Come Applicare il Masking Statico in Vertica
Il masking statico in Vertica è la tecnica principale descritta in questa guida su come applicare il masking statico in Vertica per proteggere i dati analitici sensibili al di fuori degli ambienti di produzione. Vertica supporta comunemente analisi su larga scala, reportistica e carichi di lavoro di data science. Di conseguenza, i dataset di produzione spesso includono informazioni personali, finanziarie o comunque soggette a regolamentazioni.
Tuttavia, una volta che i team copiano i dati di produzione in ambienti di sviluppo, test o analisi condivise, i tradizionali controlli di accesso perdono gran parte della loro efficacia. A quel punto, la trasformazione irreversibile dei dati diventa l’unico metodo affidabile per prevenire esposizioni, mantenendo comunque l’integrità dello schema e il valore analitico.
Questo articolo spiega come applicare il masking statico in Vertica utilizzando DataSunrise. Illustra la configurazione, l’esecuzione e la validazione attraverso screenshot reali dell’interfaccia, evidenziando anche considerazioni operative e di compliance.
Quando è Necessario il Masking Statico in Vertica
In pratica, gli ambienti Vertica servono molti utenti contemporaneamente. Analisti, sviluppatori, ingegneri QA e contrattisti esterni necessitano tutti di accedere a dataset realistici che rispecchiano le strutture di produzione.
Tuttavia, condividere dati di produzione non elaborati introduce rischi seri di sicurezza e conformità. Per questo motivo, il masking statico in Vertica diventa obbligatorio quando i dati sono:
- Copiati in ambienti di sviluppo o QA
- Condivisi con team esterni o fornitori di servizi
- Utilizzati per analisi al di fuori delle aree di produzione regolamentate
- Soggetti a regolamentazioni sulla privacy come il GDPR o l’HIPAA
A differenza dei controlli in runtime, il masking statico rimuove completamente i valori originali. Di conseguenza, le informazioni sensibili non esistono più in nessuna parte del dataset.
Limitazioni delle Tecniche Native di Masking in Vertica
Vertica non include una funzionalità integrata di masking statico. A causa di questa limitazione, i team spesso ricorrono a aggiornamenti SQL manuali, pipeline di esportazione o script personalizzati.
Inizialmente, questi approcci possono sembrare sufficienti. Nel tempo, però, introducono diversi problemi strutturali:
- Selezione manuale delle colonne che si rompe con l’evoluzione degli schemi
- Logiche di masking incoerenti tra gli ambienti
- Nessuna traccia di audit che dimostri che il masking è stato effettivamente eseguito
- Alto carico operativo durante i cicli di aggiornamento ricorrenti
Con l’aumento delle dimensioni dei dataset e la crescita della frequenza degli aggiornamenti, questi workaround diventano fragili. Alla fine, la governance si degrada e la prontezza agli audit ne risente.
Configurazione del Masking Statico in Vertica con DataSunrise
DataSunrise affronta queste limitazioni introducendo un’interfaccia centralizzata per definire e gestire i compiti di masking statico per Vertica. Invece di incorporare la logica di masking negli script SQL, DataSunrise applica il masking statico in Vertica esternamente, senza modificare gli schemi del database o il codice applicativo.
