Offuscamento dei Dati in Apache Cloudberry
Implementare un robusto offuscamento dei dati per Apache Cloudberry è diventato essenziale per le organizzazioni che gestiscono informazioni sensibili. Secondo il Rapporto IBM 2024 sul costo delle violazioni dei dati, le organizzazioni che adottano un masking completo dei dati riducono i costi legati alle violazioni fino al 68% e rilevano gli incidenti di sicurezza con una velocità superiore del 76%.
Apache Cloudberry, un database open-source MPP (Massively Parallel Processing) realizzato su PostgreSQL, gestisce analisi su larga scala e data warehousing. Man mano che le organizzazioni elaborano dati sensibili attraverso Cloudberry, un’efficace offuscamento diventa cruciale per proteggere PII, dati finanziari e contenuti regolamentati, mantenendo al contempo l’utilità analitica.
Con costi medi di violazione pari a 4,88 milioni di dollari nel 2024 e normative di conformità come GDPR, HIPAA e PCI DSS che richiedono un rigoroso rispetto, i soli controlli di accesso non sono sufficienti. Questa guida esplora le funzionalità native di offuscamento di Apache Cloudberry e dimostra come DataSunrise migliori la protezione dei dati con il Data Masking Zero-Touch.
Comprendere l’Offuscamento dei Dati in Apache Cloudberry
L’offuscamento dei dati in Apache Cloudberry comprende tecniche per rendere i dati sensibili illeggibili, mantenendo però l’utilità analitica. A differenza della crittografia dei database, l’offuscamento altera permanentemente i dati per proteggere la privacy, preservando nel contempo le proprietà statistiche.
Tecniche principali di offuscamento per Cloudberry
Data Masking: Sostituzione dei valori sensibili con alternative realistiche. Esempio: “[email protected]” diventa “[email protected]”.
Tokenizzazione: Sostituzione dei dati con token casuali. La carta di credito “4532-1234-5678-9010” diventa “TKN-8923-4571-2089”.
Anonymizzazione: Rimozione degli attributi identificativi. L’indirizzo “123 Main Street, Boston, MA 02108” diventa “Boston, MA”.
Pseudonimizzazione: Uso di identificatori artificiali mantenendo il collegamento tra i dati. “SSN-123-45-6789” si trasforma in “CUST-A7B2C9D4”.
Data Perturbation: Aggiunta di rumore statistico ai valori numerici preservando le analisi aggregate.
Considerazioni uniche per l’offuscamento in Apache Cloudberry
L’architettura MPP di Cloudberry richiede:
- Offuscamento coerente tra i nodi dei segmenti distribuiti
- Prestazioni inferiori al secondo su scala di miliardi di righe
- Preservazione delle relazioni di chiavi esterne e integrità referenziale
- Mantenimento delle proprietà statistiche per l’intelligenza aziendale
- Consapevolezza del contesto utente senza modifiche all’applicazione
Funzionalità native di offuscamento dati in Apache Cloudberry
Apache Cloudberry eredita capacità di base di offuscamento da PostgreSQL, sebbene queste richiedano una configurazione manuale significativa e manchino di automazione per la scoperta dei dati.
