Strumenti e Tecniche di Data Masking per MariaDB
Gli ambienti moderni di database raramente servono a un unico scopo. Una tipica implementazione di MariaDB supporta applicazioni, analisi, team di supporto, processi automatizzati e integrazioni esterne. In molti casi, tutti lavorano sugli stessi dataset. Quando quei dataset contengono informazioni personali, finanziarie o regolamentate, una visibilità non limitata diventa rapidamente un rischio.
Per una panoramica dell’architettura e dei casi d’uso di MariaDB, consulta la documentazione ufficiale: https://mariadb.org/
Il data masking affronta questo problema trasformando i valori sensibili prima che gli utenti o le applicazioni li visualizzino. A differenza della crittografia, il masking mantiene intatta la struttura del database e il comportamento delle query. Allo stesso tempo, limita ciò che gli utenti possono effettivamente vedere. Di conseguenza, il masking si integra naturalmente con più ampie strategie di sicurezza dei dati
e sicurezza dei database.
Nel frattempo, la pressione normativa continua a crescere e il rischio interno diventa sempre più difficile da ignorare. Per questo motivo, il data masking è passato da una funzionalità “agradabile da avere” a un requisito operativo. In ambienti regolamentati, le organizzazioni collegano strettamente il masking alle normative di conformità dei dati
e alla protezione delle informazioni personali identificabili (PII).
Questo articolo spiega come i team possano implementare il data masking in MariaDB utilizzando tecniche native. Mostra anche come le piattaforme centralizzate estendano il masking in un controllo basato su politiche, controllabile e conforme, tramite meccanismi come il dynamic data masking.
Cos’è il Data Masking?
Il data masking è una tecnica di protezione dei dati che sostituisce i valori sensibili con equivalenti modificati, oscurati o sintetici. Il suo obiettivo è ridurre il rischio di esposizione mantenendo i dati utilizzabili per sviluppo, analisi e flussi di lavoro operativi. In pratica, il masking funziona insieme a più ampie iniziative di sicurezza dei dati
.
Le organizzazioni possono implementare il masking in diversi modi. Ad esempio, i team possono applicarlo staticamente a copie dei dati, farlo rispettare dinamicamente al momento della query o aggiustarlo in base all’identità dell’utente, al ruolo o al percorso di accesso. Sebbene ogni approccio risponda a diverse esigenze operative, tutti condividono lo stesso obiettivo: limitare la visibilità non necessaria dei valori sensibili.
La maggior parte delle organizzazioni utilizza il masking per proteggere informazioni personali identificabili (PII), registri finanziari, segreti di autenticazione e attributi sensibili per il business. Questi tipi di dati appaiono in molti flussi di lavoro e gruppi di utenti. Perciò, l’esposizione selettiva diventa essenziale e supporta direttamente le normative di conformità dei dati.
A differenza dei controlli di accesso, il data masking presume che l’accesso avverrà. Invece di bloccare le query, controlla ciò che gli utenti vedono nei risultati delle query. Questo approccio riduce il rischio senza interrompere l’uso normale del database.
Tecniche Native di Data Masking in MariaDB
MariaDB non fornisce un framework dedicato e integrato di data masking. Invece, il masking è tipicamente approssimato usando costrutti SQL standard. Questi approcci possono essere utili per dimostrazioni, ambienti limitati o casi d’uso ristretti, ma si basano sulla disciplina manuale anziché su politiche applicate in modo automatico.
View con Colonne Trasformate
Una delle tecniche più comuni è esporre i dati mascherati tramite view SQL che trasformano le colonne sensibili prima di restituire i risultati.
/*CREATE VIEW masked_customers AS
SELECT
id,
CONCAT(SUBSTRING(email, 1, 3), '***@***') AS email,
'****-****-****' AS card_number
FROM customers;*/
In questo modello, le applicazioni e gli utenti dovrebbero interrogare la view invece della tabella sottostante. La logica di trasformazione è incorporata direttamente nella definizione della view, che lega strettamente il comportamento di masking al design dello schema e all’instradamento delle query. Di conseguenza, la protezione dei dati dipende da modelli di utilizzo costanti piuttosto che da controlli imposti.

