
Generazione di Dati Sintetici

La generazione di dati sintetici sta rapidamente diventando un elemento fondamentale dello sviluppo moderno di AI, dell’analisi avanzata e della trasformazione digitale guidata dalla privacy. Consente alle organizzazioni di creare dataset realistici e statisticamente accurati che rispecchiano informazioni del mondo reale—senza esporre dati autentici di clienti o aziendali. Questo approccio supporta sperimentazioni sicure, addestramento di machine learning e validazione di modelli, restando conforme a regolamenti sulla privacy consolidati come GDPR, HIPAA e CCPA. Secondo un recente rapporto Gartner, quasi la metà degli executive a livello globale ha incrementato la spesa per AI, sottolineando la crescente necessità di un uso responsabile e sicuro dei dati. Ulteriori indicazioni dal NIST AI Risk Management Framework evidenziano il ruolo dei dati sintetici nella riduzione del bias e nel supporto allo sviluppo di modelli più sicuri. Funzionalità quali il dynamic data masking migliorano ulteriormente la capacità di un’organizzazione di tutelare le informazioni sensibili durante l’intero processo.
DataSunrise posiziona i dati sintetici come una naturale evoluzione della protezione dei dati—a complemento di metodi esistenti come il data masking, la crittografia e il monitoraggio delle attività del database. Questa funzionalità consente alle organizzazioni di generare dataset totalmente anonimizzati e di qualità produzione che mantengono la struttura, le relazioni e i pattern statistici dei dati reali. Di conseguenza, i team possono eseguire test, analisi e sviluppo in ambienti sicuri e controllati senza violare le normative sulla privacy o i requisiti regolatori. I dataset sintetici supportano la collaborazione sicura, accelerano l’innovazione e garantiscono la conformità in ogni fase del ciclo di vita dell’AI.
Associati ad automazione e controlli intelligenti delle policy, i dati sintetici non solo migliorano la protezione dei dati e la conformità normativa, ma potenziano anche scalabilità, agilità operativa e continuità. Permettono alle imprese di adottare AI e analisi all’interno di ecosistemi sicuri ed eticamente governati—sbloccando l’innovazione mantenendo fiducia e allineamento regolatorio.
Cos’è il Dato Sintetico?
I dati sintetici si riferiscono a informazioni create artificialmente che riflettono la struttura e il comportamento statistico di dataset reali senza mantenere valori autentici. Conservano formati, relazioni e distribuzioni, consentendo ai team di sviluppare, testare e analizzare in modo sicuro. Poiché non vengono utilizzati record genuini, i dataset sintetici eliminano i rischi legati alla privacy restando altamente efficaci per la modellazione AI, la validazione di sistemi e gli sforzi di conformità.
Quando Usare Dati Sintetici vs. Masking
Il masking statico o dinamico è utile quando è necessario mantenere la struttura e la logica dei dati di produzione—ma si vuole comunque fare riferimento a valori reali. Tuttavia, il masking non può essere condiviso esternamente se lo schema di origine o i metadati creano rischio di re-identificazione.
I dati sintetici sono preferibili quando:
- È necessario simulare grandi dataset senza alcun collegamento a persone reali
- La conformità richiede zero esposizione ai valori di produzione
- Si lavora con log non strutturati o si addestrano LLM
Scenario: Perché i Dati Sintetici Superano il Masking
Immagina un team di data science che addestra un modello per il rilevamento di anomalie. I dati di produzione mascherati preservano la struttura, ma correlazioni residue possono ancora creare rischio di re-identificazione. I dataset sintetici, al contrario, non hanno alcun legame con clienti reali. Il team ottiene dati statisticamente fedeli per pipeline AI, mentre gli officer della compliance hanno la certezza che nessun dato identificabile esca mai dall’ambiente di produzione.
I dati sintetici non sono solo uno strumento per sviluppatori—sono un acceleratore di compliance. Generando record privacy-safe, le imprese riducono i rischi regolatori, accelerano l’adozione di AI e abilitano collaborazioni sicure con vendor.
Abbinati al masking, i dati sintetici creano un modello ibrido: si mantiene l’integrità referenziale per i flussi di lavoro che la richiedono e si generano record completamente artificiali per test, condivisione o addestramento AI. Questo approccio misto garantisce la conformità senza rallentare l’innovazione.
Dati Sintetici — Sintesi, Passi, Validazione
Sintesi
- Obiettivo: creare dataset privacy-safe che preservano schema e proprietà statistiche senza esporre dati reali.
