Mascheramento Statico dei Dati in Vertica
Il mascheramento statico dei dati in Vertica svolge un ruolo fondamentale nella protezione dei dati sensibili utilizzati per analisi ad alte prestazioni, reporting, data science e carichi di lavoro analitici su larga scala. Gli ambienti Vertica si basano spesso su dataset di livello produttivo contenenti informazioni personali identificabili, registri finanziari e altri tipi di dati regolamentati. Quando i team copiano questi dati al di fuori di sistemi di produzione strettamente controllati, il profilo di rischio complessivo aumenta immediatamente.
Questo approccio affronta l’esposizione trasformando in modo permanente i valori sensibili prima che i team riutilizzino i dati per sviluppo, test, analisi o flussi di lavoro di condivisione. A differenza dei controlli a runtime, il mascheramento irreversibile rimuove completamente i valori originali, garantendo che le informazioni sensibili non escano mai dai confini protetti.
Questo articolo spiega come il mascheramento irreversibile si applichi ai carichi di lavoro Vertica, dove le tecniche native basate su SQL non sono sufficienti, e come DataSunrise fornisca controlli di mascheramento centralizzati e auditabili su larga scala.
Perché il Mascheramento dei Dati è Importante per le Analisi Vertica
Le implementazioni Vertica supportano comunemente molteplici consumatori downstream, inclusi strumenti BI, data scientist, appaltatori esterni e pipeline automatizzate. Anche quando gli amministratori configurano correttamente i controlli di accesso, copiare dati analitici grezzi in sistemi non produttivi introduce rischi di esposizione inevitabili.
Il mascheramento irreversibile mitiga questi rischi garantendo che i dataset esportati o clonati non contengano valori reali sensibili. Gli ambienti regolamentati soggetti a GDPR, HIPAA o PCI DSS spesso richiedono la trasformazione permanente come misura di conformità e non solo come raccomandazione.
Vertica si concentra sulle prestazioni analitiche, non sulla logica di trasformazione a livello di riga. Di conseguenza, gli approcci nativi si basano tipicamente su script SQL personalizzati, riscritture manuali e processi operativi fragili.
Tecniche Native di Trasformazione dei Dati e i Loro Limiti
Vertica non offre primitive integrate per il mascheramento irreversibile. I team solitamente si affidano ad aggiornamenti basati su SQL o pipeline di esportazione per sostituire manualmente i valori sensibili.
Gli approcci nativi comuni includono:
- Aggiornare colonne con valori trasformati usando istruzioni
UPDATE - Creare copie anonime di tabelle per usi non produttivi
- Applicare funzioni di hashing irreversibile o sostituzione di stringhe
Nonostante queste tecniche funzionino in ambienti piccoli, introducono problemi operativi costanti:
- Mancanza di visibilità centralizzata sulle colonne trasformate
- Assenza di politiche riutilizzabili tra schemi o ambienti
- Nessuna traccia di audit che indichi quando sono avvenute le trasformazioni o chi le ha avviate
- Elevato overhead operativo durante le modifiche allo schema
Su larga scala, i flussi di lavoro di trasformazione manuale diventano difficili da controllare e ancor più difficili da auditare.
Come DataSunrise Applica il Mascheramento Irreversibile per Vertica
DataSunrise aggiunge un livello di controllo esterno che applica trasformazioni permanenti senza modificare schemi Vertica o logiche applicative. Gli amministratori definiscono regole di mascheramento in modo centrale e le applicano coerentemente durante flussi di lavoro controllati come copia, clonazione o esportazione dei dati.
Questo modello allinea la trasformazione dei dati con strategie più ampie di sicurezza dei dati e sicurezza del database.