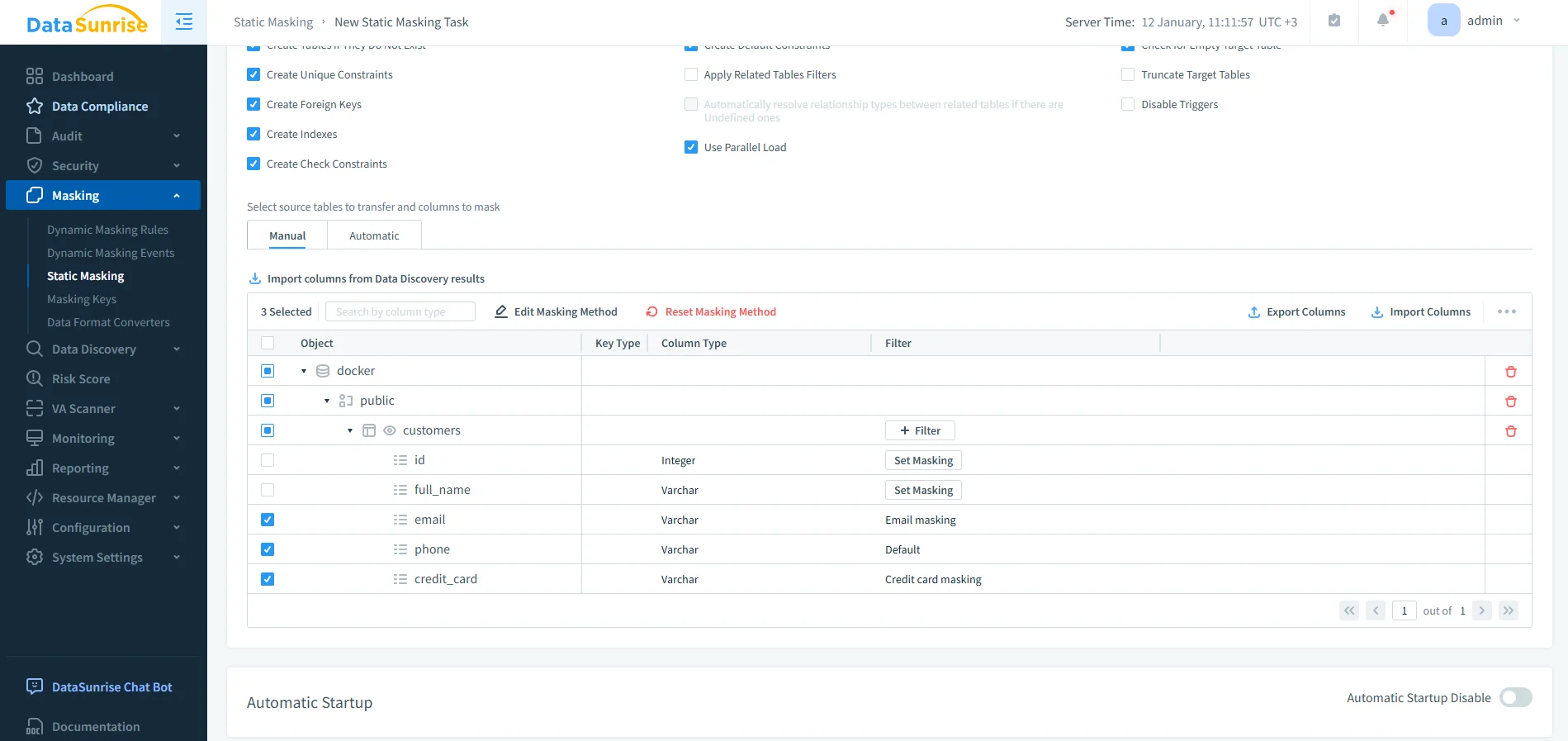
A questo punto, gli amministratori definiscono le istanze Vertica sorgente e destinazione, selezionano il database e lo schema, e scelgono quali tabelle e colonne necessitano di masking. DataSunrise mostra i campi sensibili come indirizzi email, numeri di telefono e dati delle carte di credito insieme ai metodi di masking predefiniti.
Selezione delle Colonne e dei Metodi di Masking in Vertica
Anziché affidarsi all’identificazione manuale, DataSunrise si integra con il data discovery per rilevare automaticamente i dati sensibili.
Al termine della scoperta, i team possono applicare in modo coerente i metodi di masking attraverso gli schemi. Le trasformazioni irreversibili più comuni includono:
- Sostituzione sintetica di email
- Tokenizzazione dei numeri di telefono
- Masking delle carte di credito con formato preservato
- Hashing irreversibile per identificatori
È importante sottolineare che queste trasformazioni preservano la struttura analitica pur eliminando completamente i valori reali.
