Strumenti di Conformità per Dati NLP, LLM e ML per Amazon OpenSearch
Gli strumenti di conformità per dati NLP, LLM & ML per Amazon OpenSearch sono importanti perché OpenSearch non è più “solo ricerca” o “solo log.” Nelle infrastrutture moderne alimenta l’osservabilità, l’analisi della sicurezza e persino copiloti AI che riassumono incidenti o rispondono a domande basate sulla telemetria indicizzata. Nel momento in cui i dati di OpenSearch diventano una fonte per RAG, arricchimento di prompt o estrazione di feature ML, il rischio di conformità aumenta: payload non strutturati possono contenere identificatori, segreti e contesti regolamentati che ora sono interrogabili a velocità macchina.
AWS fornisce la piattaforma gestita per il Amazon OpenSearch Service, ma la responsabilità di identificare i dati sensibili, controllare l’esposizione e produrre evidenze di audit rimane della tua organizzazione. Questa guida mostra dove NLP/LLM/ML aiutano, dove possono creare problemi e come DataSunrise consente la scoperta automatizzata, la governance, l’auditing, la mascheratura e la reportistica per gli ambienti OpenSearch guidati dall’AI.
Perché i carichi di lavoro AI aumentano la pressione sulla conformità in OpenSearch
Le sfide classiche di conformità in OpenSearch esistono già: dati semi-strutturati, indici in rapida evoluzione e accessi estesi concessi per comodità. I carichi di lavoro AI amplificano questi problemi perché aumentano sia la portata dei dati sia la interpretazione dei dati. Le pipeline NLP estraggono entità dal testo libero, gli LLM riassumono contenuti (inclusi snippet sensibili) e i modelli ML rilevano pattern che possono indirettamente codificare informazioni personali. Non è qualcosa di teorico: un LLM che risponde a “cosa è successo ieri sera?” potrebbe svelare involontariamente identificatori utente incorporati nei log.
Ecco perché la conformità consapevole dell’AI deve allinearsi con le normative sulla conformità dei dati e con framework comuni come il GDPR, le tutele tecniche HIPAA e il PCI DSS. In pratica, ai regolatori non interessa se i dati risiedono in un database, in un indice di log o in un cluster di ricerca: se contengono contenuti regolamentati, devono essere governati.
Come si presenta la “Conformità Pronta per AI” per OpenSearch
Se OpenSearch alimenta sistemi NLP/LLM/ML, la conformità deve essere continua e misurabile. Un programma pratico “pronto per AI” si concentra su cinque risultati:
- Conoscere quali dati esistono: identificare continuamente PII e altri pattern sensibili attraverso indici e documenti.
- Limitare ciò a cui l’AI può accedere: applicare confini e ambiti di accesso per prevenire il “prompt uguale admin.”
- Ridurre ciò che l’AI può rivelare: mascherare o tokenizzare i valori sensibili prima che raggiungano i prompt o le finestre di contesto dei modelli.
- Registrare le evidenze: mantenere log difendibili e tracciamenti che spieghino chi ha accesso a cosa e perché.
- Automatizzare i report: generare pacchetti di evidenza ripetibili per audit e controlli interni.
Come NLP, LLM e ML supportano i controlli di conformità
NLP per la scoperta di dati sensibili non strutturati
Gli approcci basati solo su Regex falliscono in OpenSearch perché i dati più pericolosi sono spesso sepolti nei log a testo libero e nei campi JSON annidati. NLP aumenta la copertura rilevando entità e contesto all’interno di contenuti non strutturati. DataSunrise supporta la classificazione scalabile tramite Data Discovery, aiutando i team a individuare campi sensibili in anticipo—prima che quei dati vengano ingeriti in embedding, prompt o set di dati di addestramento.
LLM per contesto e spiegabilità
Gli LLM possono migliorare i flussi di lavoro degli analisti, ma introducono anche nuove domande di conformità: quali dati ha visto il modello, cosa ha riassunto e cosa ha prodotto? La governance abilitata da LLM richiede l’applicazione delle politiche e l’auditabilità dei percorsi di accesso—not blind trust nel livello applicativo. Ecco dove la centralizzazione dell’orchestrazione delle politiche diventa critica.
ML per l’analisi comportamentale e la rilevazione di anomalie
Il ML è particolarmente adatto alla rilevazione di comportamenti anomali nelle query: picchi di ricerche ad alta cardinalità, accessi ripetuti a indici sensibili o pattern insoliti di estrazione dati coerenti con scraping. DataSunrise rafforza questo con l’analisi del comportamento utente, permettendo ai team di identificare usi sospetti che i controlli tradizionali allow/deny potrebbero non cogliere.
