Traccia di Audit dei Dati SQL di Databricks
Databricks SQL è diventato un motore analitico centrale per le organizzazioni che adottano architetture lakehouse. Consente business intelligence, reporting e analisi ad-hoc direttamente sullo storage cloud, supportando un gran numero di utenti e carichi di lavoro automatizzati. Con l’aumento dei volumi di dati e dei modelli di accesso, mantenere una traccia di audit SQL di Databricks affidabile diventa essenziale per comprendere come i dati vengono consultati, modificati e condivisi nella piattaforma.
Nei moderni ambienti analitici, l’accesso ai dati è raramente statico. Gli analisti esplorano i dataset in modo interattivo, gli strumenti BI effettuano query programmate e le applicazioni generano carichi lavoro automatizzati. Poiché questi modelli di accesso si sovrappongono, le organizzazioni necessitano di una traccia di audit che catturi le interazioni con i dati in modo coerente tra utenti, strumenti e contesti di esecuzione. Questa esigenza è strettamente allineata ai principi della gestione dei dati e dell’accessibilità controllata dei dati.
Una traccia di audit dei dati si concentra specificamente sulle interazioni con gli oggetti dati piuttosto che sugli eventi dell’infrastruttura. Registra come tabelle, schemi e colonne vengono interrogati o modificati nel tempo. Negli ambienti distribuiti Databricks SQL, dove più utenti, strumenti BI e applicazioni operano contemporaneamente, una traccia di audit strutturata fornisce la base per indagini di sicurezza, governance e conformità normativa.
Questo articolo spiega cos’è una traccia di audit SQL di Databricks, perché i log nativi spesso non sono sufficienti e come DataSunrise consente tracce di audit centralizzate e focalizzate sui dati tramite monitoraggio in tempo reale, cronologia transazionale e controlli basati su policy.
Cos’è una Traccia di Audit in Databricks SQL?
Una traccia di audit SQL di Databricks è un registro cronologico delle azioni che influenzano gli oggetti dati. Cattura quali dataset sono stati consultati, quali istruzioni SQL sono state eseguite e come tali operazioni abbiano impattato tabelle e schemi. A differenza dei semplici log di query, una traccia di audit conserva il contesto e l’ordine di esecuzione, formando una vera e propria storia dell’attività di database.
Ancora più importante, una traccia di audit collega eventi individuali in una sequenza coerente. Invece di considerare ogni query come un record isolato, essa associa l’attività a una sessione specifica, utente o flusso di lavoro applicativo. Questo collegamento è cruciale per un efficace monitoraggio dell’attività di database.
Per esempio, una traccia di audit completa collega un’istruzione SELECT alla sessione e all’utente che l’ha avviata, quindi connette le operazioni successive di UPDATE o DELETE allo stesso flusso di lavoro. Questa continuità permette ai team di ricostruire esattamente come i dati siano stati consultati o modificati durante un determinato intervallo di tempo.
Tale tracciabilità è fondamentale per organizzazioni che operano sotto normative quali GDPR, HIPAA, PCI DSS e SOX. I regolatori si aspettano che le organizzazioni dimostrino non solo l’esistenza della registrazione log, ma anche che l’accesso ai dati possa essere ricostruito e spiegato in maniera difendibile.
Perché i Log Nativi di Databricks Non Sono Sufficienti
Databricks fornisce log di audit nativi che catturano gli eventi a livello di workspace e di esecuzione SQL. Questi log tipicamente includono il testo della query, timestamp, identità degli utenti e tipi di operazioni ad alto livello. Le squadre spesso esportano questa telemetria verso piattaforme esterne come Azure Log Analytics, Amazon CloudWatch, o Google Cloud Logging.
Sebbene i log nativi siano utili per il troubleshooting operativo, non sono stati progettati per funzionare come una traccia di audit completa a livello di dati. Correlare eventi tra sessioni, utenti e oggetti dati spesso richiede processamenti manuali o script personalizzati, i quali introducono rischi e ritardi.
Inoltre, i log nativi si concentrano sugli eventi di esecuzione piuttosto che sull’impatto sui dati. Non sempre forniscono una chiara comprensione di quali tabelle o schemi siano stati interessati, specialmente quando sono coinvolti join complessi, viste o query annidate. Per le organizzazioni che necessitano di evidenze di audit difendibili, queste limitazioni creano lacune nella sicurezza dei dati e nella sicurezza del database.
Connessione a Databricks SQL per la Raccolta della Traccia di Audit
Per costruire una traccia di audit affidabile per Databricks SQL, un sistema di auditing deve stabilire una connessione sicura e continua al data warehouse. Questa connessione permette al sistema di osservare l’attività SQL in tempo reale senza interferire con l’esecuzione o le prestazioni delle query.