Definizione delle Istanze Vertica Sorgente e Destinazione per il Masking Statico
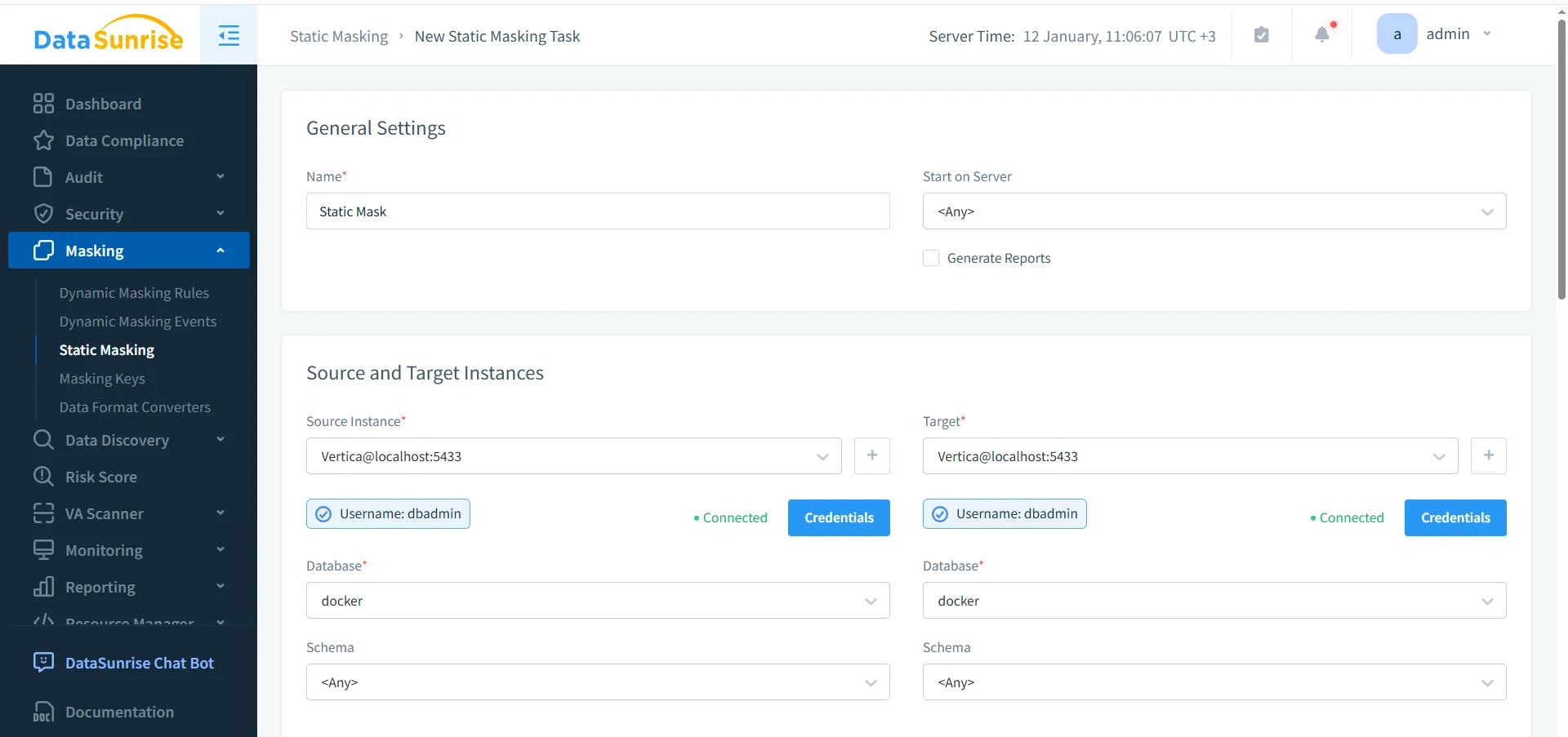
I compiti di masking statico richiedono sempre un’istanza sorgente e una destinazione. Nella maggior parte delle implementazioni, entrambe puntano allo stesso database Vertica. Tuttavia, il masking viene applicato a una copia aggiornata o a uno snapshot, non ai dati di produzione attivi.
