Come Trasferire i Dati del Database di Audit su AWS S3 e Leggerli Utilizzando il Servizio AWS Athena
Archiviazione Audit è una funzionalità opzionale del Task di Pulizia del Database di Audit in DataSunrise Database Security. Questa funzionalità consente a un amministratore dell’installazione DataSunrise di rimuovere i dati di audit più vecchi e di archiviarli nel servizio AWS S3, offrendo un modo migliore e più economico per memorizzare i dati scaduti. Con l’utilizzo del Servizio AWS Athena, il Team di Sicurezza e i Revisori Esterni possono esaminare i dati storici necessari per le verifiche e le indagini su incidenti. Inoltre, l’utilizzo dell’Archiviazione Audit permette ai clienti DataSunrise di mantenere dataset più ampi di eventi audit senza dover memorizzare tutto in un unico database di Archivio Audit, evitando così l’aumento dei tempi di reportistica. Inoltre, l’utilizzo di S3 per i dati “freddi” è una soluzione più economica, che può aiutare a ottimizzare il budget del progetto mantenendo sotto controllo le dimensioni del Database di Audit.
Per l’Archiviazione Audit, il team di DataSunrise fornisce uno script dedicato per le distribuzioni Linux che può essere configurato per spostare i dati rimossi in una posizione S3 personalizzabile. Lo script è incluso nel pacchetto di installazione predefinito di DataSunrise, quindi non è necessario scaricarlo altrove.
Questo articolo ti guiderà attraverso il processo di configurazione e del Task di Pulizia Audit, il trasferimento dei dati rimossi verso la posizione del Bucket S3 di tua scelta e l’impostazione dell’ambiente in AWS Athena per le analisi forensi.
Configura un Task di Pulizia dei Dati Audit con l’Opzione di Archiviazione Audit
- Apri il Web-UI di DataSunrise e naviga in Configurazione → Task Periodici. Clicca sul pulsante Nuovo Task e fornisci le informazioni generali come Nome, Tipo di Task (ad es. Pulizia Dati Audit), e seleziona il server sul quale eseguire il task, nel caso in cui si utilizzi un Cluster di nodi DataSunrise.
- Imposta le Opzioni di Archivio nella sezione Pulizia Dati Audit:
- Seleziona l’opzione Archive Removed Data before Cleaning.
- Specifica il percorso della Cartella di Archivio dove i dati di audit devono essere temporaneamente memorizzati prima di essere trasferiti su S3.
- Specifica il percorso dello script che carica i dati su AWS S3 utilizzando il campo di input “Execute Command After Archiving”. Percorso predefinito – /opt/datasunrise/scripts/aws/cf_upload_ds_audit_to_aws_s3.sh
(richiesto) - Fornisci parametri extra allo script per regolare il comportamento (vedi sotto gli argomenti opzionali dello script).
- Regola la Frequenza del Task nella sezione “Startup Frequency”, potrai impostare quanto spesso il task deve essere eseguito (ad es., giornalmente, settimanalmente, mensilmente) in base alle necessità dell’organizzazione per la conservazione e l’archiviazione dei dati di audit.
- Salva il task dopo aver configurato tutte le impostazioni necessarie.
- Avvia il task manualmente o automaticamente. Se l’utente ha configurato il task per l’avvio manuale, può avviarlo selezionando il task e cliccando su Start Now. Se invece è impostato per avviarsi in base a un programma, verrà eseguito automaticamente agli orari specificati.
- Dopo l’esecuzione del task, una cartella di archivio verrà creata sul filesystem del Server DataSunrise dove è stato eseguito il task (nelle distribuzioni Linux, il percorso predefinito sarà /opt/datasunrise/).
- –archive-folder: fornisci il tuo percorso personale sul Server DataSunrise in cui collocare i file dei dati di audit archiviati. Di default, la cartella ds-audit-archive verrà creata nella posizione /opt/datasunrise/. Non è necessario fornire questa opzione se definisci la cartella di Archivio Audit come ds-audit-archive all’interno della directory principale di installazione di DataSunrise.
- –folder-in-bucket: fornisci il tuo prefisso personale nel quale collocare i dati di audit. Di default, lo script scarica i dati nel prefisso
/ds-audit-archive . - –predefined-credentials: Nel caso in cui tu stia eseguendo DataSunrise al di fuori di AWS, per poter caricare i dati su S3, avrai bisogno di un file di credenziali oppure della coppia ACCESS/SECRET Key per l’Utente IAM autorizzato ad accedere al bucket S3 desiderato. Non richiede ulteriori input.
