
Cos’è il Data Masking?
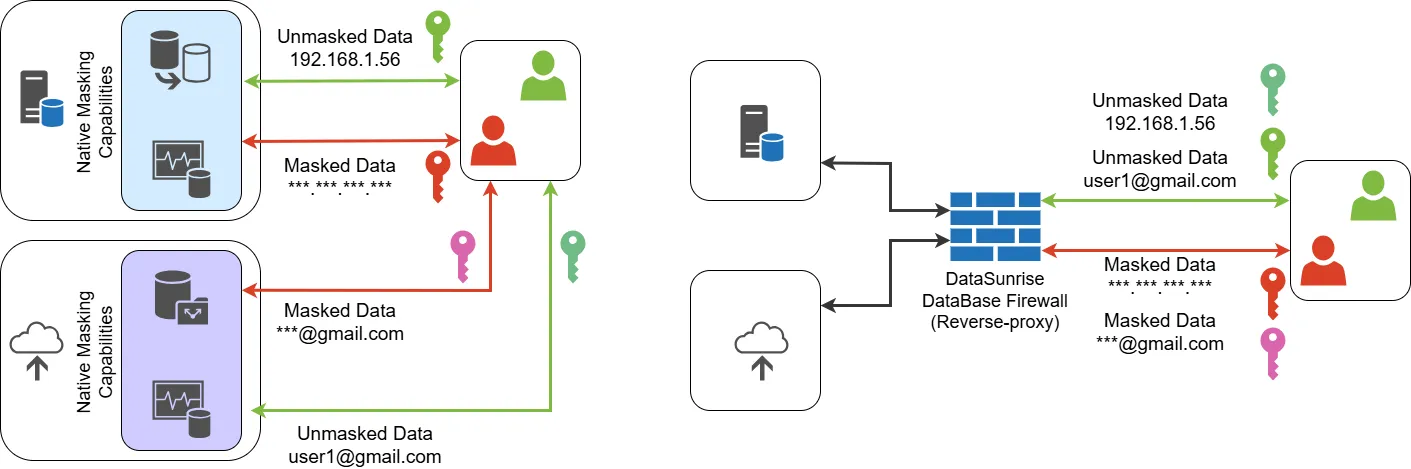
Cos’è il Data Masking?
Per comprendere il data masking, è importante inquadrarlo nel contesto più ampio dell’aumento delle violazioni dei dati e del crescente rigore delle normative sulla privacy. Le organizzazioni oggi devono proteggere le informazioni sensibili mantenendole comunque utilizzabili per funzioni aziendali essenziali. Secondo recenti ricerche Gartner, il data masking è diventato un elemento fondamentale delle tecnologie moderne per il miglioramento della privacy, in particolare in ambienti dove i dati vengono condivisi tra team interni, partner esterni e piattaforme cloud.
Il data masking sostituisce i valori reali dei dati con versioni realistiche ma inventate. Questo assicura che le informazioni sensibili rimangano protette da esposizioni non autorizzate, consentendo comunque l’uso sicuro dei dati per sviluppo, testing, analisi e collaborazione con terze parti.
Per soddisfare le crescenti esigenze di privacy e conformarsi a framework come GDPR, HIPAA e PCI DSS, le organizzazioni necessitano di soluzioni di masking scalabili e guidate da policy. DataSunrise offre sia masking statico che dinamico, supportato da regole intelligenti che si adattano automaticamente in base ai ruoli degli utenti, al contesto e alle autorizzazioni di accesso.
Quando implementato efficacemente, il data masking trasforma il modo in cui le informazioni sensibili sono governate—supportando collaborazioni sicure, riducendo le minacce interne e assicurando la conformità nei complessi ecosistemi di dati distribuiti.
Perché il Data Masking è Importante nelle Strategie di Sicurezza Moderne
La protezione dei dati moderna supera di gran lunga i tradizionali approcci di cifratura. Il data masking gioca un ruolo cruciale nell’applicare i principi di accesso basato sul minimo privilegio, garantendo che le informazioni sensibili rimangano protette anche quando sono accessibili da utenti autorizzati che non necessitano della piena visibilità dei dati.
Sia che si operi sotto il GDPR in Europa, HIPAA nel settore sanitario o PCI DSS nei servizi finanziari, le organizzazioni devono dimostrare misure di protezione dati proattive. Con politiche di masking complete, i team possono processare, analizzare e testare su set di dati realistici senza mai esporre i valori originali sensibili a personale non autorizzato.