1. Controllo degli accessi basato sui ruoli per l’offuscamento
Implementare controlli di accesso basati sui ruoli con funzioni di masking personalizzate:
-- Creare funzione di masking
CREATE OR REPLACE FUNCTION mask_ssn(ssn TEXT)
RETURNS TEXT AS $$
BEGIN
RETURN 'XXX-XX-' || RIGHT(ssn, 4);
END;
$$ LANGUAGE plpgsql IMMUTABLE;
-- Creare vista di masking condizionale
CREATE VIEW financial_records_view AS
SELECT record_id, customer_name,
CASE WHEN current_user IN ('auditor')
THEN ssn ELSE mask_ssn(ssn) END AS ssn
FROM financial_records;
2. Testare l’implementazione dell’offuscamento
-- Creare tabella di test
CREATE TABLE patient_records (
patient_id SERIAL PRIMARY KEY,
full_name VARCHAR(100),
diagnosis VARCHAR(200)
) DISTRIBUTED BY (patient_id);
-- Creare vista offuscata
CREATE VIEW patient_records_research AS
SELECT patient_id,
'Patient-' || patient_id AS patient_identifier,
LEFT(diagnosis, 20) || '...' AS diagnosis_category
FROM patient_records;
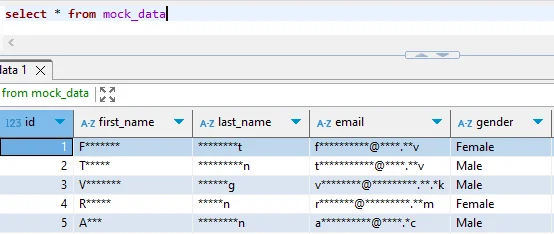
Limitazioni dell’offuscamento dati nativo di Cloudberry
| Funzionalità Nativa | Principale Limitazione | Impatto sul Business |
|---|---|---|
| Masking basato su estensioni | Configurazione manuale per colonna | Sovraccarico per gli sviluppatori, copertura incoerente |
| Offuscamento basato su viste | Regole statiche senza adattamento | Impossibilità di adeguarsi a requisiti variabili |
| Impatto sulle prestazioni | Sovraccarico di esecuzione funzioni | Rallentamenti nelle query su grandi dataset |
| Contesto utente | Differenziazione ruoli limitata | Granularità insufficiente |
| Automazione | Nessuna scoperta dati automatica | Dati critici potrebbero rimanere non protetti |
| Mappatura conformità | Nessun template regolatorio | Configurazione manuale dispendiosa |
Offuscamento dati migliorato con DataSunrise