- Quando usarlo: condivisione esterna, addestramento LLM/ML, provisioning non-prod, o politiche che richiedono zero collegamento con individui.
- Abbinamenti: combinare con masking per flussi ibridi che necessitano integrità referenziale in ambiti limitati.
Passaggi di Implementazione
- Definire ambito e scopo (QA, analytics, training LLM, condivisione vendor).
- Catalogare schemi, vincoli e campi sensibili (PII/PHI/PCI) per guidare i generatori.
- Selezionare modalità di generazione (built-in/policy-aware in piattaforma, o OSS come SDV/CTGAN/Mockaroo per prototipi).
- Scegliere strategie per colonne (sostituzione, modelli statistici, FPE dove la forma è importante).
- Preservare relazioni (chiavi/foreign key) o simulare con regole deterministiche se necessario.
- Eseguire un pilota su un sottoinsieme; registrare parametri per replicabilità.
- Validare qualità (distribuzione, correlazioni, distanza privacy); regolare i generatori.
- Pianificare lavori; registrare attività e controllare accessi secondo policy di governance.
Checklist di Validazione
| Verifica | Cosa Controllare | Note |
|---|---|---|
| Distribuzione | Media/varianza, percentili nei limiti di tolleranza | Test KS per colonna numerica |
| Correlazioni | Correlazioni chiave a coppie preservate (±Δ) | Confronto matrici di correlazione |
| Privacy | Nessuna riga sintetica troppo vicina a campioni reali | Distanza nearest-neighbor |
| Vincoli | Unicità, formati, domini rispettati | Controlli con regex/intervalli |
Controlli Rapidi
- Documentare generatori, semi e regole per replicabilità.
- Mantenere dataset sintetici e reali separati; vietare join tra loro.
- Per test UI/integrativi con integrità referenziale rigorosa, considerare un approccio ibrido (base mascherata + espansioni sintetiche).
- Applicare gli stessi controlli di accesso e politiche di retention ai dataset sintetici usati esternamente.
Casi d’Uso di Dati Sintetici DataSunrise
| Caso d’Uso | Descrizione | Esempio |
|---|---|---|
| Test di Compliance | Simulare dataset reali per validare logiche senza usare dati di clienti reali. | Eseguire algoritmi di rilevamento frodi su transazioni bancarie generate. |
| Addestramento AI & ML | Addestrare modelli su dataset realistici ma non identificabili per evitare violazioni regolatorie. | Costruire modelli diagnostici da cartelle cliniche sintetiche. |
| Staging & QA | Popolare ambienti di test con dati realistici per test UI, carico o integrazione. | Riempire cluster dev PostgreSQL con profili utente sintetici. |
| Collaborazione Sicura | Condividere dataset sintetici tra team o con partner senza esporre informazioni sensibili. | Fornire record HR sintetici a un vendor di analisi terzo. |
Cosa Rende Diversi i Dati Sintetici DataSunrise?
Sebbene molte piattaforme offrano generazione di dati artificiali, poche la integrano direttamente in pipeline di sicurezza e conformità enterprise-grade. Gli strumenti DataSunrise per dati sintetici sono strettamente integrati con masking, auditing e enforcement delle policy—rendendoli ideali per utilizzi reali in ambienti regolamentati.
- Fallback integrato con masking: Passaggio fluido tra masking e generazione in base al contesto di accesso o al tipo di schema.
- Generazione policy-aware: Definizione di regole di generazione allineate con filtri di conformità esistenti e tag di dati sensibili.
- Flussi di lavoro schedulati: Automazione della creazione di dataset sintetici across ambienti, applicazioni e pipeline CI/CD.
- Audit logging: Tracciamento di ogni attività di generazione per completa tracciabilità e prontezza all’audit.
Che tu stia testando app interne o addestrando modelli AI, DataSunrise Synthetic Data offre ai team la flessibilità di simulare carichi di lavoro simili a quelli di produzione—senza rischiare i dati reali.
