
Come Implementare il Mascheramento Statico dei Dati in Amazon DynamoDB
Introduzione
Nel 2022, le soluzioni basate su cloud hanno rappresentato il 53% del mercato globale del software DLP, con una crescita complessiva del mercato che ha mostrato un’espansione non lineare. Amazon DynamoDB, un popolare servizio di database NoSQL, memorizza grandi quantità di dati, inclusi potenzialmente dati sensibili. Il mascheramento statico dei dati offre una soluzione potente per proteggere questi dati. Esploriamo come il mascheramento statico dei dati può essere implementato per Amazon DynamoDB, concentrandoci su tecniche e strumenti pratici.
I principali fornitori di DLP stanno dando priorità allo sviluppo di soluzioni native per il cloud e compatibili con il cloud per rispondere alla crescente domanda. In DataSunrise, siamo sintonizzati con queste tendenze del settore e offriamo soluzioni all’avanguardia progettate per proteggere efficacemente le infrastrutture di dati basate su cloud.
Comprendere il Mascheramento Statico dei Dati
Il mascheramento statico dei dati è una tecnica di sicurezza che sostituisce i dati sensibili con informazioni realistiche ma fittizie. A differenza del mascheramento dinamico, che avviene in tempo reale, il mascheramento statico altera permanentemente i dati a riposo. Questo approccio è ideale per creare ambienti sicuri e non di produzione per test e sviluppo.
Vantaggi del Mascheramento Statico dei Dati
- Sicurezza dei dati migliorata
- Conformità con le regolamentazioni sulla protezione dei dati
- Riduzione del rischio di violazioni dei dati
- Ambiente sicuro per sviluppo e test
Capacità di Mascheramento Nativo in Amazon DynamoDB
Amazon DynamoDB offre capacità di mascheramento native, che abbiamo trattato nei nostri articoli precedenti sul mascheramento e sul mascheramento dinamico per DynamoDB. Queste funzionalità consentono di elaborare i risultati delle query dopo aver recuperato i dati utilizzando l’API Python o CLI.
Implementare il Mascheramento Statico dei Dati con Python e Boto3
