Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica
Gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica stanno diventando essenziali man mano che le imprese accelerano l’adozione dell’IA generativa, della generazione aumentata dal recupero (RAG), dell’ingegneria delle funzionalità e dell’analisi predittiva. Vertica spesso serve come backend analitico ad alte prestazioni per pipeline di machine learning, preparazione dati su larga scala e applicazioni guidate dall’intelligenza artificiale. Tuttavia, questi stessi flussi di lavoro aumentano il rischio di esporre involontariamente informazioni regolamentate o riservate a modelli, prompt e consumatori a valle. Di conseguenza, le organizzazioni devono adottare strumenti di conformità automatizzati in grado di monitorare, mascherare e controllare l’accesso assistito dall’IA ai dati Vertica.
I moderni sistemi di IA introducono nuovi schemi di esposizione. I modelli linguistici di grandi dimensioni, gli agenti autonomi e i carichi di lavoro di machine learning spesso generano SQL imprevedibili, estraggono set di dati eccessivamente ampi o elaborano campi sensibili come materiale di addestramento. Quando non protetti, un motore LLM o ML può far emergere informazioni private nelle risposte, negli embedding o negli artefatti derivati del modello, causando potenziali violazioni di conformità secondo il GDPR, HIPAA, PCI DSS o il NIST 800-53. Poiché Vertica non include nativamente controlli di accesso consapevoli degli LLM, mascheratura dinamica, applicazione contestuale o auditing cross-pipeline, le organizzazioni devono integrare uno strato di conformità specializzato che operi proattivamente prima che i dati raggiungano il modello o lo strato pipeline.
DataSunrise fornisce queste capacità. La piattaforma agisce come un gateway centralizzato di conformità per Vertica fornendo scoperta di dati sensibili, mascheratura dinamica, enforcement SQL e auditing automatico. Insieme, queste funzionalità formano la base degli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica.
Perché Vertica Richiede l’Automazione della Conformità Consapevole degli LLM
I carichi di lavoro guidati dall’IA introducono sfide di conformità che i sistemi di governance tradizionali non riescono ad affrontare. Ad esempio, SQL generato da LLM può richiedere involontariamente quantità eccessive di dati sensibili. Inoltre, le pipeline ETL possono estrarre corpora di addestramento da Vertica senza validare se i campi sottostanti contengano PII o PHI. Nel frattempo, le architetture RAG spesso vettorizzano colonne di testo — incluse quelle contenenti identificatori personali — in embedding, rendendo estremamente difficile la gestione della tracciabilità.
Inoltre, l’architettura di Vertica aggrava questi rischi. Funzionalità come proiezioni, storage ROS/WOS e schemi analitici ampi possono distribuire valori sensibili su più strutture fisiche. Poiché Vertica opera come piattaforma analitica ad alte prestazioni per una varietà di carichi di lavoro — che spaziano da dashboard BI fino a framework ML come VerticaPy — eventuali lacune nella conformità possono rapidamente propagarsi tra più team e sistemi.
Per evitare mancanze nella conformità, le organizzazioni necessitano di Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica che automatizzino:
- la scoperta delle colonne sensibili di Vertica prima dell’addestramento ML o dell’ingestione RAG,
- la mascheratura dinamica degli attributi ad alto rischio per i carichi di lavoro NLP e LLM,
- l’applicazione contestuale delle regole SQL per prevenire query non sicure o eccessive generate dall’IA,
- l’auditing automatizzato di tutti gli accessi generati dall’IA a Vertica,
- il monitoraggio per ridurre il rischio di allucinazioni degli LLM che espongono valori privati.
Di conseguenza, senza controlli automatizzati, le pipeline di IA possono ingerire involontariamente dati non mascherati o rivelare campi sensibili durante l’inferenza.
Architettura degli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica
Il diagramma sottostante illustra come gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica funzionino come uno strato di sicurezza e trasformazione tra Vertica e i carichi di lavoro IA. Ogni richiesta LLM, ML, NLP e ETL transita attraverso questo strato di enforcement, garantendo mascheratura, auditing e ispezione SQL consistenti.