Senza il masking, anche utenti interni con buone intenzioni possono visualizzare dati riservati di cui non hanno bisogno — aumentando il rischio di fughe, abusi o non conformità regolamentare. Introdurre il masking nei flussi di lavoro quotidiani riduce drasticamente l’esposizione lungo pipeline di sviluppo, strumenti analitici e interazioni con fornitori, il tutto senza compromettere produttività o fedeltà dei dati.
| Normativa | Articolo | Requisito di Masking |
|---|---|---|
| GDPR | Art. 32 | Pseudonimizzazione dei dati personali |
| PCI DSS 4.0 | 3.4 | Renderizzare il PAN illeggibile (tokenizzazione, masking) |
| HIPAA | §164.514(b) | De-identificare 18 identificatori PHI |
| DORA | Art. 9 | Proteggere i dataset usati nei test di resilienza |
Il masking dinamico permette un accesso sicuro ai sistemi di produzione live, mentre il masking statico crea dataset sanificati perfetti per ambienti di formazione, collaborazioni con fornitori o test di qualità. DataSunrise semplifica entrambe le metodologie attraverso interfacce di configurazione intuitive e supporto robusto per schemi di database complessi e distribuzioni cloud ibride.
Data Masking — Sintesi, Passaggi e Controlli Rapidi
Sintesi
- Scopo: limitare l’esposizione di valori sensibili preservando l’utilità del dataset.
- Modalità: dinamica (al momento della query), statica (copie sanificate), in-place (dataset non-prod).
- Allineamento: conforme a pseudonimizzazione GDPR, de-identificazione HIPAA, masking PCI DSS.
Passaggi di Implementazione
- Scoprire e classificare i campi (PII/PHI/PCI) tra le fonti.
- Definire ruoli e livelli di visibilità richiesti.
- Selezionare la modalità per caso d’uso (dinamico per produzione; statico per dev/test/fornitori).
- Scegliere algoritmi (redazione, sostituzione, FPE, tokenizzazione) per tipo di colonna.
- Configurare regole a livello schema/tabella/colonna; preservare l’integrità referenziale.
- Validare in ambienti di staging; confermare comportamento dell’app e accuratezza analitica.
- Monitorare le performance e regolare il campo di applicazione per controllare la latenza.
- Documentare le policy; pianificare revisioni periodiche con l’evoluzione degli schemi.
Selezione Algoritmi
| Tipo di Dati | Approccio Consigliato | Note |
|---|---|---|
| PAN / dati carta | Mascherare BIN + ultime 4 / tokenizzazione | Allineamento requisito PCI DSS 3.4 |
| Email / nomi utente | Sostituzione preservante il formato | Mantenere forma dominio/utente per UX |
| PII testo libero | Sostituzione con dizionario/regex | Analizza log, commenti, blob JSON |
| Date / importi | Iniezione rumore / raggruppamento | Preserva ordine/statistiche |
| IP / localizzazioni | Generalizzazione / randomizzazione | Mantenere la regione se necessario |
Controlli Rapidi
- Le colonne mascherate restano valide per la logica applicativa e i report?
- Le trasformazioni sono irreversibili per utenti non privilegiati?
- L’integrità referenziale è preservata tra tabelle correlate?
- La latenza aggiunta rientra negli SLO target sotto carico massimo?
Casi d’Uso Comuni per il Data Masking
Le organizzazioni implementano il data masking in scenari diversi per mantenere la sicurezza e abilitare le operazioni aziendali:
- Collaborazione con fornitori: Condivisione di dataset con partner terzi mantenendo la riservatezza dei clienti e delle informazioni competitive. Il data masking garantisce che fornitori esterni, appaltatori e service provider possano svolgere il proprio lavoro efficacemente senza accedere ai dati sensibili in chiaro, riducendo il rischio di violazioni in ambienti esterni meno controllati.
- Prevenzione degli errori: Protezione contro esposizioni accidentali dovute a errori operativi, amministrativi o configurazioni errate del sistema. Il masking funge da ulteriore livello di sicurezza, assicurando che anche se dati privilegiati vengono esportati, registrati o accessi scorretti avvengono, i campi sensibili restino illeggibili e l’impatto di errori umani sia minimo.