Come Configurare la Generazione di Dati Sintetici in DataSunrise
Passo 1: Impostare i Parametri Generali
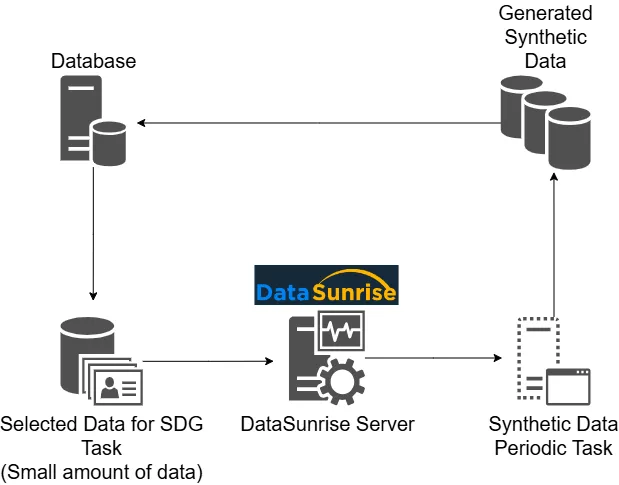
Vai su Configurazione → Attività Periodiche e crea una nuova attività. Seleziona “Generazione di Dati Sintetici” come tipo, e assegna un nome all’attività.
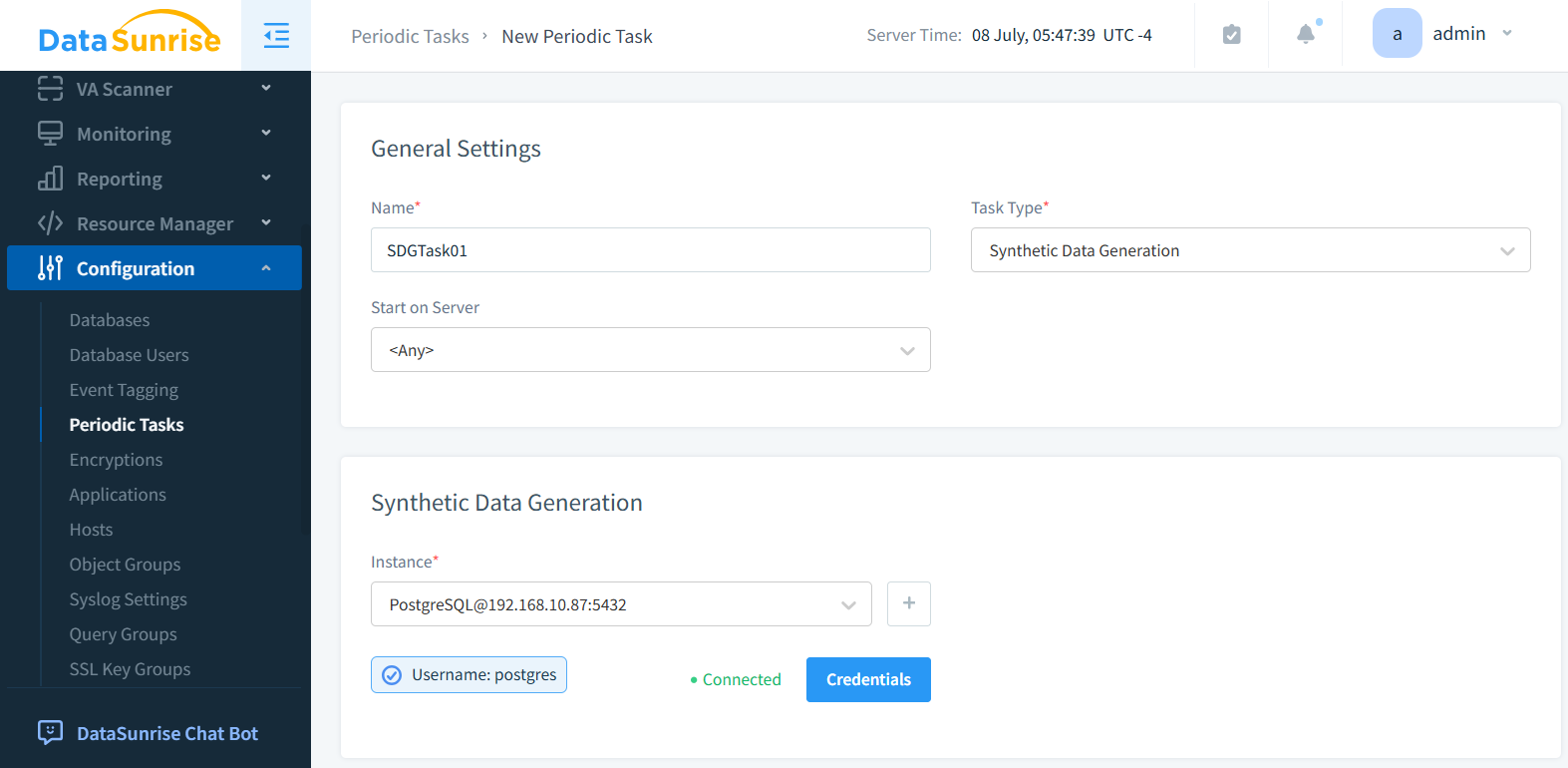
Passo 2: Selezionare l’Istanza del Database
Scegli l’istanza target. Qui sotto è selezionato PostgreSQL come motore database.