Questa architettura supporta:
- assistenti LLM che generano SQL dinamicamente,
- pipeline RAG che interrogano tabelle Vertica per il recupero,
- processi di ingegneria delle funzionalità che leggono colonne sensibili,
- addestramento ML batch che preleva set di dati direttamente da Vertica.
Poiché tutto l’enforcement avviene prima che i dati Vertica raggiungano i sistemi IA, le organizzazioni mantengono completa visibilità, coerenza e governance su ogni flusso di lavoro NLP, LLM e ML.
Scoperta dei Dati Sensibili nelle Pipeline IA di Vertica
L’automazione efficace inizia dalla scoperta. Gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica devono identificare tutti i campi sensibili che potrebbero influenzare i dati di addestramento, gli embedding vettoriali, i prompt o gli output di inferenza. Sensitive Data Discovery di DataSunrise esegue la scansione delle tabelle Vertica e identifica automaticamente PII, PHI, valori finanziari, token di autenticazione e colonne di testo libero contenenti contenuti regolamentati.
Questo meccanismo di scoperta proattiva previene la contaminazione dei dataset di addestramento con informazioni sensibili. Inoltre, i risultati della scoperta si integrano direttamente con i moduli di mascheratura e enforcement SQL, garantendo che i campi appena individuati erediteranno automaticamente le protezioni di conformità richieste.
Mascheratura Dinamica per gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica
La mascheratura dinamica è uno dei principali strumenti di conformità NLP, LLM & ML per Vertica. Quando i sistemi IA generano SQL, raramente specificano quali colonne debbano rimanere protette. A causa di questa imprevedibilità, la mascheratura deve avvenire automaticamente — basandosi su policy — e non sulla logica applicativa.
Lo screenshot sottostante mostra come gli amministratori configurano la mascheratura dinamica per i campi Vertica frequentemente utilizzati dalle pipeline ML e NLP:
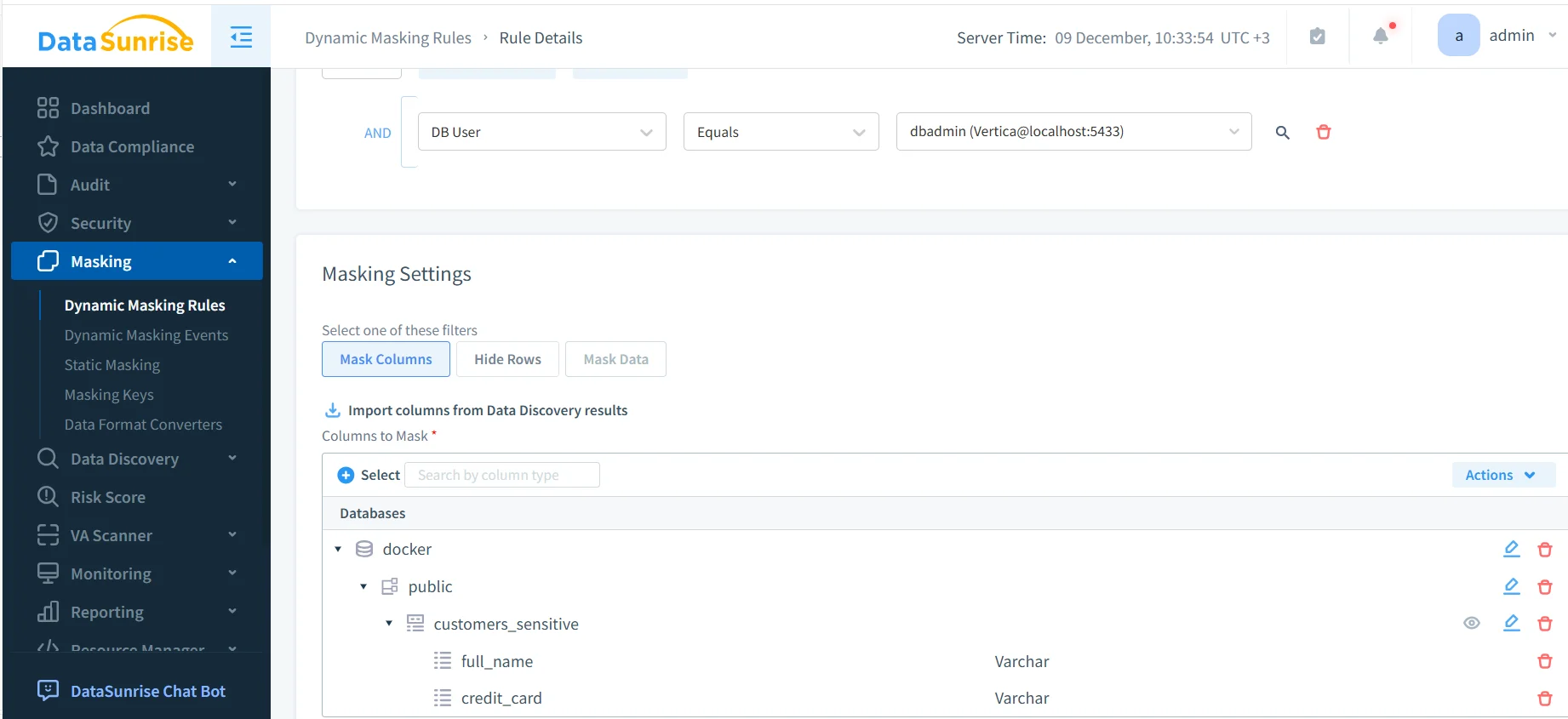
Questa mascheratura automatizzata protegge gli attributi sensibili durante:
- la generazione di prompt per applicazioni LLM,
