni di nomenclatura delle colonne o qualità della documentazione dello schema
- Scoperta continua con l’evoluzione degli schemi nel tempo
- Rischio ridotto di omettere campi sensibili prima del mascheramento
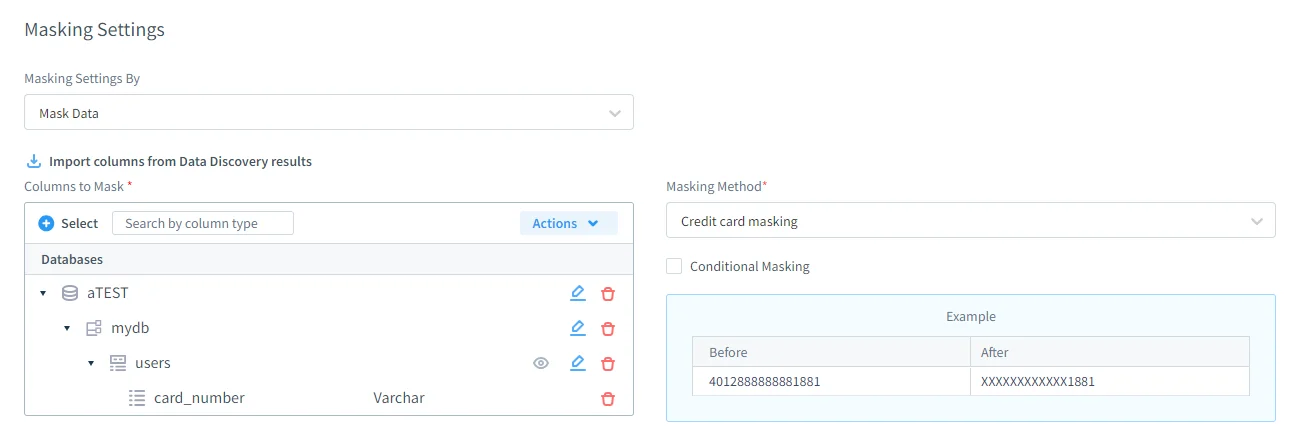
Definizione delle Regole di Mascheramento Statico
Le regole di mascheramento statico in DataSunrise offrono un controllo granulare su come i dati vengono trasformati. Gli amministratori possono definire con precisione quali database, schemi, tabelle e colonne sono soggetti a mascheramento, oltre a scegliere il metodo di mascheramento applicato a ciascun campo. Le tecniche supportate includono sostituzione, hashing, randomizzazione e azzeramento (nulling), seguendo i principi consolidati di mascheramento statico dei dati.
Importante, le regole di mascheramento possono preservare l’integrità referenziale tra tabelle correlate, assicurando che le relazioni con chiavi esterne rimangano valide dopo la trasformazione. Le regole sono riutilizzabili e controllate in versione, eliminando la necessità di script SQL una tantum e aiutando a mantenere coerenza tra più ambienti, sostenendo al contempo policies centralizzate di sicurezza del database.
- Definizione centralizzata delle regole across database e schemi
- Supporto per più tecniche di mascheramento per tipo di dato
- Preservazione dell’integrità referenziale tra tabelle correlate
- Regole versionate e riutilizzabili tra gli ambienti
Esecuzione dei Job di Mascheramento Statico
Una volta configurate, le regole di mascheramento vengono eseguite come parte di un processo operativo controllato piuttosto che come attività manuale. I job di mascheramento statico possono essere eseguiti on demand, programmati per l’esecuzione automatica, oppure integrati in pipeline di CI/CD e di provisioning dei dati. Questo modello operativo si allinea con più ampie pratiche di gestione dei dati di test utilizzate nei moderni workflow DevOps.
Di conseguenza, gli ambienti non di produzione ricevono dataset mascherati in modo coerente senza affidarsi a esecuzioni manuali di SQL o script ad-hoc, riducendo i rischi operativi e gli errori umani e migliorando l’efficienza nella gestione dei dati.
- Esecuzione on-demand per preparazioni ad-hoc dei dataset
- Mascheramento programmato per cicli di refresh ricorrenti
- Integrazione con workflow di CI/CD e provisioning dati
- Eliminazione di passaggi manuali basati su SQL
Auditabilità e Allineamento alla Compliance
Ogni operazione di mascheramento statico eseguita da DataSunrise viene registrata e tracciata. Questi log creano una storia chiara di quando il mascheramento è stato effettuato, quali regole sono state applicate e quali asset di dati sono stati interessati. Questo livello di visibilità supporta direttamente programmi strutturati di conformità dei dati.
Trasformando il mascheramento statico in un processo documentato e ripetibile, le organizzazioni si distanziano dalla gestione dei dati ad-hoc verso un workflow di compliance governato, in grado di reggere revisioni interne e audit esterni, integrando iniziative centralizzate di gestione della compliance.