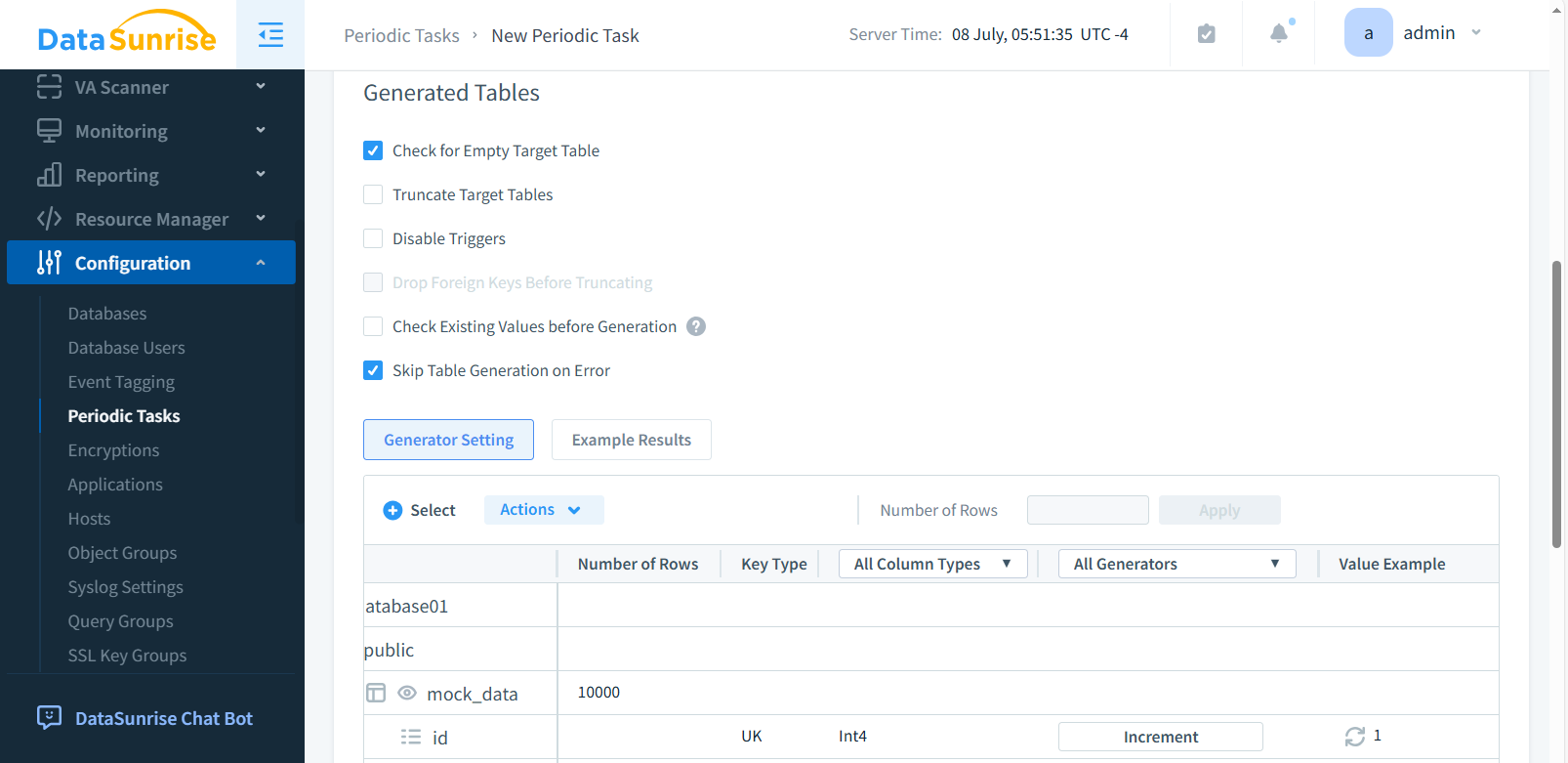
Passo 3: Definire Tabelle e Colonne Target
Seleziona lo schema e le tabelle dove i dati sintetici saranno inseriti. Scegli colonne specifiche, abilita “Tabella Vuota” se necessario, e configura il comportamento in caso di errori.