Limitazioni
- Efficace solo se tutti gli accessi sono rigorosamente indirizzati tramite la view
- Non protegge l’accesso diretto alle tabelle o query ad-hoc
- Richiede manutenzione continua con l’evolversi degli schemi
- Diventa difficile da gestire su molte tabelle e database
Funzioni Stored per Masking Condizionale
Un altro approccio è utilizzare funzioni stored per incapsulare la logica di masking e applicarla condizionalmente in base al contesto utente o a variabili di sessione.
/*CREATE FUNCTION mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
DETERMINISTIC
RETURN CONCAT(SUBSTRING(email, 1, 3), '***@***');*/
Questa funzione può quindi essere richiamata in istruzioni SELECT o view, permettendo di riutilizzare la stessa logica di masking in più query. In configurazioni più complesse, può essere introdotta una logica aggiuntiva per variare il comportamento del masking in base all’utente connesso o al ruolo. Tuttavia, l’applicazione rimane totalmente dipendente da come le query sono scritte ed eseguite.
Limitazioni
- Richiede un uso disciplinato e coerente delle query
- La logica di masking deve essere applicata manualmente ovunque serva
- Nessuna applicazione o visibilità centralizzata
- Facile da bypassare interrogando direttamente le tabelle base
Copie Separate Mascherate dei Dati
Per ambienti non di produzione come sviluppo o test, le organizzazioni spesso creano copie permanentemente mascherate dei dati di produzione.
/*CREATE TABLE customers_masked AS
SELECT
id,
SHA2(email, 256) AS email,
NULL AS card_number
FROM customers;*/
Questo approccio produce un dataset in cui i valori sensibili sono modificati in modo irreversibile, rendendolo più sicuro da condividere con sviluppatori o team esterni. Tuttavia, il processo di masking è scollegato dall’accesso ai dati live e deve essere ripetuto ogni volta che i dati vengono aggiornati.
Limitazioni
- Comporta duplicazione dei dati e un sovraccarico di storage aggiuntivo
- I dataset mascherati diventano obsoleti man mano che i dati di produzione cambiano
- Nessuna protezione per l’accesso in produzione o query live
- Le regole di masking devono essere riapplicate ogni volta che i dati vengono aggiornati
Pur potendo ridurre esposizioni accidentali in scenari limitati, queste tecniche native non offrono masking consistente, scalabile o controllabile. Con la crescita degli ambienti e la diversificazione degli schemi di accesso, affidarsi esclusivamente al masking SQL diventa sempre più fragile e difficile da governare.
Data Masking Centralizzato per MariaDB con DataSunrise
DataSunrise supera le soluzioni di masking a livello SQL di MariaDB introducendo un livello di sicurezza centralizzato e basato su politiche. Invece di incorporare la logica di masking in query, view o schemi, la piattaforma applica il masking esternamente. Di conseguenza, i team proteggono i dati senza modificare il codice applicativo né cambiare la struttura del database. Questo modello allinea naturalmente il masking con pratiche più ampie di sicurezza dei dati e sicurezza dei database.
Dynamic Data Masking
Il masking dinamico opera in tempo reale mentre le query sono in esecuzione. A seconda del contesto di esecuzione, la stessa colonna può apparire mascherata o meno. Pertanto, i team ottengono un controllo granulare sull’esposizione dei dati senza riscrivere SQL o mantenere schemi paralleli. In pratica, questo approccio implementa il dynamic data masking, dove la protezione resta completamente trasparente al momento della query.