- Tracciabilità completa delle operazioni di mascheramento e dell’uso delle regole
- Allineamento ai requisiti GDPR, HIPAA, PCI DSS e SOX
- Record pronti a fornire evidenze per audit e revisioni di compliance
- Transizione da mascheramento ad-hoc a processi di compliance governati
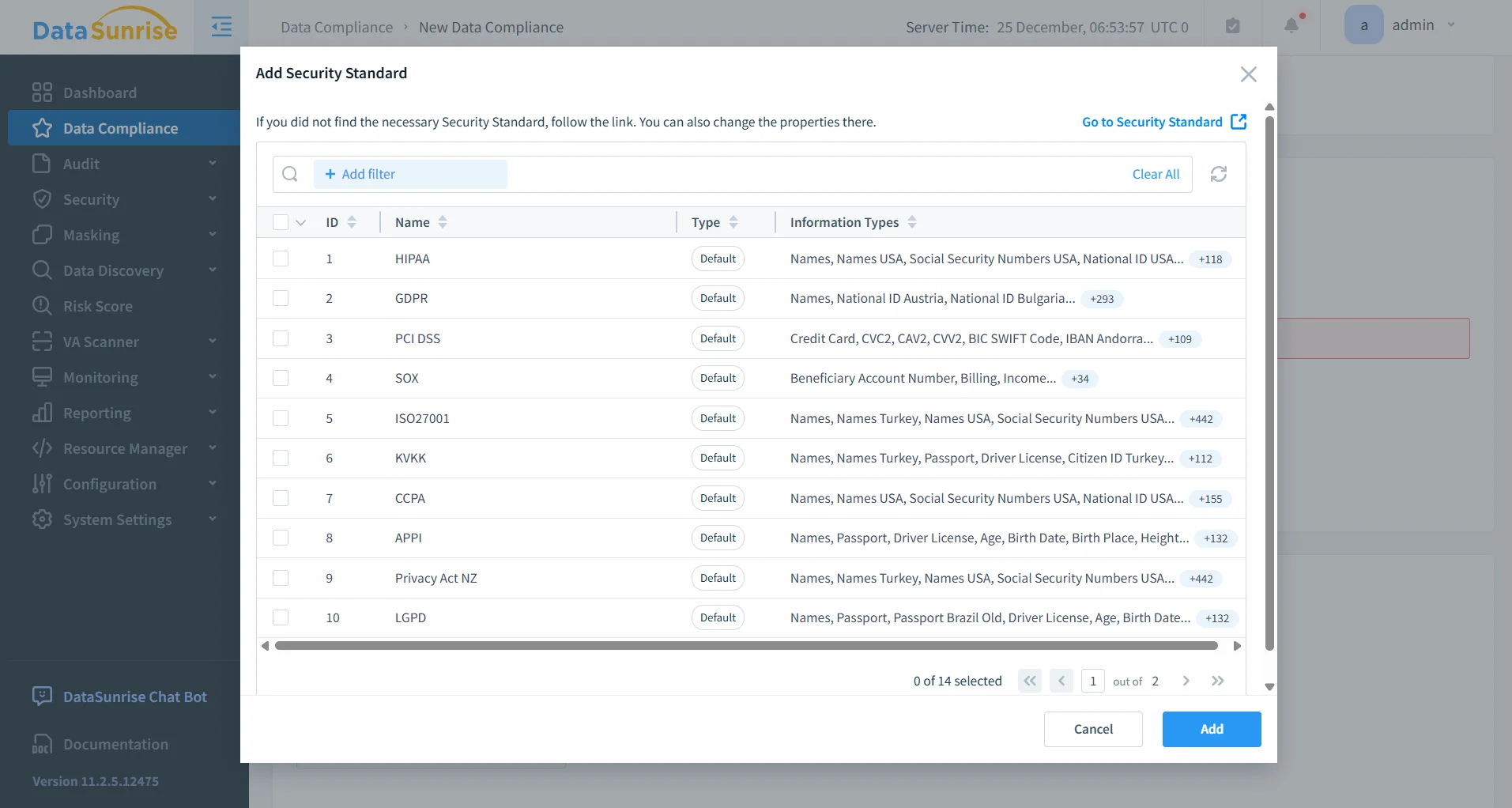
Impatto Aziendale del Mascheramento Statico in Percona Server per MySQL
| Area Aziendale | Impatto Operativo |
|---|---|
| Rischio di esposizione dei dati | Ridotta probabilità di fuga di dati sensibili fuori dagli ambienti di produzione |
| Provisioning dei dati di test | Creazione più rapida di dataset conformi per sviluppo, QA e analisi |
| Preparazione all’audit | Minor sforzo necessario per preparare evidenze per audit di sicurezza e compliance |
| Coerenza operativa | Regole di mascheramento uniformi applicate tra team e ambienti |
| Fiducia nella condivisione dei dati | Collaborazione più sicura con team interni e partner esterni |
Il mascheramento statico sposta il focus da una restrizione dell’accesso a abilitare un riutilizzo sicuro e controllato dei dati, rendendo i flussi di lavoro non di produzione sia più sicuri che più efficienti.
Conclusione
Percona Server per MySQL offre la flessibilità di implementare il mascheramento statico utilizzando tecniche SQL native. Questi metodi sono adatti a scenari piccoli e controllati dove è accettabile un’applicazione manuale e i requisiti base di mascheramento statico dei dati possono essere soddisfatti con script personalizzati.
Tuttavia, le organizzazioni che richiedono governance scalabile, coerenza tra ambienti e workflow di mascheramento pronti per audit traggono vantaggio da piattaforme centralizzate come DataSunrise. Formalizzando il mascheramento statico in policy strutturate anziché script fragili, la protezione dei dati sensibili diventa prevedibile, ripetibile e conforme per design, rafforzando la postura complessiva di sicurezza dei dati.
Il mascheramento statico cessa di essere un ripiego — e diventa un controllo operativo.