Passo 4: Usare Generator Built-in o Personalizzati
Scegli tra generatori integrati di valori (nomi, email, numeri, date) o definisci logiche personalizzate tramite Configurazione → Generator. Utile per corrispondere pattern specifici di dominio, come la simulazione di codici paziente o codici fiscali.
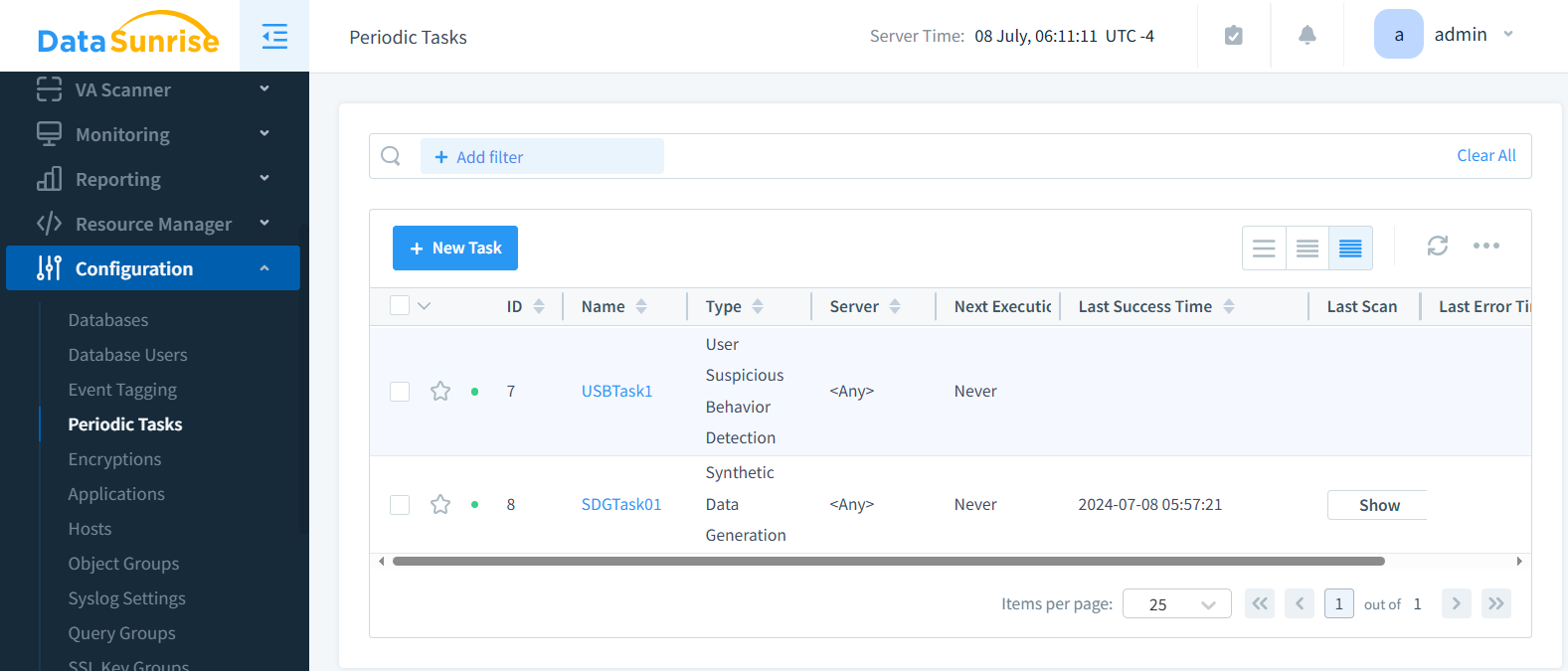
Passo 5: Salvare, Pianificare ed Eseguire
Una volta salvata, l’attività compare nell’elenco dei job. Puoi eseguirla manualmente o pianificare esecuzioni periodiche per un aggiornamento continuo dei dati.
Strumenti e Librerie Gratuiti per Dati Sintetici
DataSunrise fornisce un supporto completo per la generazione sintetica con masking, auditing e controlli di conformità. Ma sviluppatori e data scientist possono anche usufruire di alternative gratuite per apprendere o prototipare.