Architettura di Riferimento: Layer di Conformità Consapevole AI per OpenSearch
Il modello più sicuro è applicare la conformità vicino al livello di accesso OpenSearch in modo che scoperta, politiche e evidenze di audit siano coerenti tra strumenti—dashboard, API e agenti AI. DataSunrise offre un layer di conformità centralizzato per governance e raccolta delle evidenze senza richiedere una riprogettazione degli indici.
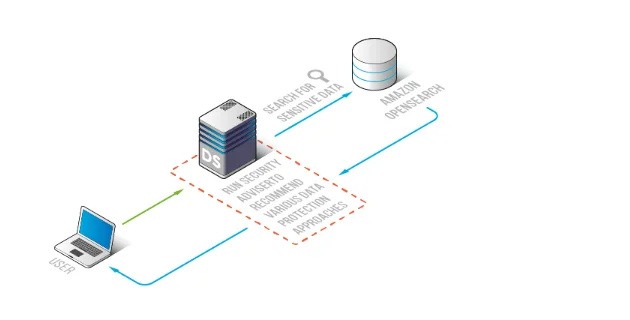
Mappatura dei Controlli: Dove si Collocano gli Strumenti di Conformità in una Pipeline NLP/LLM/ML
| Fase AI | Rischio OpenSearch | Controllo di conformità | Risultato |
|---|---|---|---|
| Ingestione | Campi sensibili indicizzati in documenti ricercabili | Scoperta + definizione dell’ambito | Inventario noto e oggetti governati |
| Recupero (RAG) | I prompt estraggono identificatori grezzi nel contesto | Mascheratura + principio del minimo privilegio | Minore esposizione nel contesto LLM |
| Analisi | Accesso esteso per dashboard e indagini | Controlli di accesso centralizzati + logging delle attività | Tracciabilità e responsabilità |
| Addestramento modelli | I dataset di training codificano dati regolamentati | Mascheratura statica o dati sintetici | Dataset sicuri per ottimizzazione ML/LLM |
| Operazioni | Drift: nuovi indici/pipeline appaiono silenziosamente | Monitoraggio continuo + reportistica | I controlli rimangono aggiornati nel tempo |
Strumenti DataSunrise per Automatizzare la Conformità in OpenSearch
1) Gestione della conformità basata su policy
Per scalare la governance, le policy devono essere definite centralmente e applicate in modo coerente. DataSunrise fornisce flussi di lavoro per le policy tramite Compliance Manager, permettendo ai team di standardizzare regole in tutti gli ambienti. Abbina le policy a RBAC e controlli di accesso centralizzati così che gli strumenti AI e gli utenti ricevano solo l’accesso necessario al loro ruolo.
2) Selezione dell’ambito per oggetti sensibili in OpenSearch