DataSunrise potenzia le capacità di Cloudberry tramite Auto-Discover & Mask e Intelligent Policy Orchestration, offrendo dynamic data masking di livello enterprise con implementazione Zero-Touch. A differenza degli approcci di masking statico, DataSunrise garantisce protezione in tempo reale.
Configurazione di DataSunrise per Apache Cloudberry
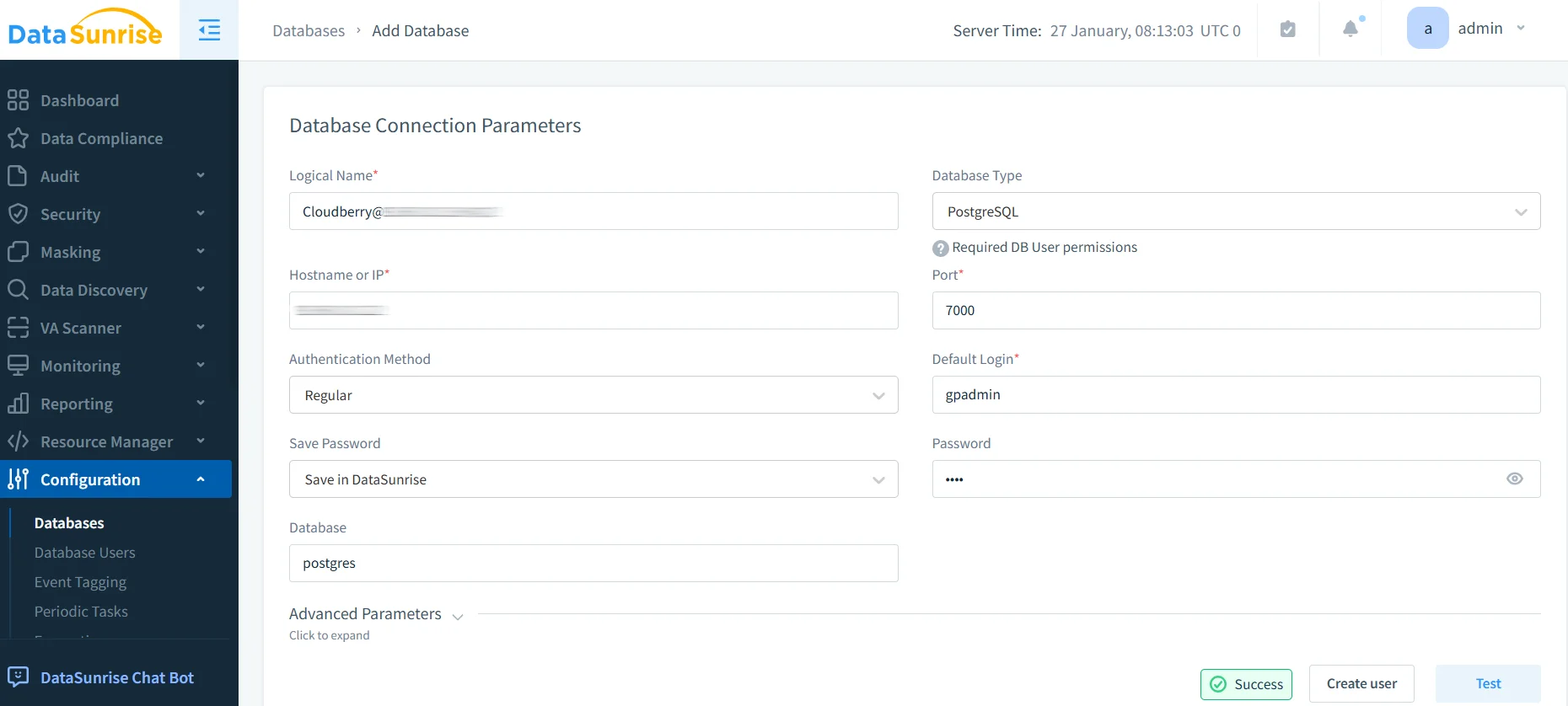
1. Collegarsi all’istanza Apache Cloudberry
Stabilire una connessione sicura tramite l’interfaccia di DataSunrise. DataSunrise supporta più modalità di deployment inclusi proxy, sniffer e analisi nativa dei log per il monitoraggio dell’attività del database.
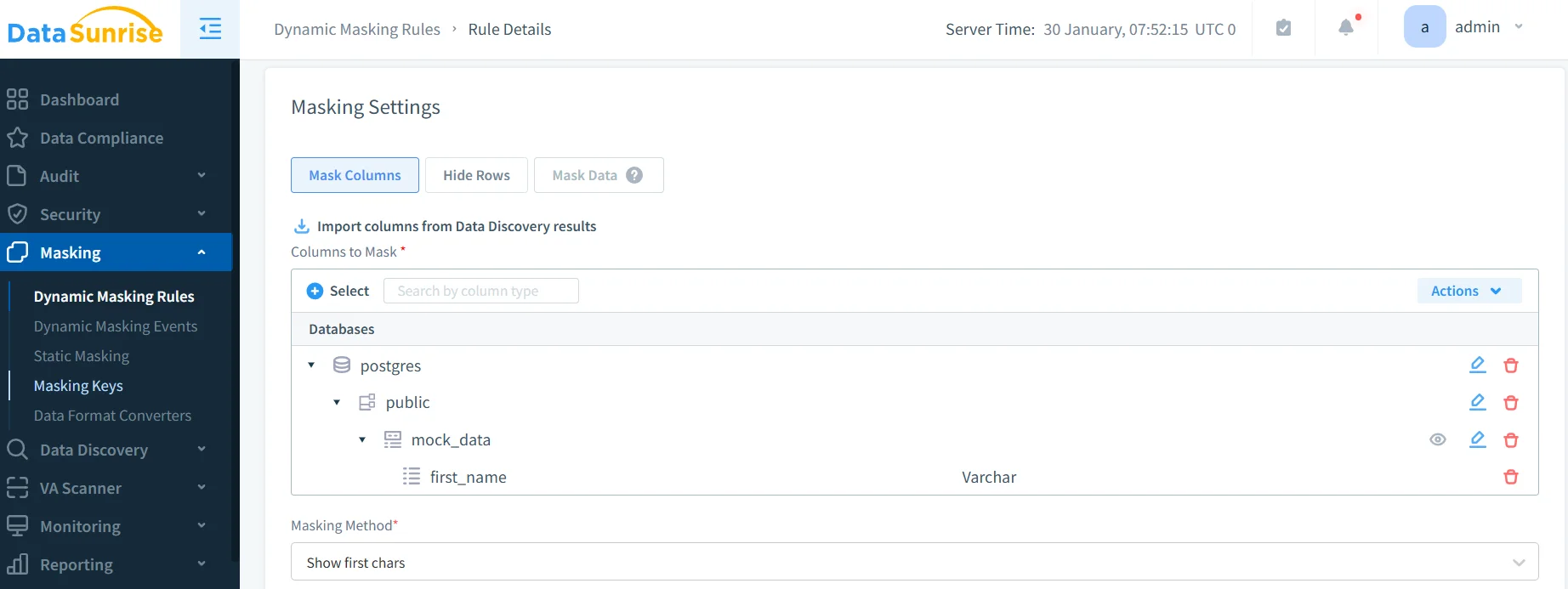
2. Configurare le regole di masking dinamico
Creare policy di offuscamento tramite No-Code Policy Automation. Il Data Discovery NLP di DataSunrise identifica automaticamente i dati sensibili e li mappa ai requisiti GDPR, HIPAA, PCI DSS e SOX con report di conformità automatizzati.
3. Verificare l’output dei dati mascherati
DataSunrise maschera dinamicamente i dati sensibili in base ai ruoli utente: gli analisti vedono valori mascherati mentre gli addetti alla conformità hanno accesso ai dati non mascherati quando necessario.
Principali vantaggi di DataSunrise per Apache Cloudberry
Auto-Discover & Classify: Identificazione automatica dei dati sensibili tramite NLP e machine learning su tutte le colonne senza configurazione manuale, garantendo una sicurezza dati completa.
Zero-Touch Data Masking: Applicazione di Masking chirurgico con algoritmi che preservano il formato e protezione contestuale adattiva ai ruoli utente senza modifiche al codice.
No-Code Policy Automation: Creazione di policy tramite interfaccia intuitiva con template per GDPR, HIPAA, PCI DSS e SOX.