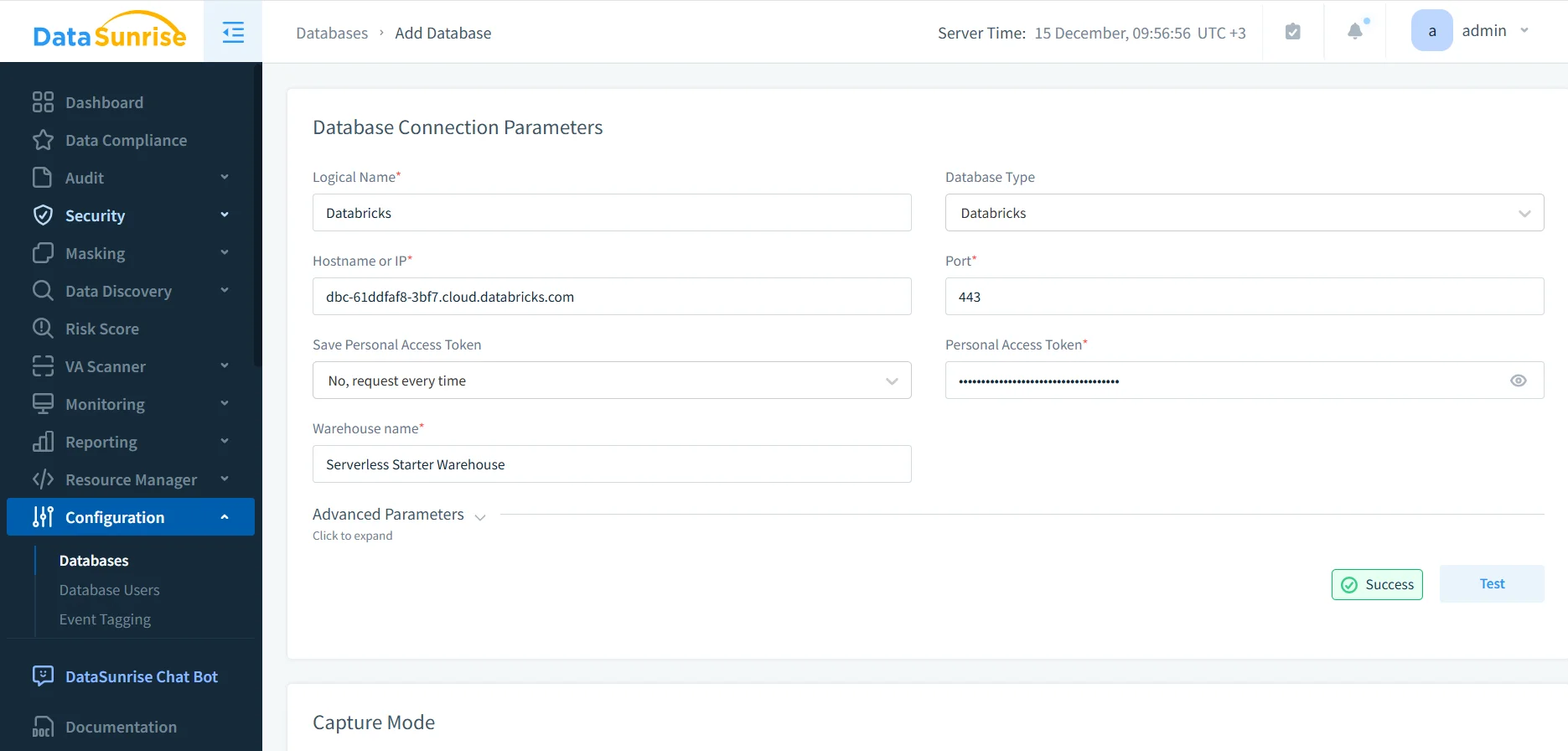
Durante la configurazione, gli amministratori definiscono parametri come hostname, porta, nome del warehouse e metodo di autenticazione. Una volta attiva la connessione, il livello di auditing può iniziare a catturare l’attività SQL legata all’accesso e alla modifica dei dati. Questo modello di distribuzione è coerente con i modi di deployment e l’architettura basata su proxy di DataSunrise.
Selezione degli Oggetti Dati da Auditare
Un auditing efficace non richiede il monitoraggio di ogni oggetto nell’ambiente. Invece, le organizzazioni si concentrano tipicamente su schemi e tabelle che contengono dati sensibili, regolamentati o critici per il business, rilevati tramite processi di data discovery.