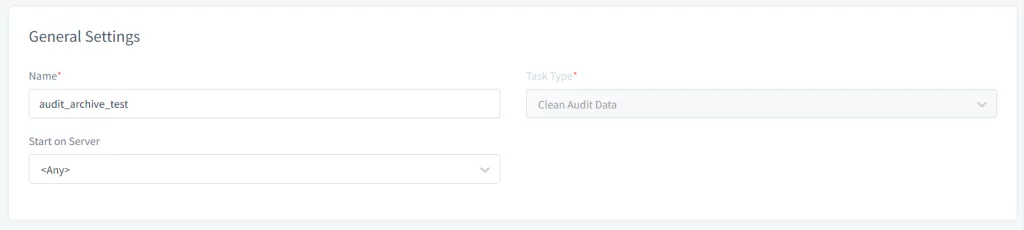
Immagine 1. Impostazioni Generali
Nota: se stai eseguendo DataSunrise su AWS ECS Fargate, utilizza invece il ecs_upload_ds_audit_to_aws_s3.sh situato nella stessa directory.
Nota: puoi fornire percorsi relativi alla cartella di installazione di DataSunrise (ad es. ./scripts/aws/cf_upload_ds_audit_to_aws_s3.sh
Nota: se fornisci il nome della Cartella di Archivio predefinito atteso dallo script (ad es. /ds-audit-folder), non è necessario specificarlo negli argomenti dello script.
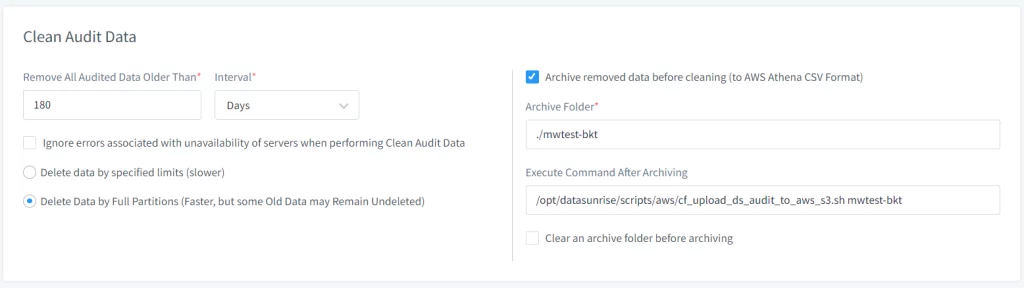
Immagine 2. Comandi Extra per il Task di Pulizia Audit
Immagine 3. Avvia il Task[/caption>
Nota: I passaggi sopra descritti possono essere utilizzati anche per gestire la conservazione dei dati di audit in DataSunrise; gli utenti possono utilizzare la funzionalità “Periodic Clean Audit” per rimuovere periodicamente i dati di audit obsoleti. Ciò garantisce l’efficienza del server DataSunrise evitando il sovraccarico di memorizzazione dovuto ai dati obsoleti.
Lo Script di Caricamento dei Dati di Audit Archiviati
Per caricare la cartella di archivio su un bucket AWS S3, utilizza lo script fornito da DataSunrise situato nella cartella
Per definire un bucket su cui inviare i dati di audit archiviati, fornisci il nome del tuo bucket AWS S3 senza lo schema s3://:
./scripts/aws/cf_upload_ds_audit_to_aws_s3.sh datasunrise-audit-archive
Per personalizzare il processo di archiviazione, puoi utilizzare i seguenti flag opzionali:
Nota: La dimensione della cartella viene monitorata durante lo scaricamento dei dati di audit e, quando supera una certa soglia, il comando viene eseguito. Se non viene specificato alcuno script, si verificherà un errore quando la soglia viene superata. La soglia viene impostata utilizzando il parametro aggiuntivo “AuditArchiveFolderSizeLimit”, con un valore predefinito di 1 GB. L’utente può pre-pulire una cartella di archivio utilizzando l’opzione “Clear an archive folder before archiving”.