SDV (Synthetic Data Vault)
SDV è un framework Python open-source che usa modelli statistici e GAN per generare dataset sintetici tabellari. Supporta strutture relazionali e multitable.
pip install sdv
from sdv.datasets.demo import download_demo
from sdv.single_table import GaussianCopulaSynthesizer
real_data, metadata = download_demo(modality='single_table', dataset_name='fake_hotel_guests')
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(real_data)
synthetic_data = synthesizer.sample(num_rows=500)
print(synthetic_data.head())
CTGAN
Modello basato su GAN, adatto a dati tabellari sbilanciati e colonne miste. Consulta il nostro precedente articolo su generazione dati AI per codice di esempio.
Mockaroo
Mockaroo è uno strumento web per generare dataset mock in CSV, JSON, SQL e altri formati. Ideale per prototipi veloci e supporta schemi di campo personalizzati. L’uso gratuito è limitato a 1.000 righe per sessione.
Validazione della Qualità dei Dati Sintetici
Generare record sintetici è solo metà del lavoro. Devi confermare che i dati si comportino come quelli reali senza esporre valori sensibili. Controlli comuni includono:
- Somiglianza delle distribuzioni: Confronta le distribuzioni delle colonne tra reale e sintetico.
- Preservazione delle correlazioni: Verifica che i rapporti tra campi rimangano intatti.
- Distanza di privacy: Assicura che nessuna riga sintetica sia troppo simile a un record reale.
Esempio Python: Test Kolmogorov–Smirnov
from scipy.stats import ks_2samp
# Confronta distribuzioni di colonna reali vs sintetiche
ks_stat, p_value = ks_2samp(real_data["age"], synthetic_data["age"])
if p_value > 0.05:
print("Distribuzione 'age' sintetica corrisponde ai dati reali")
else:
print("Differenza significativa rilevata")
Controllo Matrice di Correlazione
import pandas as pd
real_corr = real_data.corr(numeric_only=True)
synth_corr = synthetic_data.corr(numeric_only=True)
diff = (real_corr - synth_corr).abs()
print(diff.head())
Questi passaggi di validazione garantiscono che i dati sintetici siano utili per analisi e pipeline ML, mantenendo al contempo sicurezza e conformità.
Best Practice per i Dati Generati
- Adattare i formati ai requisiti downstream.
Assicurati che i valori sintetici seguano gli stessi pattern—tipi di dato, range, formati e vincoli—così che applicazioni, pipeline e strumenti analitici funzionino senza modifiche. - Preservare le relazioni tra tabelle dove necessario.
Mantieni dipendenze chiave come primary/foreign key, gerarchie e lookup table per garantire corretto funzionamento di workflow, join e logiche di business. - Documentare regole di generazione per replicabilità.
Registra la logica, i seed e le regole di trasformazione usate per creare il dataset per supportare rigenerazioni coerenti, auditing e troubleshooting. - Eseguire controlli di integrità logica.
Verifica che distribuzioni, range e pattern comportamentali appaiano realistici—identificando precocemente anomalie come valori fuori limite, campi vuoti o relazioni rotte. - Usare masking o esclusioni per evitare qualsiasi sovrapposizione con dati reali.
Conferma che i valori sintetici non siano tracciabili a informazioni reali di clienti, riducendo il rischio di re-identificazione e rafforzando la conformità.
Confronto Rapido
| Strumento | Ideale per | Limitazioni |
|---|---|---|
| SDV | Simulazione statistica di dati tabellari | Solo Python, richiede taratura |
| CTGAN | Dataset complessi e sbilanciati | Training lento, può necessitare GPU |
| Mockaroo | Prototipi rapidi in CSV/JSON/SQL | Limite righe, non aware di schema |
Dati Sintetici nei Framework di Conformità
La generazione di dati sintetici si allinea naturalmente con le normative moderne rimuovendo identificatori diretti e preservando il valore analitico. Ecco come si mappa ai framework comuni:
| Framework | Requisito | Come Aiutano i Dati Sintetici |
|---|---|---|
| GDPR | Art. 32 — pseudonimizzazione e minimizzazione dei dati personali | Genera record artificiali senza collegamento a persone reali, soddisfacendo gli standard di pseudonimizzazione e minimizzazione. |
| HIPAA | §164.514 — de-identificazione degli identificatori PHI | Produce cartelle cliniche non identificabili per ricerca e test proteggendo le PHI. |
| PCI DSS | Req. 3.4 — impedire lo stoccaggio di PAN in ambienti di test | Record di pagamento sintetici permettono QA e condivisione vendor senza esporre dati reali di carte. |
| SOX | §404 — garantire integrità dati finanziari per audit | Fornisce dati di test sicuri per validare sistemi finanziari senza rischi per i record di produzione. |
Allineando la generazione sintetica a questi framework, DataSunrise aiuta le organizzazioni a velocizzare l’adozione di AI e analytics restando pronte per gli audit e pienamente conformi.