DataSunrise valuta le decisioni di masking utilizzando segnali contestuali come utente o ruolo del database, indirizzo IP del client, origine dell’applicazione e attributi di sessione. Per questo motivo, gli analisti vedono i valori mascherati, le applicazioni continuano a processare i dati reali e gli amministratori mantengono visibilità completa. Tutto ciò funziona senza modifiche alle query o alla logica applicativa.
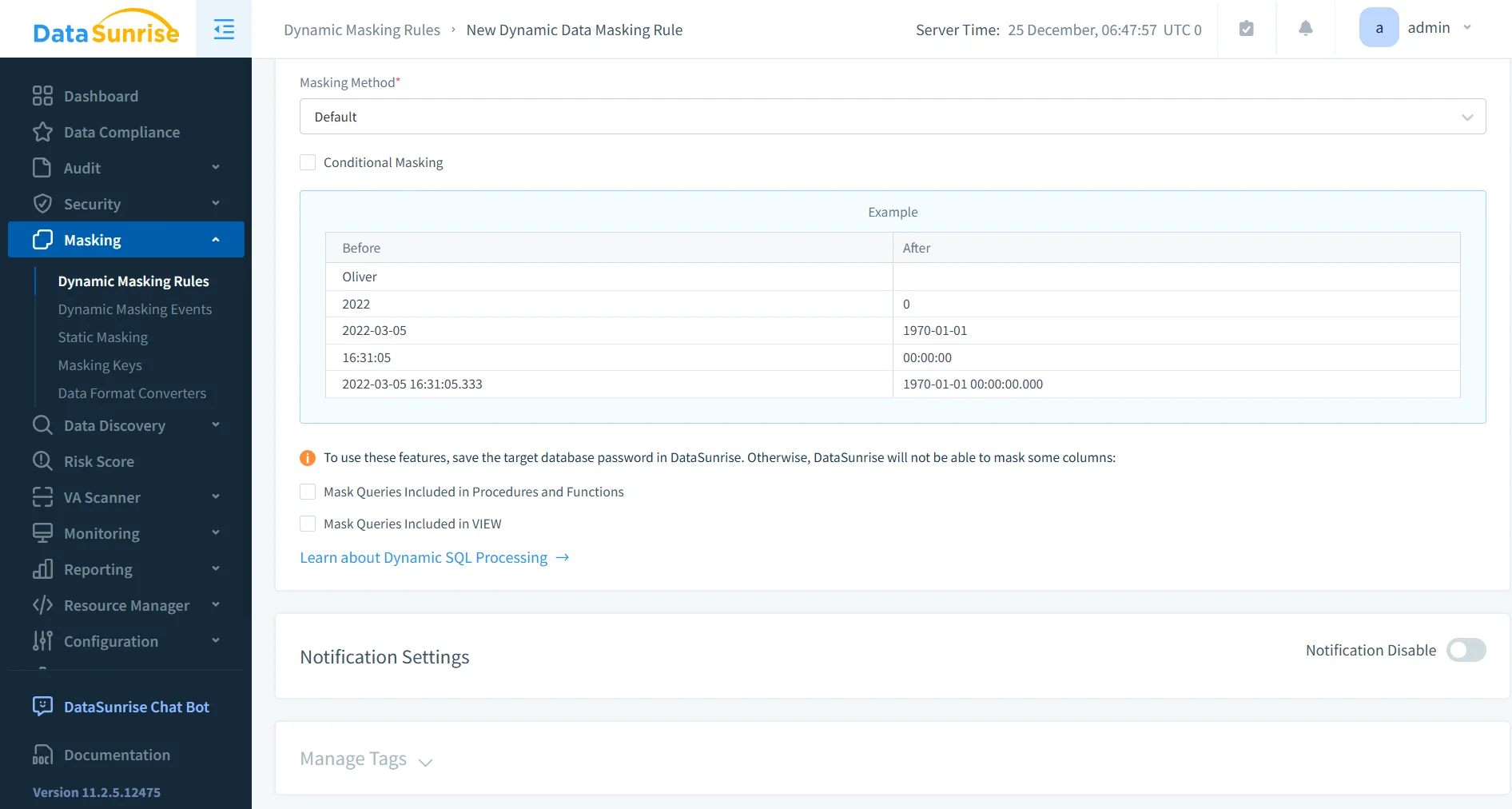
Masking Basato su Politiche per Tipo di Dato
Una volta che i team individuano e classificano i dati sensibili, DataSunrise applica automaticamente le regole di masking su schemi e database basandosi sul tipo di dato anziché su singole colonne. Questo approccio si basa su processi automatizzati di scoperta e classificazione dei dati. Di conseguenza, la protezione scala con la crescita degli ambienti.