Struttura della Cartella di Archivio Audit
La struttura della cartella di archivio in cui DataSunrise memorizza i dati di audit segue tipicamente un formato gerarchico organizzato per data. Questa organizzazione aiuta a gestire i dati in modo efficiente e rende più semplice individuare specifici record di audit in base alla data. Di seguito un esempio generale di come potrebbe essere la struttura:
Struttura Generale della Cartella (Template)
Directory Base: /opt/datasunrise/ds-audit-archive/
└── Anno: {YYYY}/
└── Mese: {MM}/
└── Giorno: {DD}/
└── File di Audit: audit_data_{YYYY}-{MM}-{DD}.csv.gz
Una volta che i dati di audit sono caricati su S3, la struttura viene preservata nello stesso modo in cui è stata archiviata sul Server DataSunrise:
[caption id="attachment_19654" align="alignnone" width="871"]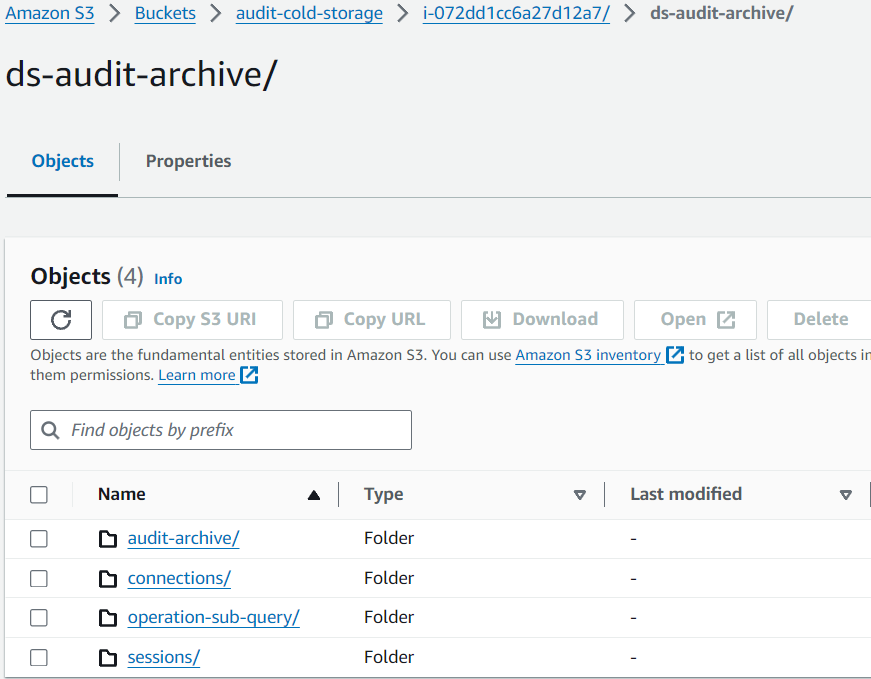 Immagine 4. Dati nel Bucket Amazon S3
Immagine 4. Dati nel Bucket Amazon S3Utilizzare AWS Athena per Leggere i Dati di Archivio Audit da S3
Una volta che i dati di audit sono stati caricati su S3, puoi creare lo schema del Database di Audit nel Servizio AWS Athena per ulteriori analisi. Accedi ad AWS Athena nella AWS Management Console per impostare un Database e le relative Tabelle per leggere i dati archiviati. Per poter utilizzare appieno il servizio AWS Athena, consigliamo di utilizzare la AmazonAthenaFullAccess AWS Managed IAM Policy per l’Utente IAM creato per lavorare con i dati di Audit archiviati.
Crea le Tabelle di Archivio Audit in AWS Athena
Gli script SQL assumono il seguente per la clausola LOCATION delle query CREATE EXTERNAL TABLE:
– Il nome del Bucket S3 è datasunrise-audit
Il file SQL DDL per le tabelle di Archivio Audit in AWS Athena è disponibile anche dalla distribuzione di DataSunrise al percorso predefinito: /opt/datasunrise/scripts/aws/aws-athena-create-audit-archive-tables.sql.
CREATE DATABASE IF NOT EXISTS datasunrise_audit;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.audit_archive (
operations__id STRING,
operations__session_id STRING,
operations__begin_time STRING,
operations__end_time STRING,
operations__type_name STRING,
operations__sql_query STRING,
operations__exec_count STRING,
sessions__user_name STRING,
sessions__db_name STRING,
sessions__service_name STRING,
sessions__os_user STRING,
sessions__application STRING,
sessions__begin_time STRING,
sessions__end_time STRING,
connections__client_host_name STRING,
connections__client_port STRING,
connections__server_port STRING,
connections__sniffer_id STRING,
connections__proxy_id STRING,
connections__db_type_name STRING,
connections__client_host STRING,
connections__server_host STRING,
connections__instance_id STRING,
connections__instance_name STRING,
operation_rules__rule_id STRING,
operation_rules__rule_name STRING,
operation_rules__chain STRING,
operation_rules__action_type STRING,
operation_exec__row_count STRING,
operation_exec__error STRING,
operation_exec__error_code STRING,
operation_exec__error_text STRING,
operation_group__query_str STRING,
operations__operation_group_id STRING,
operations__all_exec_have_err STRING,
operations__total_affected_rows STRING,
operations__duration STRING,
operations__type_id STRING,
connections__db_type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/audit-archive/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La query seguente carica le partizioni per poter interrogare i dati.