Quando i Dati Sintetici Non Sono Abbastanza: Considerazioni e Controlli
Sebbene i dati generati sinteticamente offrano forti garanzie di privacy e flessibilità, non sono un sostituto universale per dati reali o workflow di masking enterprise. Alcuni scenari—come test di integrità referenziale, join deterministici o analisi longitudinali—possono richiedere ancora accesso controllato a dataset mascherati o pseudonimizzati.
Per assicurarti che i dati generati servano efficacemente i tuoi obiettivi, considera queste linee guida:
- Allineamento con casi d’uso: Per validazione modelli, usa dati completamente sintetici. Per test di integrazione o UI, cloni mascherati di produzione possono essere più precisi.
- Documentazione di governance: Registra quali campi sono stati generati sinteticamente, quali preservati e quali strumenti o logiche sono state utilizzate.
- Campionamento vs simulazione: Non confondere il campionamento casuale di dati reali con la generazione sintetica. Solo quest’ultima rompe il collegamento con soggetti identificabili.
- Prontezza all’audit: Mantieni log di attività di generazione, tempistiche di retention e controlli di accesso—soprattutto se i dati sintetici entrano in pipeline di test condivise con vendor o appaltatori.
DataSunrise aiuta a bilanciare queste scelte con automazione, fallback masking e piena visibilità su tipi di dati e ambienti. Il risultato sono flussi di lavoro dati più sicuri, intelligenti e rapidi—senza compromessi di conformità.
Punti Chiave per Usare Efficacemente i Dati Sintetici
- Scegli i dati sintetici quando la compliance richiede zero esposizione a record reali, o per condivisione esterna di dataset.
- Combina generazione sintetica e masking per scenari ibridi—mantenendo integrità relazionale dove serve e sostituendo completamente i campi ad alto rischio.
- Documenta regole di generazione, politiche di retention e controlli accesso per mantenere governance e prontezza all’audit.
- Testa i dataset sintetici contro flussi di lavoro reali per confermare performance, accuratezza e compatibilità.
- Automatizza le attività di generazione tramite schedulazione e integrazione con pipeline CI/CD per risultati coerenti e ripetibili.
FAQ sui Dati Sintetici
Cos’è il dato sintetico?
I dati sintetici sono informazioni generate artificialmente che rispecchiano struttura e proprietà statistiche di dataset reali, ma non contengono alcun record cliente reale. Permettono test, analisi e addestramento AI sicuri senza rischi per la privacy.
In cosa i dati sintetici differiscono dal masking?
Il masking altera valori reali per oscurare identificatori, mantenendo schema e integrità referenziale. I dati sintetici invece creano record completamente artificiali senza alcun legame con individui reali, rendendoli più sicuri per la condivisione esterna e pipeline AI.
Quando dovrebbero usare i dati sintetici le organizzazioni?
I dati sintetici sono ideali per casi d’uso dove la conformità richiede zero esposizione a record reali—come collaborazione con vendor esterni, addestramento di LLM o popolamento di ambienti non-prod su larga scala.
Quali framework di conformità supportano i dati sintetici?
Framework come GDPR, HIPAA e PCI DSS riconoscono pseudonimizzazione e de-identificazione. La generazione sintetica offre un percorso efficace di conformità integrato con governance.
Quali sono le limitazioni dei dati sintetici?
Potrebbero non replicare pienamente join complessi, storici longitudinali o pattern di outlier rari. Per questi scenari le organizzazioni spesso combinano masking e generazione sintetica in flussi ibridi.
Come supporta DataSunrise i dati sintetici?
DataSunrise integra la generazione di dati sintetici con masking, auditing e reportistica di conformità. Offre generatori policy-aware, flussi schedulati e tracciamenti completi per garantire che ogni dataset rispetti requisiti regolatori.