Monitoraggio in tempo reale: Rilevamento di anomalie tramite algoritmi ML con allarmi in tempo reale e audit trail completi.
Visibilità cross-platform: Monitoraggio dell’offuscamento su Cloudberry e oltre 40 altre piattaforme con copertura multi-ambiente senza interruzioni, inclusa la protezione con firewall per database.
Conclusione
Con la crescente adozione di Apache Cloudberry per analisi su larga scala, un offuscamento dati robusto diventa fondamentale per proteggere le informazioni sensibili. Sebbene le funzionalità native di Cloudberry basate su PostgreSQL offrano una base di partenza, le organizzazioni con requisiti di conformità complessi beneficiano di soluzioni avanzate come DataSunrise.
DataSunrise offre un offuscamento completo per ambienti MPP, fornendo Data Masking Zero-Touch con Auto-Discover & Classify, No-Code Policy Automation e allineamento continuativo alla conformità. A differenza delle soluzioni che richiedono continui aggiustamenti, DataSunrise garantisce protezione enterprise con Intelligent Policy Orchestration in ambienti eterogenei, supportando strategie efficaci di gestione dati.
Con modalità di deployment flessibili e integrazione cloud senza soluzione di continuità tramite i principali marketplace (AWS, GCP, Azure), DataSunrise offre una sicurezza conveniente e adatta a ogni dimensione aziendale — dalle startup alle imprese Fortune 500.
Proteggi i tuoi dati con DataSunrise
Metti in sicurezza i tuoi dati su ogni livello con DataSunrise. Rileva le minacce in tempo reale con il Monitoraggio delle Attività, il Mascheramento dei Dati e il Firewall per Database. Applica la conformità dei dati, individua le informazioni sensibili e proteggi i carichi di lavoro attraverso oltre 50 integrazioni supportate per fonti dati cloud, on-premises e sistemi AI.
Inizia a proteggere oggi i tuoi dati critici
Richiedi una demo Scarica ora