MSCK REPAIR TABLE datasunrise_audit.audit_archive;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.sessions (
partition_id STRING,
id STRING,
connection_id STRING,
host_name STRING,
user_name STRING,
scheme STRING,
application STRING,
thread_id STRING,
process_id STRING,
begin_time STRING,
end_time STRING,
error_str STRING,
params STRING,
db_name STRING,
service_name STRING,
os_user STRING,
external_user STRING,
domain STRING,
realm STRING,
sql_state STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/sessions/'
TBLPROPERTIES ('has_encrypted_data'='false','skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.sessions;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.connections (
partition_id STRING,
id STRING,
interface_id STRING,
client_host STRING,
client_port STRING,
begin_time STRING,
end_time STRING,
client_host_name STRING,
instance_id STRING,
instance_name STRING,
proxy_id STRING,
sniffer_id STRING,
server_host STRING,
server_port STRING,
db_type_id STRING,
db_type_name STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/connections/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.connections;
----------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.operation_sub_query (
operation_sub_query__operation_id STRING,
operation_sub_query__session_id STRING,
operation_sub_query__type_name STRING,
operations__begin_time STRING,
operation_sub_query__type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/operation-sub-query/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.operation_sub_query;
----------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.col_objects (
operation_id STRING,
session_id STRING,
obj_id STRING,
name STRING,
tbl_id STRING,
operations__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/col-objects/' -- percorso della cartella S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.col_objects;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.tbl_objects (
tbl_objects__operation_id STRING,
tbl_objects__session_id STRING,
tbl_objects__obj_id STRING,
tbl_objects__sch_id STRING,
tbl_objects__db_id STRING,
tbl_objects__tbl_name STRING,
tbl_objects__sch_name STRING,
tbl_objects__db_name STRING,
operations__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/tbl-objects/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.tbl_objects;
Interroga i dati nella Console di AWS Athena utilizzando query SQL standard:
--esecuzione di SELECT contro la tabella audit_archive con filtri per anno, mese e giorno
SELECT * FROM audit_archive WHERE year = '2024' and month = '05' and day = '16';
--selezione di dati da più tabelle tramite clausola JOIN
SELECT
r.operations__type_name,
s.operation_sub_query__type_name,
r.operations__sql_query
FROM audit_archive AS r
JOIN operation_sub_query AS s
ON
r.operations__id = s.operation_sub_query__operation_id
AND
r.operations__session_id = s.operation_sub_query__session_id;
--Estrai 100 righe senza applicare filtri
select * from audit_archive LIMIT 100;
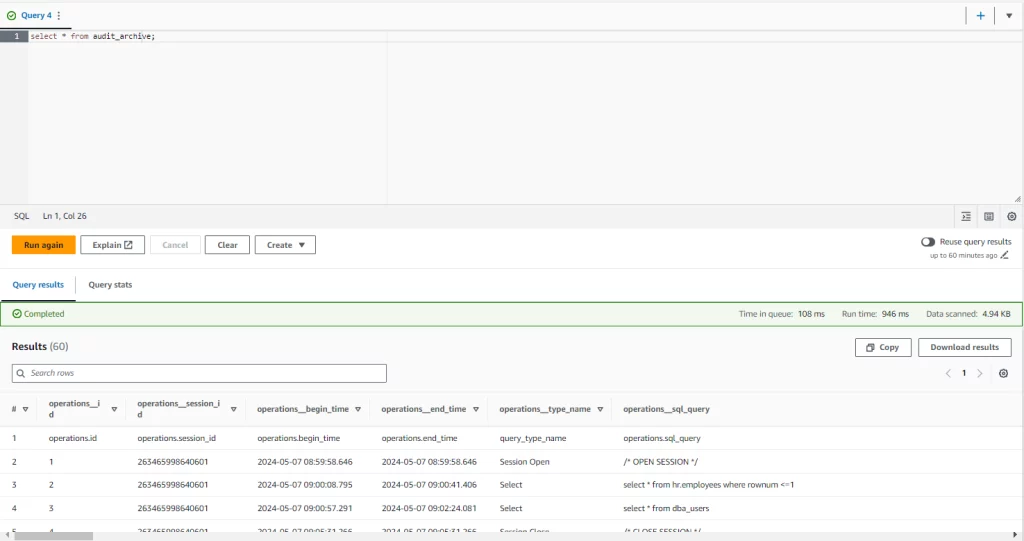
Immagine 5. Archivio Audit
Conclusione
Un lungo periodo di conservazione per dati sensibili come gli eventi di audit può rappresentare una vera sfida e un onere aggiuntivo sul budget per mantenere dataset di grandi dimensioni all’interno dei file del Database. L’Archiviazione Audit di DataSunrise offre una soluzione efficiente e sicura per mantenere i dati più vecchi leggibili, alleggerendo il livello di Storage del Database e offrendo ai nostri clienti una soluzione resiliente ed economica basata sui Servizi AWS S3 e Athena, per conservare i dati vecchi all’interno della tua Organizzazione e renderli accessibili per audit e conformità.