Gli strumenti di conformità devono essere precisi: governare gli indici sensibili senza compromettere le analisi a basso rischio. DataSunrise supporta il controllo dell’ambito a livello di oggetto per applicare le policy solo dove necessario—specialmente importante quando lo stesso cluster OpenSearch serve sia dashboard operativi sia flussi di lavoro AI.
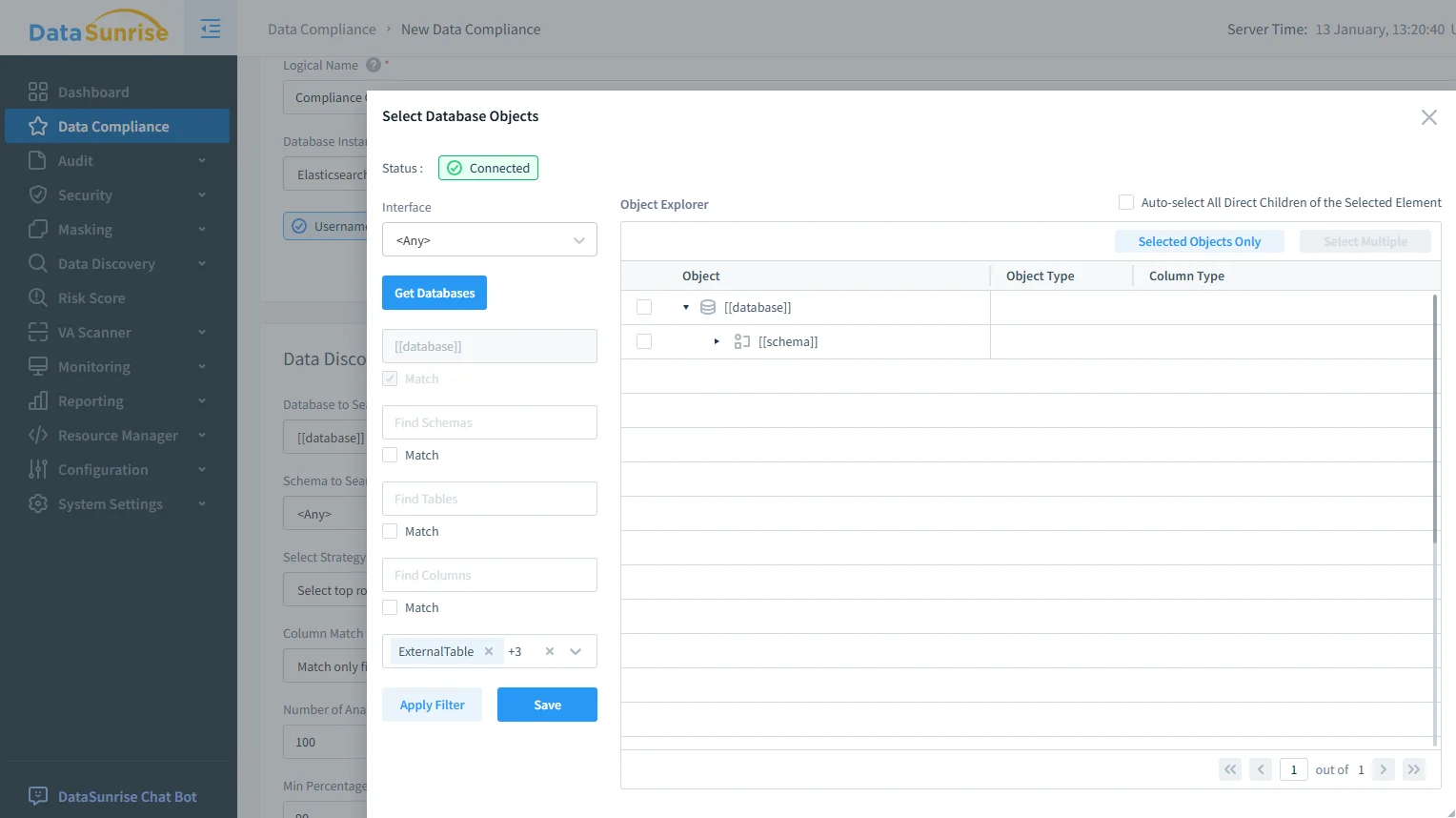
Selezione dell’ambito per la conformità OpenSearch: scegliere oggetti governati in modo che i flussi AI tocchino solo indici e campi approvati.
3) Audit e evidenze per accessi guidati dall’AI
L’AI aumenta il numero di percorsi di accesso (dashboard, API, agenti), quindi l’evidenza di audit deve essere centralizzata. DataSunrise supporta log di audit dettagliati tramite Data Audit, e preserva la tracciabilità di livello investigativo con audit trail. Per la supervisione a runtime, il monitoraggio dell’attività di database aiuta a individuare precocemente comportamenti rischiosi nelle query.
Per una guida di base sul logging di servizio, AWS documenta qui l’audit logging OpenSearch: Audit logs Amazon OpenSearch. In ambienti ad alta presenza AI, l’evidenza centralizzata è tipicamente più facile da difendere rispetto a log sparsi su molti livelli.
4) Mascheratura e sicurezza dei dataset per pipeline ML/LLM
La maggior parte dei carichi AI non richiede identificatori grezzi. DataSunrise riduce l’esposizione tramite mascheratura dinamica dei dati per la protezione a tempo di query e mascheratura statica dei dati per estratti più sicuri e pipeline non di produzione. Quando addestramento o test necessitano una struttura realistica senza identità reali, la generazione di dati sintetici aiuta a mantenere la sperimentazione AI conforme.
5) Controlli di sicurezza preventivi e validazione della postura
Gli agenti AI possono amplificare involontariamente gli abusi (per esempio, “cerca tutto per X”). I controlli preventivi aiutano a limitare il raggio d’azione. Usa regole di firewall di database per bloccare pattern abusivi e valutazioni di vulnerabilità per identificare drift e configurazioni errate che possono compromettere la conformità.
