
Prevenzione della Perdita dei Dati per Pipeline GenAI e LLM

L’Intelligenza Artificiale Generativa (GenAI) e i modelli linguistici di grandi dimensioni (LLM) hanno trasformato l’innovazione basata sui dati, ma la loro dipendenza da vasti dataset e l’accesso guidato dai prompt crea un pericoloso punto cieco: la fuga incontrollata dei dati. Dal training su registrazioni sensibili alla generazione di output che inavvertitamente espongono informazioni proprietarie o personali, il rischio non è più teorico. Prevenire la perdita dei dati in queste pipeline è essenziale.
Questo articolo esplora metodi pratici di Prevenzione della Perdita dei Dati per Pipeline GenAI e LLM, concentrandosi su audit in tempo reale, mascheramento dinamico, scoperta dei dati e applicazione della sicurezza. Queste tecniche forniscono controlli attuabili che aiutano le organizzazioni a rimanere conformi e sicure senza compromettere l’innovazione.
Perché gli Strumenti DLP Tradizionali Non Bastano
La maggior parte dei sistemi convenzionali di prevenzione della perdita dei dati opera a livello di file. Questi monitorano email in uscita, trasferimenti di dati o attività di copia/incolla e si basano su pattern predefiniti. Questi metodi faticano nei contesti GenAI, dove i dati scorrono attraverso modelli piuttosto che file. Le pipeline LLM accedono a fonti in tempo reale come database e API, mescolano dati sensibili e pubblici e memorizzano contenuti potenzialmente regolamentati durante il training.
Ad esempio, un prompt come “Riassumi la valutazione delle prestazioni interne dell’ultimo trimestre” può innescare una perdita di dati se il modello ha accesso alla memoria o registra query precedenti. Ciò significa che i controlli DLP devono essere incorporati all’interfaccia tra dati e modello. Come evidenziato dal NIST AI Risk Management Framework, i sistemi di IA richiedono salvaguardie personalizzate che evolvono assieme ai modelli che supportano.
Scoprire i Dati Prima di Protegerli
Prima di implementare misure preventive, le organizzazioni devono capire quali dati possiedono, dove risiedono e chi vi accede. Questo inizia con la scoperta automatizzata dei dati che esamina storage strutturati e non strutturati alla ricerca di elementi sensibili come PII, PHI e proprietà intellettuale.
Gli strumenti di scoperta di DataSunrise eseguono scansioni continue per individuare campi sensibili, associandoli ai requisiti di conformità rilevanti, e mantengono aggiornata la classificazione. Questa visibilità proattiva è essenziale prima di applicare politiche di audit o mascheramento.
Ricerche emergenti di Google DeepMind dimostrano come anche i dati di training anonimizzati possano essere ri-identificati dagli LLM, rendendo la scoperta precoce un requisito imprescindibile.
Audit in Tempo Reale e Tracciabilità
Una volta stabilita la visibilità, l’audit in tempo reale diventa la spina dorsale di una distribuzione sicura della GenAI. Ogni richiesta all’LLM, ogni query al database e tutta l’attività di inferenza devono essere registrate. Monitorare l’identità del richiedente, i dati accessi e il risultato consente una sicurezza proattiva.
Prendiamo questo esempio di traccia SQL:
SELECT customer_ssn, diagnosis FROM patient_records WHERE status = 'active';
Se emessa da un account di sistema GenAI privo di accesso a PHI, un motore di audit come DataSunrise può bloccare o segnalare la query, emettendo allerte in tempo reale agli analisti della sicurezza. I tracciati di audit garantiscono che anche le interazioni transitorie siano registrate.