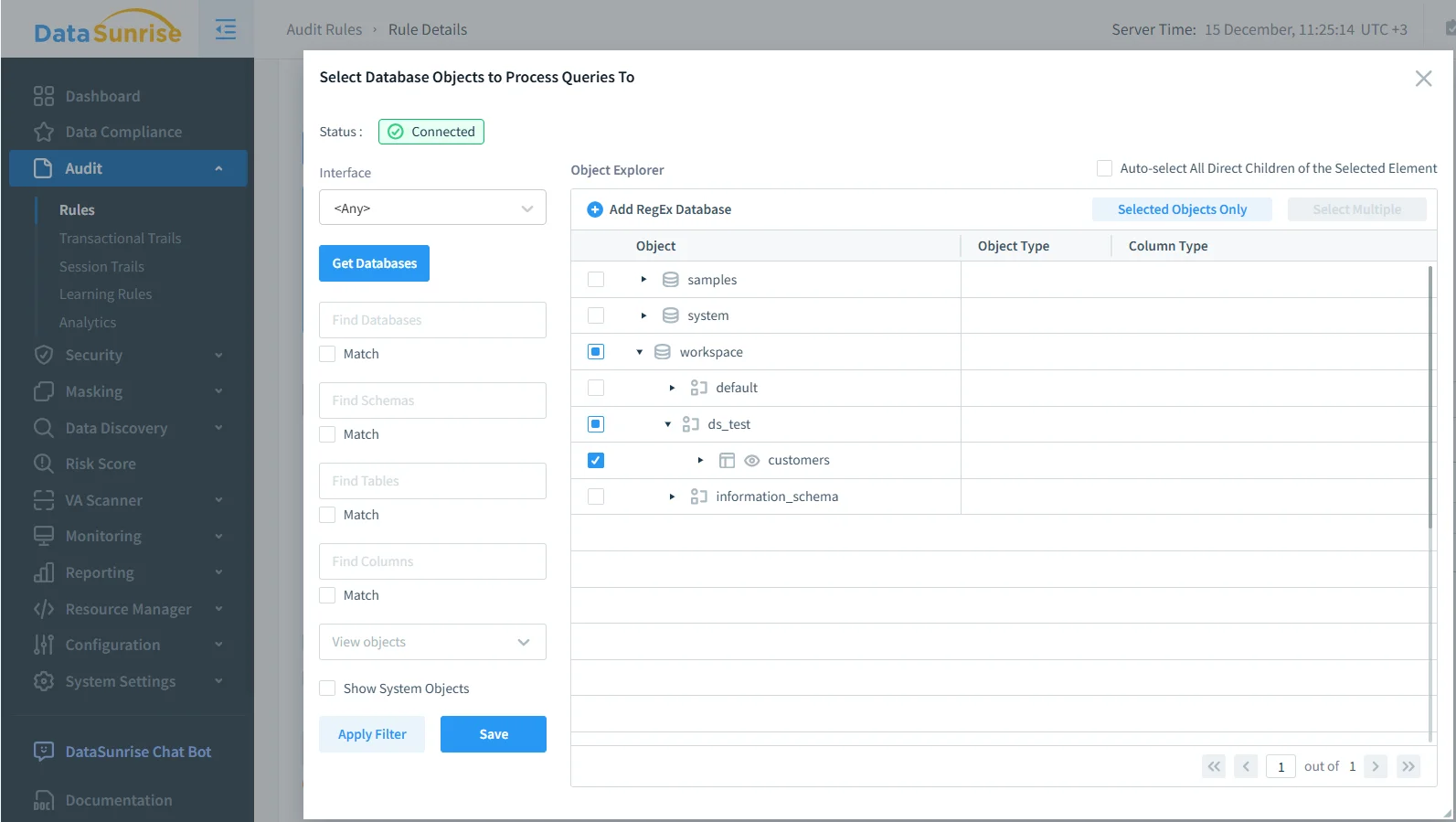
Mirando a oggetti specifici, i team riducono il rumore e creano una traccia di audit che evidenzia eventi di accesso ai dati significativi. Questo approccio selettivo migliora anche le prestazioni e supporta il principio del privilegio minimo.
Tracce di Audit Transazionali per Databricks SQL
Una volta attive le regole di audit, DataSunrise registra gli eventi in una traccia di audit transazionale. Questa traccia preserva l’ordine esatto in cui le operazioni SQL avvengono, creando una linea temporale affidabile di accesso e modifica dei dati adatta all’analisi forense.