Applicazioni Industriali dei Dati Sintetici
I dati sintetici supportano più del solo testing—abilitano direttamente conformità e innovazione in vari settori:
- Finanza: Genera log artificiali di transazioni per l’addestramento di modelli antifrode, rispettando audit PCI DSS e SOX senza esporre PAN.
- Sanità: Crea dataset pazienti de-identificati in linea con HIPAA, abilitando ricerca e sviluppo AI diagnostica sicuri.
- SaaS & Cloud: Fornisce dataset tenant compliant GDPR per ambienti di staging, validando isolamento multi-tenant.
- Pubblica Amministrazione: Condivide dataset popolazione con appaltatori rispettando GDPR e leggi locali sulla privacy.
- Retail & eCommerce: Popola pipeline analitiche con percorsi cliente sintetici per testare motori di personalizzazione senza rischi di privacy.
Contestualizzando i dati sintetici per ogni settore, le organizzazioni accelerano innovazione restando pronte agli audit e tutelando la privacy.
Il Futuro della Generazione di Dati Sintetici
I dati sintetici stanno rapidamente evolvendo da semplice utilità di test a componente chiave della strategia dati enterprise. Mentre le organizzazioni puntano a innovare responsabilmente, le piattaforme di prossima generazione combineranno generazione AI-driven, validazione qualità dati e controlli di compliance automatizzati per creare dataset realistici ma totalmente anonimizzati su larga scala. Questi sistemi non solo riprodurranno accuratezza statistica e integrità strutturale, ma si adatteranno dinamicamente a modelli dati, requisiti privacy e scenari regolatori in evoluzione.
Le soluzioni future offriranno integrazione fluida con tecnologie complementari quali data masking, monitoraggio attività database e scoperta dati sensibili. Questa interoperabilità permetterà alle organizzazioni di passare agilmente tra dati reali, mascherati e sintetici in base al contesto—abilitando analisi sicure, training modelli e collaborazioni esterne senza esporre informazioni regolate. Col tempo, questo ecosistema dati adattivo renderà l’innovazione con tutela della privacy la norma, non l’eccezione. Funzionalità come la automazione della conformità garantiranno che i dataset sintetici rispettino costantemente requisiti regolatori e organizzativi.
Per settori fortemente regolati come finanza, sanità e pubblica amministrazione, i dati sintetici ridefiniranno l’equilibrio tra compliance e innovazione. Le imprese potranno accelerare l’adozione di AI, collaborare in sicurezza con terze parti e mantenere prove verificabili che nessun dato cliente autentico sia mai uscito da ambienti controllati. In definitiva, il futuro della generazione di dati sintetici risiede in automazione intelligente e compliance continua, trasformando la privacy in un abilitatore di progresso e non in un vincolo.
Conclusione
I dati sintetici sono diventati un componente chiave delle moderne strategie di gestione dati privacy-first, offrendo un’alternativa sicura e conforme all’uso di dataset reali di produzione per sviluppo, test, analisi e machine learning. Riproducendo struttura, caratteristiche statistiche e relazioni dei dati reali—senza trattenere informazioni personali o proprietarie identificabili—permettono alle organizzazioni di innovare, collaborare e analizzare in sicurezza. Questo approccio privacy-by-design minimizza rischi di conformità, riduce responsabilità legali e supporta il deployment etico di AI in settori come finanza, sanità, telecomunicazioni e pubblico.
DataSunrise integra la generazione di dati sintetici all’interno della sua piattaforma completa per sicurezza e governance dei dati. Attraverso enforcement automatizzato delle policy, logiche di masking avanzate e audit trail dettagliati, la piattaforma assicura che i dataset sintetici rispettino sia i framework di governance interni che gli standard esterni quali GDPR, HIPAA, SOX e PCI DSS. Questo consente alle imprese di produrre dati realistici ma totalmente anonimizzati, adatti ad addestramento AI, testing software e collaborazione con terze parti—senza rischiare l’esposizione di contenuti sensibili o riservati.
Integrati con soluzioni come il Monitoraggio delle Attività del Database (DAM), la scoperta dati e il masking dinamico, i dati sintetici diventano un potente abilitante della trasformazione digitale sicura. Permettono alle organizzazioni di accelerare l’innovazione mantenendo trasparenza e conformità, supportando sperimentazioni responsabili e miglioramento continuo. Con l’evolversi delle normative sulla privacy e l’avanzare delle tecnologie AI, i dati sintetici resteranno un elemento fondante dell’innovazione dati sicura, etica e scalabile.
Successivo