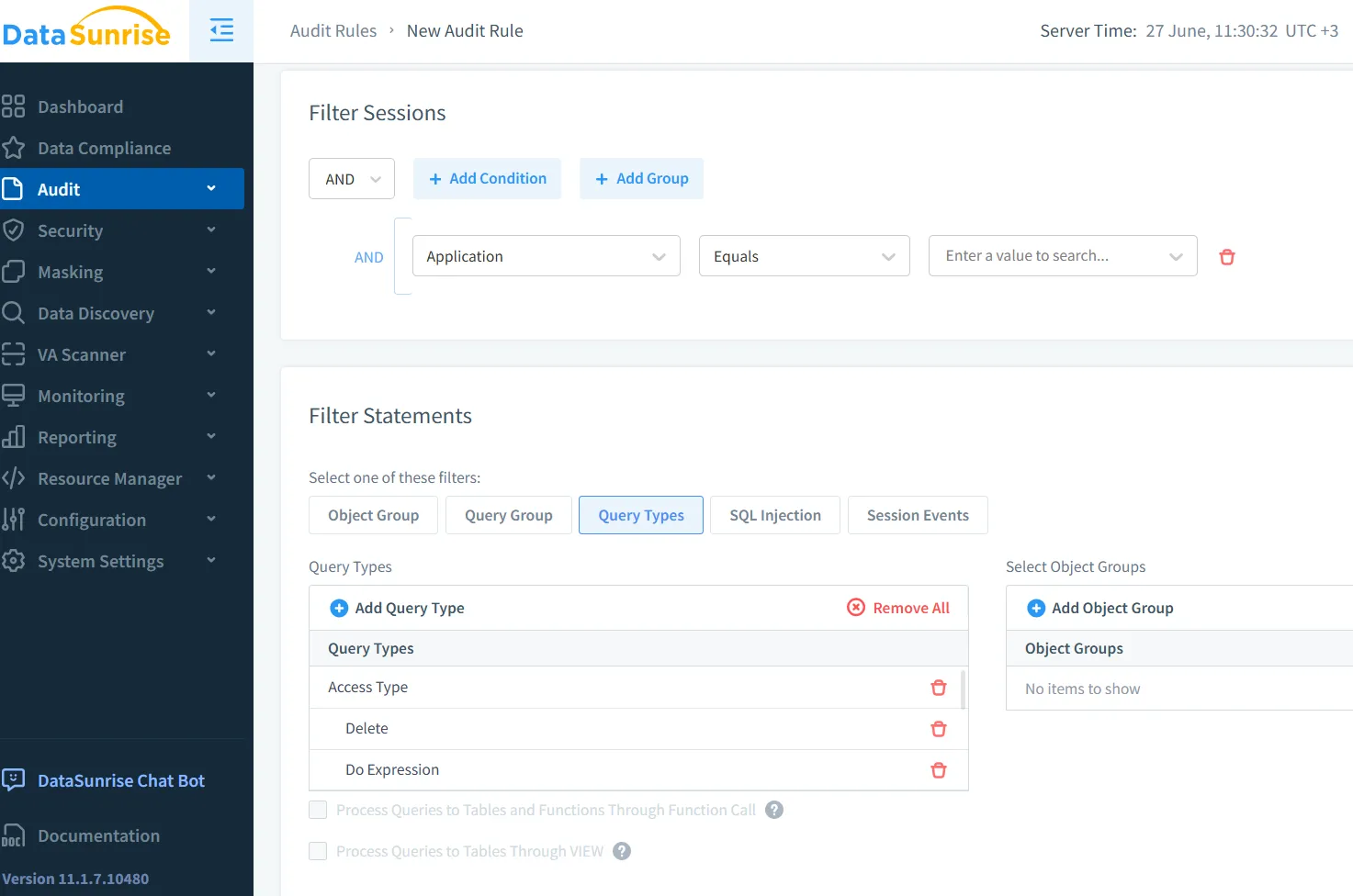
Inoltre, piattaforme come Microsoft Purview forniscono logging degli audit integrato con analisi basate su ruoli, offrendo visibilità sulle interazioni dei dati a livello utente all’interno delle pipeline di IA.