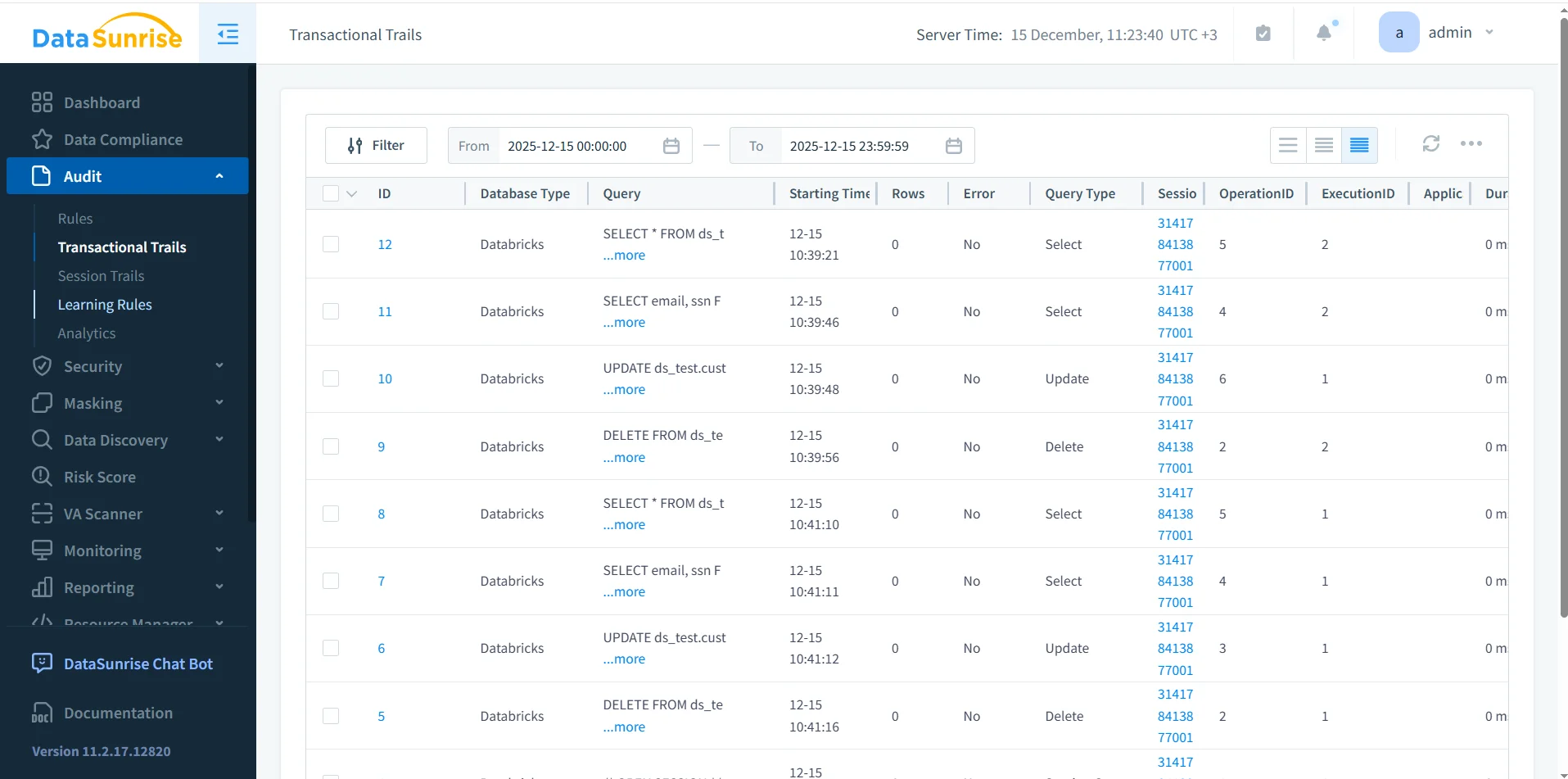
Ogni voce di audit include testo della query, tempo di esecuzione, tipo di query, identificativi della sessione e stato di esecuzione. Questi attributi permettono ai team di ricostruire come specifici dataset siano stati consultati e modificati, aspetto essenziale per l’analisi del comportamento degli utenti e la risposta agli incidenti.
Questa vista transazionale supporta analisi forensi e reportistica di conformità. Inoltre, è in linea con le pratiche consolidate descritte in audit logs e metodologie di audit trail.
Conclusione: Costruire una Traccia di Audit SQL di Databricks
Databricks SQL offre potenti capacità analitiche, tuttavia gli ambienti guidati dai dati richiedono più del semplice logging di base. Una traccia di audit affidabile deve preservare il contesto, l’ordine di esecuzione e la visibilità a livello di oggetto, integrandosi con i controlli di governance più ampi.
Una traccia di audit SQL di Databricks costruita con DataSunrise cattura l’attività in tempo reale, traccia l’accesso a dataset critici e produce evidenze di audit strutturate per indagini, audit di conformità e programmi continui di audit dei dati.
Con una traccia di audit ben definita, le organizzazioni possono scalare in modo sicuro Databricks SQL mantenendo trasparenza, controllo e allineamento regolatorio.