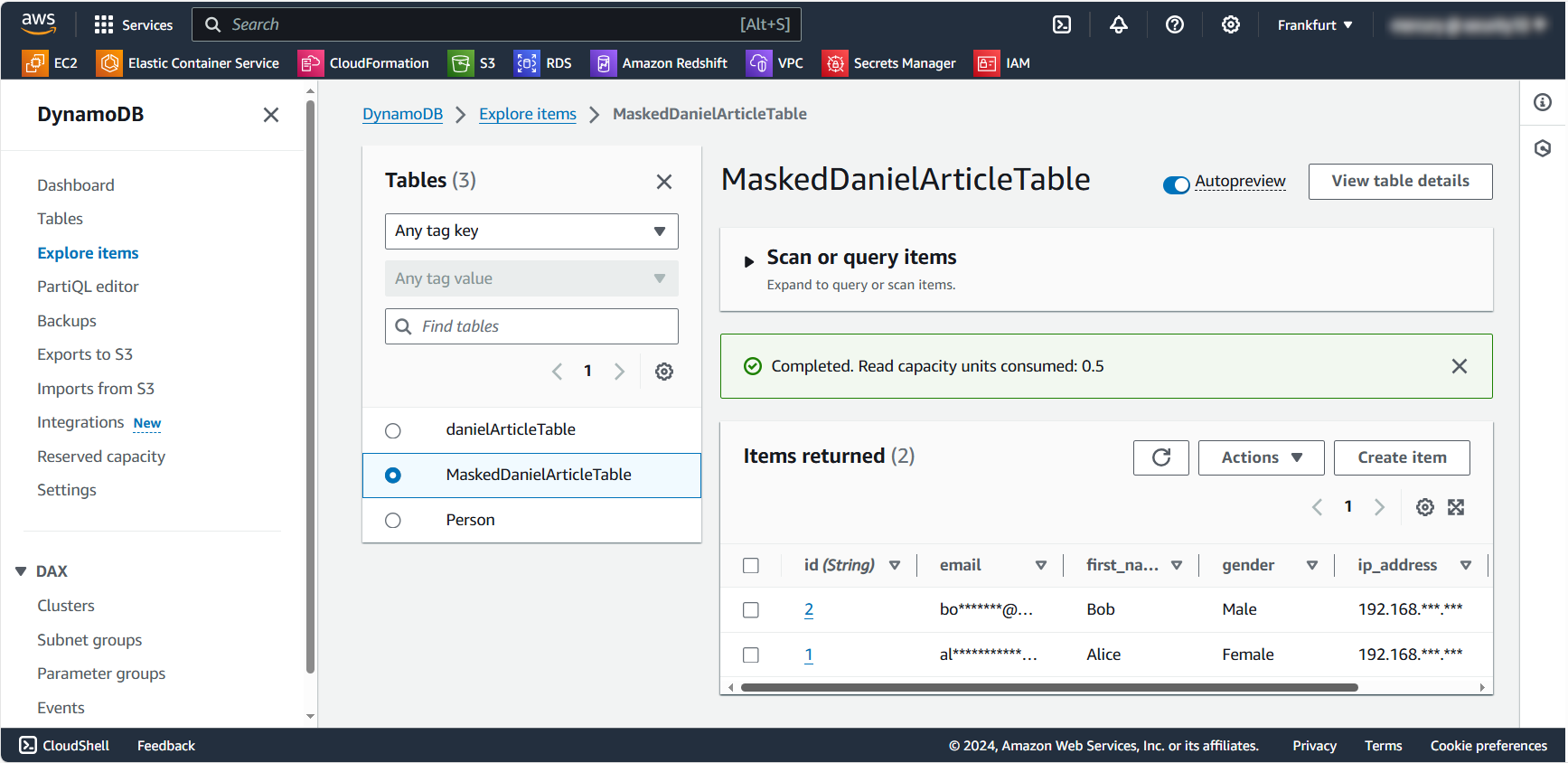
Esploriamo un esempio pratico di mascheramento statico dei dati utilizzando Python e la libreria Boto3. Connetteremo il database, creeremo una copia dei dati (tabella MaskedDanielArticleTable) e maschereremo informazioni sensibili come indirizzi email e IP.
import boto3
from boto3.dynamodb.conditions import Key
import time
# Connessione a DynamoDB
dynamodb = boto3.resource('dynamodb')
source_table = dynamodb.Table('danielArticleTable')
# Creare la tabella mascherata
try:
masked_table = dynamodb.create_table(
TableName='MaskedDanielArticleTable',
KeySchema=[
{'AttributeName': 'id', 'KeyType':'HASH'},
],
AttributeDefinitions=[
{'AttributeName': 'id', 'AttributeType': 'S'},
],
ProvisionedThroughput={
'ReadCapacityUnits':5,
'WriteCapacityUnits':5
}
)
print("Creazione della tabella mascherata in corso...")
masked_table.meta.client.get_waiter('table_exists').wait(TableName='MaskedDanielArticleTable')
print("Tabella mascherata creata con successo")
except dynamodb.meta.client.exceptions.ResourceInUseException:
print("Tabella mascherata già esistente")
masked_table = dynamodb.Table('MaskedDanielArticleTable')
# Funzione per mascherare l'email
def mask_email(email):
username, domain = email.split('@')
masked_username = username[:2] + '*' * (len(username) - 2)
return f"{masked_username}@{domain}"
# Funzione per mascherare l'indirizzo IP
def mask_ip(ip):
octets = ip.split('.')
masked_octets = octets[:2] + ['***', '***']
return '.'.join(masked_octets)
# Scansione della tabella sorgente
response = source_table.scan()
items = response['Items']
# Mascheramento e copia dei dati
for item in items:
masked_item = item.copy()
if 'email' in masked_item:
masked_item['email'] = mask_email(masked_item['email'])
if 'ip_address' in masked_item:
masked_item['ip_address'] = mask_ip(masked_item['ip_address'])
# Inserimento dell'elemento mascherato nella nuova tabella
masked_table.put_item(Item=masked_item)
print("Mascheramento statico dei dati completato.")