- i flussi di lavoro di recupero basati su RAG che alimentano i depositi vettoriali,
- le estrazioni ETL per feature store ML,
- la costruzione del dataset di addestramento del modello,
- l’esplorazione da parte dei data scientist all’interno dei notebook.
Inoltre, la mascheratura impedisce ai modelli IA di divulgare valori originali nelle risposte, negli embedding o negli artefatti di addestramento — conformandosi alle regole di pseudonimizzazione GDPR e ai requisiti PCI DSS.
Enforcement SQL per gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica
Il SQL generato dall’IA può introdurre rischi significativi. Gli LLM frequentemente producono query che includono JOIN non vincolati, scansioni SELECT * o estrazioni a livello di schema. Inoltre, gli agenti IA potrebbero generare accidentalmente istruzioni di modifica come DROP TABLE o ALTER TABLE. Per affrontare queste sfide, gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica applicano regole SQL contestuali prima che la query raggiunga Vertica.
Questo enforcement previene:
- attacchi di prompt injection che tentano di estrarre tabelle sensibili o riservate,
- scansioni ad alto volume che espongono interi dataset a un LLM,
- alterazioni di schema generate da agenti autonomi,
- recuperi di dati eccessivi durante l’ingegneria delle funzionalità ML.
Con l’automazione dell’enforcement in atto, le organizzazioni ottengono la certezza che il SQL generato dagli LLM non possa superare i limiti di policy.
Auditing Automatico per gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica
L’auditing completo è essenziale per una governance responsabile dell’IA. Gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica devono fornire una visione completa di come agenti IA, pipeline e applicazioni interagiscono con i dati sensibili di Vertica. Il logging manuale è insufficiente perché i carichi di lavoro IA generano migliaia di query in autonomia.
DataSunrise cattura automaticamente l’attività SQL, le transizioni di sessione, i risultati delle mascherature e le azioni di attivazione delle regole. Lo screenshot sottostante mostra una traccia di audit unificata adatta sia per revisioni operative che per verifiche regolatorie.