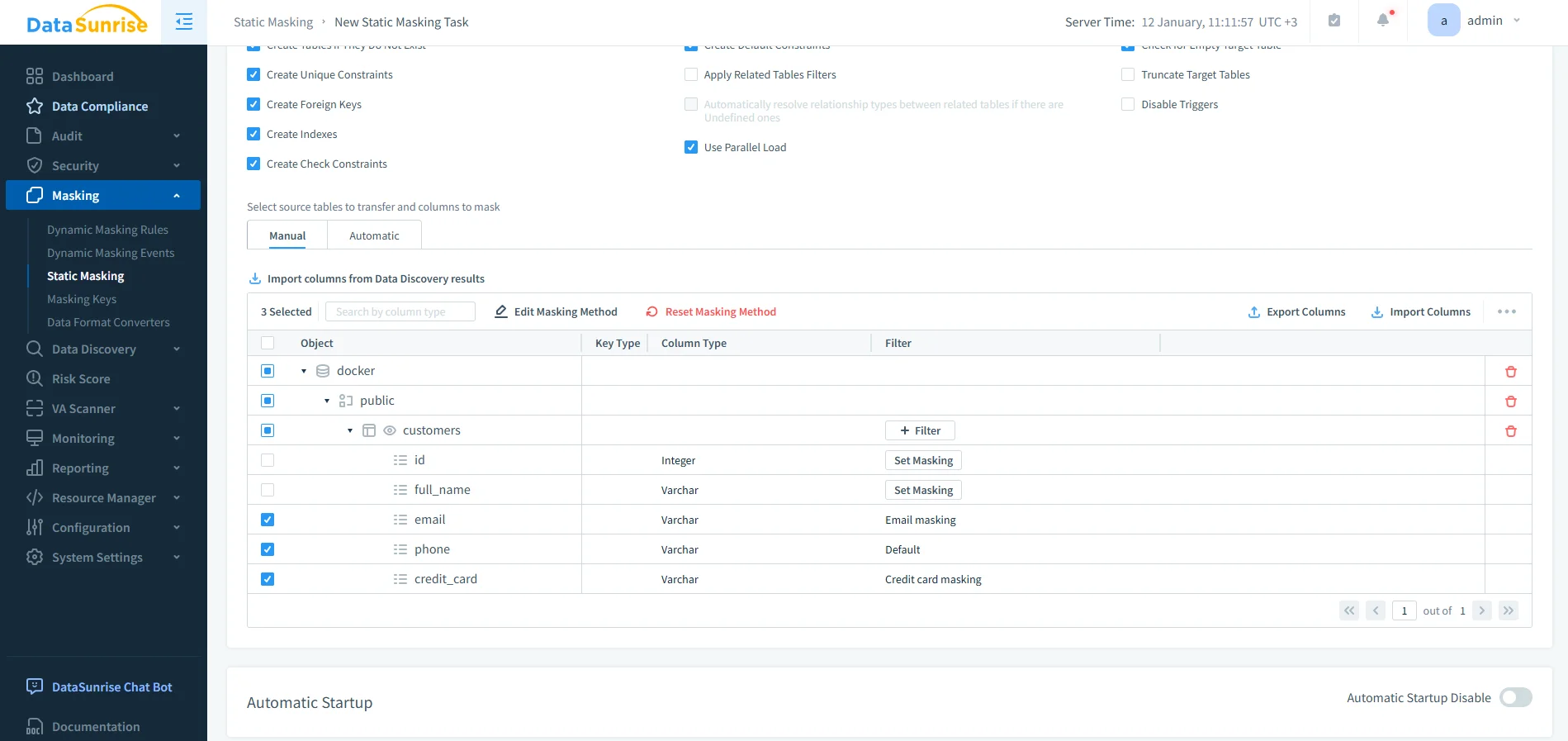
Identificazione delle Colonne Basata su Politiche
Invece di selezionare manualmente i singoli campi, DataSunrise si integra con il data discovery per identificare automaticamente le colonne sensibili in Vertica. Dopo la classificazione, le regole di trasformazione si applicano in modo coerente tra gli schemi.
Questo approccio elimina la dipendenza dalle convenzioni di denominazione e riduce il rischio di lasciare nuove colonne non protette.
Trasformazioni Synthetic e Conservanti il Formato
Le trasformazioni permanenti supportano diversi metodi in base al tipo di dato e ai requisiti analitici:
- Sostituzione delle email con indirizzi sintetici validi
- Tokenizzazione dei numeri di telefono
- Hashing irreversibile per identificatori
- Mascheramento delle carte di credito mantenendo lunghezza e struttura
Queste trasformazioni preservano l’utilizzabilità analitica eliminando l’esposizione dei dati reali.
Esecuzione Controllata e Sicurezza delle Prestazioni
Le attività di trasformazione vengono eseguite come operazioni controllate con elaborazione parallela opzionale. Questo design consente di processare dataset Vertica di grandi dimensioni in modo efficiente senza impattare i carichi di lavoro analitici di produzione.