L’output (eseguito in Jupyter Notebook) è il seguente:
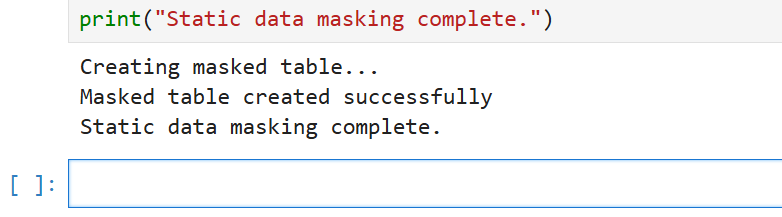
Questo script dimostra un approccio di base al mascheramento statico dei dati. Crea una nuova tabella con dati mascherati, garantendo che le informazioni sensibili originali rimangano protette.
Prima di procedere, è importante affrontare alcuni punti chiave riguardanti il codice fornito. La natura dello schema flessibile di DynamoDB presenta sfide uniche per il mascheramento statico dei dati automatizzato. Esaminiamo queste complessità:
- Diversi elementi nella stessa tabella possono avere attributi diversi.
- Nuovi attributi possono essere aggiunti agli elementi in qualsiasi momento senza dover modificare la struttura della tabella.
Per affrontare queste sfide:
- Implementare regole di mascheramento flessibili che possono adattarsi a strutture di dati variabili.
- Utilizzare tecniche di pattern matching o di apprendimento automatico per identificare dati potenzialmente sensibili.
- Mantenere un catalogo completo dei pattern e delle posizioni dei dati sensibili.
- Utilizzare tecniche di campionamento per gestire grandi insiemi di dati in modo efficiente.
Mascheramento Statico dei Dati con DataSunrise
La versione attuale di DataSunrise (10.0) offre un mascheramento dinamico completo per DynamoDB, ma non supporta il mascheramento statico per questo database. Per una panoramica completa dei database e delle funzionalità supportate, consultare il capitolo 1.2, ‘Database e Funzionalità Supportati,’ nella nostra documentazione. Di conseguenza, le istanze di DynamoDB non sono disponibili per la selezione nelle liste dei database di origine e destinazione durante l’impostazione di un’attività di mascheramento statico.
Best Practices per il Mascheramento Statico dei Dati in DynamoDB
Per massimizzare l’efficacia dei vostri sforzi di mascheramento statico dei dati:
- Identificare tutti gli attributi di dati sensibili
- Utilizzare tecniche di mascheramento realistiche per mantenere l’usabilità dei dati
- Aggiornare regolarmente le regole di mascheramento per affrontare nuovi tipi di dati
- Implementare controlli di accesso per i dati mascherati
- Audit dei processi di mascheramento per garantirne l’efficacia
Sfide e Considerazioni
Sebbene il mascheramento statico dei dati offra significativi vantaggi, è importante considerare le potenziali sfide:
- Impatto sulle prestazioni durante il processo di mascheramento
- Mantenere l’integrità referenziale nei dataset mascherati
- Garantire che i dati mascherati rimangano utili per test e sviluppo
- Mantenere aggiornate le regole e i compiti di mascheramento con le strutture di dati in evoluzione
Conclusione
Il mascheramento statico dei dati per Amazon DynamoDB offre uno strumento potente per proteggere le informazioni sensibili. Implementando tecniche di mascheramento robuste, le organizzazioni possono ridurre significativamente il rischio di violazioni dei dati e garantire la conformità con le regolamentazioni sulla protezione dei dati.
Che si utilizzino le funzionalità native di DynamoDB, script Python personalizzati o strumenti specializzati, il mascheramento statico dei dati offre un approccio flessibile ed efficace per salvaguardare i vostri preziosi asset di dati.
DataSunrise offre una suite completa di strumenti di sicurezza per database, inclusi avanzati strumenti di audit e conformità. Le nostre soluzioni all’avanguardia offrono opzioni flessibili e potenti per proteggere i vostri dati sensibili attraverso varie piattaforme di database. Visitate il nostro sito web per programmare una demo online e per esplorare come DataSunrise può migliorare la vostra strategia di sicurezza dei dati.
Successivo