Nel frattempo, DataSunrise memorizza in modo sicuro le credenziali e le riutilizza nelle varie procedure. Di conseguenza, le esecuzioni ripetute rimangono prevedibili e efficienti dal punto di vista operativo.
Esecuzione del Compito di Masking Statico in Vertica

Dopo la configurazione, gli amministratori eseguono il compito di masking statico come operazione controllata. Quando le prestazioni sono importanti, possono abilitare l’esecuzione parallela per accelerare l’elaborazione su grandi dataset Vertica.
Ogni esecuzione produce un indicatore di stato chiaro, durata di esecuzione e timestamp. Di conseguenza, i team possono confermare immediatamente che il masking statico in Vertica è stato completato con successo.
Validazione dei Risultati del Masking Statico in Vertica
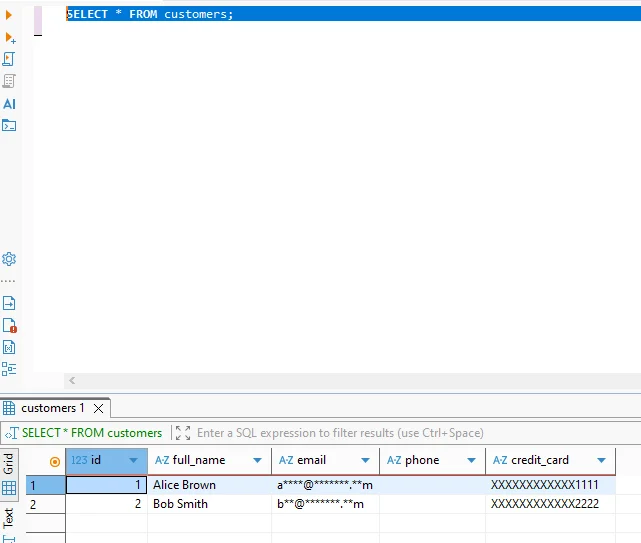
Una volta che il compito è completato, il sistema trasforma permanentemente i valori sensibili. Di conseguenza, anche gli utenti privilegiati ricevono dati mascherati nelle query.
La seguente query illustra come appaiono i dati mascherati in Vertica:
SELECT * FROM customers;
Poiché la trasformazione è irreversibile, i team possono riutilizzare in sicurezza il dataset per analisi, QA e condivisione esterna.
Impatto Operativo e di Conformità del Masking Statico in Vertica
| Area | Senza Masking Statico | Con Masking Statico |
|---|---|---|
| Rischio di esposizione dati | Alto quando i dati vengono copiati | Eliminato tramite trasformazione irreversibile |
| Preparazione all’audit | Raccolta manuale delle prove | Registrazioni automatiche delle attività e delle esecuzioni |
| Sforzo operativo | Basato su script e fragile | Centralizzato e ripetibile |
| Allineamento alla compliance | Difficile da dimostrare | Tracciabilità integrata |
Masking Statico vs Masking Dinamico in Vertica
Il masking statico e quello dinamico affrontano scenari di esposizione differenti.
Il masking statico dei dati modifica in modo permanente i valori memorizzati. Invece, il masking dinamico dei dati applica trasformazioni al momento della query.
Perciò, il masking statico in Vertica si adatta meglio quando i dati escono dagli ambienti di produzione o devono soddisfare requisiti di anonimizzazione irreversibile.
Conclusione: Fare del Masking Statico un Controllo Standard
Applicare il masking statico in Vertica non è una misura cosmetica di sicurezza. Serve invece come controllo fondamentale per proteggere i dati analitici una volta che escono dai confini di produzione.
Utilizzando DataSunrise, le organizzazioni centralizzano la logica di masking, riducono i rischi operativi e allineano le pratiche di gestione dati con le moderne normative di compliance sui dati.
Se il tuo ambiente Vertica supporta analisi al di là di un singolo team fiduciario, il masking statico dovrebbe già far parte del tuo workflow. Qualsiasi cosa di meno crea esposizioni non gestite.