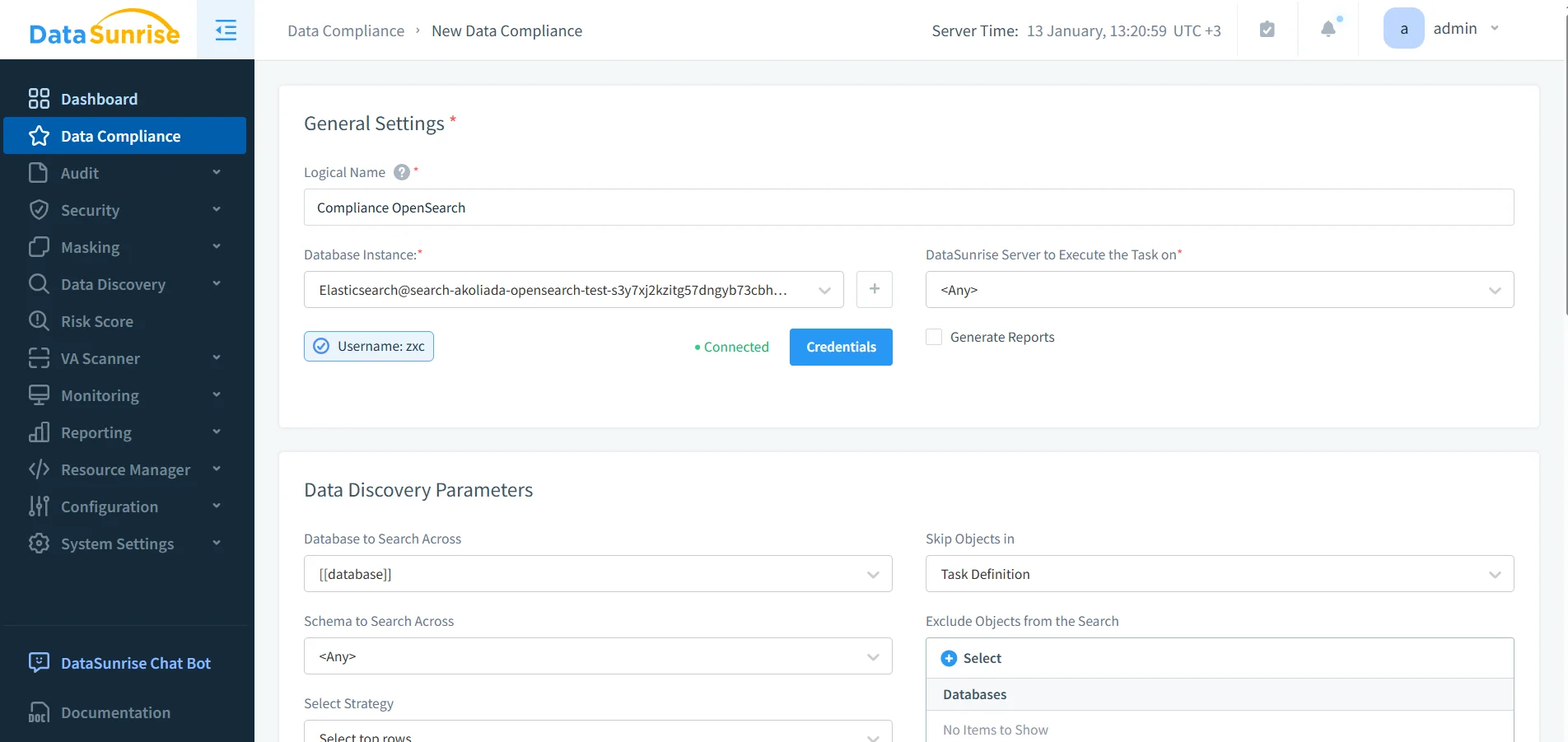
Configurazione delle regole di conformità: automatizza azioni di governance (audit, mascheratura, reportistica) per flussi di lavoro OpenSearch assistiti da AI.
Reportistica automatizzata per conformità NLP, LLM e ML
Gli auditor non vogliono screenshot; vogliono evidenze ripetibili. DataSunrise supporta la reportistica automatizzata con generazione di report e report di conformità automatizzati. In ambienti con intensa presenza AI, l’automazione fa la differenza tra “pensiamo di essere conformi” e “ecco il pacchetto di evidenze.”
Per mantenere la conformità durevole nonostante il cambiamento degli indici e delle pipeline, allinea i controlli con la protezione continua dei dati affinché scoperta, politiche ed evidenze rimangano aggiornate.
Conclusione
Gli strumenti di conformità per dati NLP, LLM & ML per Amazon OpenSearch funzionano al meglio quando non sono “aggiunte esterne,” ma parte di un piano di controllo: scoprire dati sensibili continuamente, definire con precisione l’ambito di accesso, ridurre l’esposizione con mascheratura, monitorare anomalie e generare automaticamente evidenze pronte per audit. DataSunrise fornisce un set integrato di controlli per governare carichi AI-driven su OpenSearch su larga scala.
Per pianificare il deployment, consulta la panoramica di DataSunrise e i modelli di deployment disponibili, quindi inizia con il Download o richiedi una Demo guidata.