Risultati Validati Dopo la Trasformazione dei Dati
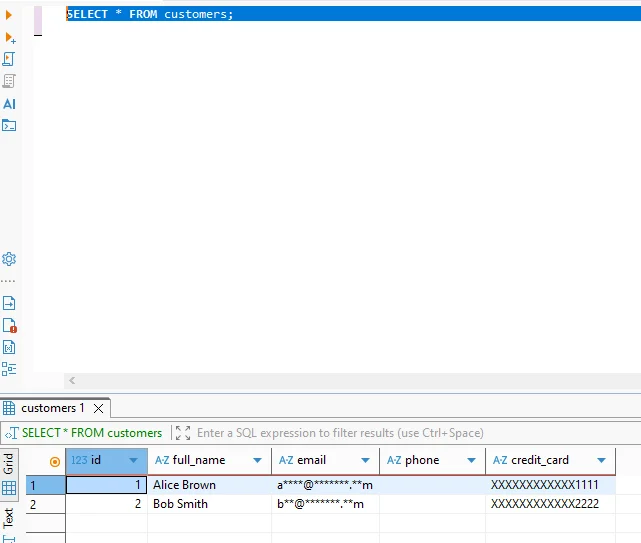
Dopo il completamento del processo, Vertica conserva tutti i campi sensibili in forma trasformata. Le query sul dataset risultante non restituiscono valori originali, nemmeno agli utenti privilegiati.
La seguente query dimostra come appaiono i dati mascherati quando si interroga una tabella Vertica dopo trasformazione irreversibile:
SELECT * FROM customers;
Poiché la trasformazione è irreversibile, questi dataset rimangono sicuri per analisi, ambienti di QA e condivisione esterna dei dati.
Audit e Trasparenza Operativa
Ogni operazione di trasformazione genera record di audit. Questi registri catturano:
- Quali tabelle e colonne sono state processate
- Quali metodi di trasformazione sono stati applicati
- Quando è stata eseguita l’attività
- Chi ha avviato l’operazione
Questa visibilità si integra direttamente con il monitoraggio delle attività del database e i log di audit, rendendo la trasformazione dei dati difendibile durante le verifiche.
Trasformazione Permanente vs Mascheramento a Runtime in Vertica
I team spesso confondono la trasformazione irreversibile con il mascheramento a runtime, ma ciascuno ha uno scopo diverso.
Il mascheramento permanente modifica i valori memorizzati, mentre il mascheramento a runtime applica trasformazioni al momento della query.
Le tecniche irreversibili sono più adatte quando:
- I dati escono dagli ambienti di produzione
- La conformità richiede l’anonimizzazione
- L’analisi ad alte prestazioni deve evitare il sovraccarico a runtime
Allineamento alla Conformità per gli Ambienti Vertica
| Regolamento | Requisito | Ruolo della Trasformazione |
|---|---|---|
| GDPR | Anonimizzazione irreversibile dei dati personali | Rimozione permanente degli identificatori |
| HIPAA | De-identificazione delle informazioni sanitarie protette (PHI) | Riutilizzo sicuro dei dataset sanitari |
| PCI DSS | Protezione dei dati dei titolari di carta | Mascheramento dei dati per analisi e test |
| SOX | Accesso controllato ai registri finanziari | Reporting non produttivo sicuro |
Questi controlli si integrano naturalmente con i flussi di lavoro supportati dal DataSunrise Compliance Manager.
Conclusione: Considerare il Mascheramento Irreversibile come Controllo Fondamentale
Il mascheramento irreversibile dei dati in Vertica non è un miglioramento opzionale. È un controllo fondamentale per operazioni analitiche sicure. Gli script SQL manuali possono funzionare temporaneamente, ma falliscono su larga scala, sotto la lente degli audit e con requisiti di conformità in evoluzione.
Centralizzando i flussi di lavoro di trasformazione con DataSunrise, le organizzazioni ottengono un’applicazione coerente, una chiara auditabilità e l’allineamento con le moderne normative sulla conformità dei dati. Il mascheramento diventa un processo regolamentato anziché una frag ile raccolta di script.
Se il tuo ambiente Vertica supporta molteplici consumatori downstream, il mascheramento permanente dovrebbe già far parte della tua architettura. Se non è così, non è coraggio — è rischio non gestito.