Mascheramento dei Dati per Output Sicuri nell’IA
Il mascheramento statico funziona per ambienti di test, ma non è sufficiente per LLM che operano su dati live. Le pipeline GenAI richiedono un mascheramento dinamico dei dati, che intercetta le risposte in base all’identità dell’utente e alla politica applicata.
Considera il seguente prompt:
“Elenca i clienti VIP in California insieme alle loro email.”
Il mascheramento dinamico garantisce che un output come:
Name: [REDACTED] | Email: [MASKED]@domain.com
venga visualizzato per utenti non privilegiati. Questa tecnica, supportata dal Mascheramento Dinamico dei Dati di DataSunrise, consente un’interazione sicura senza compromettere l’integrità o la disponibilità del database.
Anche modelli open-source come PySyft di OpenMined stanno iniziando a supportare pipeline di inferenza che preservano la privacy, dimostrando un crescente interesse della comunità su questo tema.
Applicare Regole di Sicurezza alle Interfacce dei Prompt
Le interfacce GenAI includono spesso API, bot su Slack, dashboard o assistenti interni. Queste interfacce sono vulnerabili a input non monitorati. Applicare regole di sicurezza direttamente sul livello di query può prevenire sfruttamenti.
Strategie utili includono il blocco di prompt contenenti parole chiave come SSN, password o dati finanziari, e limitare la frequenza di accesso. Il controllo degli accessi basato sui ruoli garantisce che solo utenti autorizzati possano interagire con prompt sensibili. Questi controlli possono essere applicati attraverso politiche di sicurezza integrate con audit e mascheramento.
Inoltre, l’Intelligenza Artificiale Costituzionale di Anthropic propone di incorporare principi di sicurezza direttamente nel ragionamento del modello, in complemento alle regole di sicurezza basate sul perimetro.
Conformità nelle Pipeline GenAI
Framework di conformità come GDPR, HIPAA e PCI-DSS impongono una gestione rigorosa dei dati personali e finanziari. Gli LLM senza meccanismi di controllo integrati possono facilmente violare questi standard.
Per rimanere conformi:
- Mantenere tracciati di audit completi per tutte le attività GenAI.
- Mascherare dinamicamente i dati personali nei risultati di training e inferenza.
- Utilizzare un compliance manager per automatizzare l’applicazione delle politiche e la reportistica.
Le linee guida del Comitato Europeo per la Protezione dei Dati sull’IA rafforzano la necessità di salvaguardie dimostrabili e trasparenza in tutti i sistemi generativi.
Verso una GenAI Trasparente e Sicura
Mettere in sicurezza le pipeline GenAI richiede più che semplicemente correggere le vulnerabilità dopo il fatto. Occorre un approccio contestualmente consapevole in cui la classificazione dei dati, l’audit, il mascheramento e l’applicazione delle politiche siano parte integrante della pipeline.
Con strumenti come DataSunrise, le organizzazioni possono costruire applicazioni LLM sicure, conformi e trasparenti. Applicare la Prevenzione della Perdita dei Dati per Pipeline GenAI e LLM non è solo un requisito normativo — è un vantaggio competitivo che protegge sia l’innovazione che la reputazione.
Man mano che il governo dell’IA diventa centrale sia per il rischio che per l’opportunità, adottare un DLP contestualmente consapevole in tempo reale nei workflow GenAI non è più opzionale — è fondamentale.
Proteggi i tuoi dati con DataSunrise
Metti in sicurezza i tuoi dati su ogni livello con DataSunrise. Rileva le minacce in tempo reale con il Monitoraggio delle Attività, il Mascheramento dei Dati e il Firewall per Database. Applica la conformità dei dati, individua le informazioni sensibili e proteggi i carichi di lavoro attraverso oltre 50 integrazioni supportate per fonti dati cloud, on-premises e sistemi AI.
Inizia a proteggere oggi i tuoi dati critici
Richiedi una demo Scarica ora