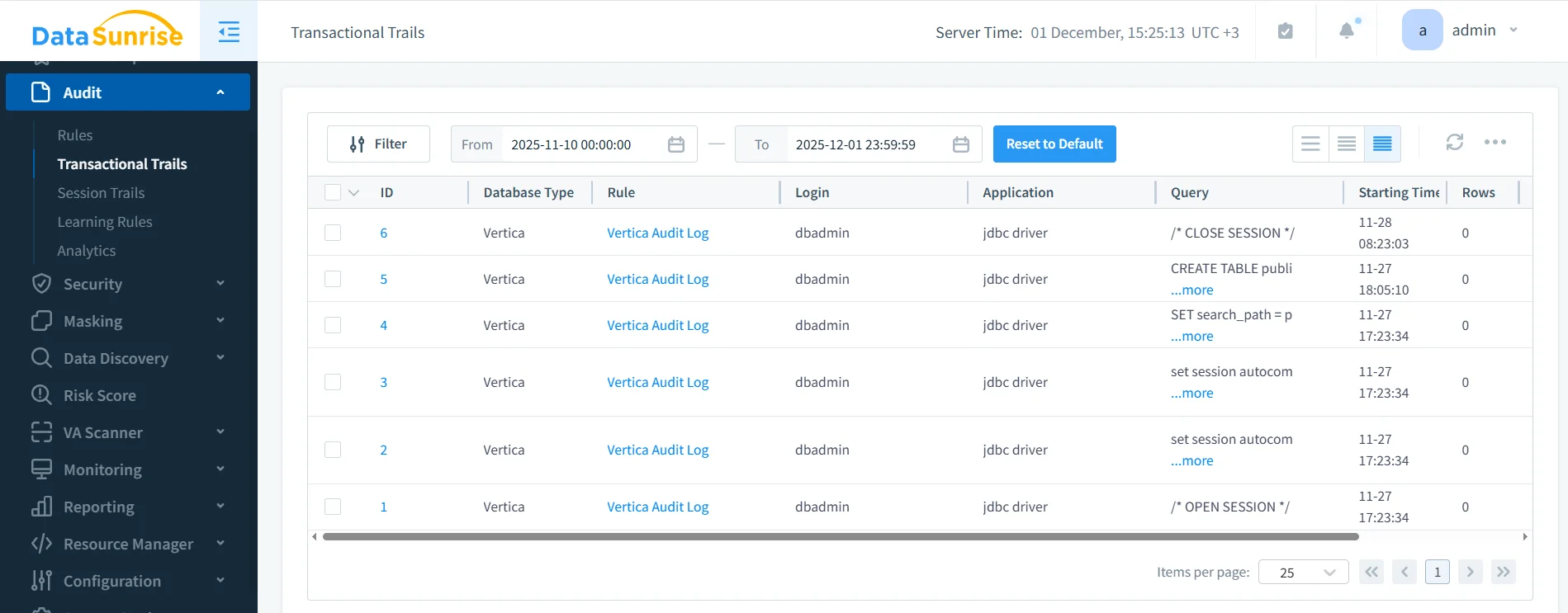
Questi log permettono ai team di conformità di:
- tracciare come è stato generato un dataset costruito da un LLM,
- validare che i campi sensibili siano stati mascherati durante l’ingestione,
- investigare comportamenti anomalie o ad alto rischio del modello,
- produrre evidenze di spiegabilità per deployment IA regolamentati.
Poiché i dati di audit sono centralizzati, le organizzazioni mantengono un controllo consistente su tutte le interazioni LLM, NLP, ETL e ML.
Confronto: Vertica vs. Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica
| Requisito di Conformità IA | Capacità Nativa di Vertica | Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica |
|---|---|---|
| Rilevamento PII/PHI prima dell’addestramento | Revisione manuale | Scoperta automatizzata dei dati sensibili |
| Mascheratura dinamica per query IA | Non disponibile | Mascheratura in tempo reale |
| Enforcement SQL per LLM | Solo RBAC | Filtraggio SQL basato su regole |
| Log di audit centralizzati | Log distribuiti | Traccia di audit unificata |
| Tracciabilità dei dati di addestramento | Tracciamento manuale | Correlazione automatizzata consapevole dell’IA |
Conclusione
Gli Strumenti di Conformità dei Dati NLP, LLM & ML per Vertica consentono alle organizzazioni di implementare tecnologie IA in modo sicuro e responsabile. La mascheratura dinamica blocca l’esposizione di valori sensibili. L’enforcement SQL previene query non sicure o indesiderate generate da sistemi autonomi. L’auditing automatizzato offre completa visibilità e prove per revisioni regolatorie. Insieme, questi controlli costituiscono un framework di automazione della conformità end-to-end che protegge i dati Vertica in tutti i carichi di lavoro NLP, LLM e ML.