Per esempio, la piattaforma sostituisce le email con formati validi ma casuali, tokenizza i numeri di telefono, applica hash irreversibili a identificatori e maschera valori finanziari usando sostituzioni che preservano il formato. Poiché le regole di masking seguono categorie di dati invece di definizioni rigide di schema, lo sforzo di manutenzione a lungo termine si riduce significativamente.
Masking Statico per Flussi di Lavoro Non di Produzione
Per scenari non di produzione come sviluppo, testing o analytics, DataSunrise supporta il masking statico controllato durante i flussi di lavoro operativi. Questi flussi includono clonazione del database, ripristino da backup, esportazione dati e provisioning di dati di test. In questo contesto, la piattaforma segue pratiche consolidate di static data masking che permettono ai team di riutilizzare in sicurezza i dati di produzione al di fuori di ambienti controllati.
Di conseguenza, i dataset mascherati restano coerenti, irreversibili e verificabili. Ciò li rende adatti a flussi di lavoro sensibili alla conformità senza esporre valori reali.
Operazioni di Masking Verificabili
DataSunrise registra tutta l’attività di masking in una cronologia unificata. Ogni evento cattura chi ha effettuato l’accesso ai dati, quale regola di masking è stata applicata e quando e da dove l’accesso è avvenuto. Pertanto, i team collegano direttamente i controlli di masking al monitoraggio delle attività del database e ai flussi di conformità.
Centralizzando l’applicazione, la visibilità e la gestione delle politiche, DataSunrise trasforma il data masking per MariaDB in un controllo consistente, scalabile e pronto per la conformità, piuttosto che in una raccolta di schemi fragili basati su SQL.
Benefici Aziendali del Data Masking Centralizzato
| Area Aziendale | Impatto |
|---|---|
| Riduzione del rischio di violazioni | Limita l’esposizione di valori sensibili anche in caso di accesso, riducendo l’impatto di minacce interne e uso improprio delle credenziali |
| Conformità normativa | Semplifica l’allineamento a GDPR, HIPAA, PCI DSS e SOX imponendo politiche di masking consistenti |
| Sicurezza di analisi e test | Consente l’uso di dati realistici in ambienti di analisi e test senza duplicare o esporre i dati di produzione |
| Visibilità operativa | Fornisce audit trail unificati che mostrano chi ha avuto accesso ai dati mascherati, quando e con quale politica |
| Manutenibilità a lungo termine | Elimina la logica di masking fragile e vincolata allo schema, riducendo lo sforzo di manutenzione continua |
Conclusione
MariaDB consente masking di base tramite tecniche SQL, ma questi approcci si basano sull’applicazione manuale e non scalano con l’aumento degli ambienti. Con l’aumento degli schemi di accesso e dei requisiti di conformità, essi non garantiscono protezione consistente né visibilità.
Piattaforme centralizzate come DataSunrise trasformano il data masking in un controllo basato su politiche, verificabile e consapevole del contesto, che opera indipendentemente dalla logica applicativa e dagli schemi. Questo rende il masking affidabile, applicabile e adatto ad ambienti regolamentati o con dati condivisi.
Per le organizzazioni che considerano MariaDB un’infrastruttura critica per produzione o conformità, il data masking dovrebbe essere un controllo di sicurezza consapevole, non una soluzione improvvisata.