- Sviluppo e testing: Fornitura di dataset realistici per test applicativi, training di machine learning e ottimizzazione delle prestazioni senza rischi per la privacy. Il masking permette ai team di lavorare con dati strutturalmente accurati e simili a quelli di produzione, supportando debugging, test di carico, addestramento di modelli e controlli di integrazione prevenendo l’uso di identità reali di clienti o campi regolamentati.
- Analisi e reporting: Permettere agli analisti e data scientist di lavorare con dati simili a quelli di produzione mantenendo la conformità alle normative sulla privacy. I dataset mascherati preservano proprietà statistiche critiche e relazioni, consentendo insight di alta qualità, dashboard e previsioni senza esporre PII o violare standard come GDPR, HIPAA o PCI DSS.
Esempi di Dati Mascherati
Le strategie di masking variano significativamente a seconda dei requisiti di classificazione dati, livelli di permessi utente e specifiche politiche di conformità. Alcuni sistemi richiedono la redazione completa, mentre altri consentono sostituzioni preservanti il formato che mantengono l’utilità del dato. DataSunrise supporta entrambi gli approcci su database strutturati e repository di dati non strutturati.
-- Prima del masking: 4024-0071-8423-6700 -- Dopo il masking: XXXX-XXXX-XXXX-6700
| Metodo di Masking | Dati Originali | Dati Mascherati |
|---|---|---|
| Masking carta di credito | 4111 1111 1111 1111 | 4111 **** **** 1111 |
| Masking email | [email protected] | j***e@e*****e.com |
| Masking URL | https://www.example.com/user/profile | https://www.******.com/****/****** |
| Masking numero di telefono | +1 (555) 123-4567 | +1 (***) ***-4567 |
| Randomizzazione indirizzo IP | 192.168.1.1 | 203.45.169.78 |
| Randomizzazione data con conservazione anno | 2023-05-15 | 2023-11-28 |
| Masking con funzione personalizzata | Secret123! | S****t1**! |
| Sostituzione basata su dizionario | John Smith, Software Engineer, New York | Ahmet Yılmaz, Data Analyst, Chicago |
Passaggi di Implementazione del Data Masking
Per un’implementazione di successo del data masking sono necessari pianificazione ed esecuzione sistematiche suddivise in più fasi:
- Scoperta e classificazione dei dati: Individua i campi sensibili nella tua infrastruttura utilizzando strumenti di scoperta automatica che identificano PII, dati finanziari e informazioni regolamentate in database e applicazioni.
- Mappatura delle policy e definizione dei ruoli: Stabilisci politiche di masking complete basate sui ruoli utente, classificazioni di sensibilità dei dati e requisiti normativi specifici per il settore e la presenza geografica.
- Configurazione regole e testing: Definisci regole granulari di masking a livello di schema, tabella, colonna o tipo di dato, assicurandoti che i dati mascherati mantengano integrità referenziale e coerenza della logica di business.
- Validazione e implementazione: Testa accuratamente la funzionalità di masking in ambienti di staging prima del deployment in produzione, verificando che le applicazioni continuino a funzionare correttamente con dataset mascherati.
- Monitoraggio e manutenzione: Attiva un monitoraggio continuo per garantire che le policy di masking restino efficaci con l’evolversi delle strutture dati e l’introduzione di nuovi tipi di dati sensibili.
Tipi di Data Masking
| Algoritmo | Mantiene il Formato? | Rischio di Re-ID | Ideale per |
|---|---|---|---|
| Redazione | No | Basso | Log, screenshot |
| Tokenizzazione | Sì | Molto basso* | Token di pagamento |
| Randomizzazione | Opzionale | Basso | Dataset PII |
| Crittografia Preservante il Formato (FPE) | Sì | Molto basso | Applicazioni legacy |
*Presupponendo controlli di detokenizzazione basati su vault.
Masking Dinamico
Il masking dinamico applica offuscamento dei dati durante l’esecuzione della query senza modificare permanentemente la fonte. Questo approccio garantisce controlli di accesso in tempo reale ideali per sistemi di produzione multi-utente dove la visibilità dei dati deve variare dinamicamente in base ai ruoli e al contesto di accesso.
CREATE VIEW clienti_mascherati AS
SELECT
id,
nome,
CASE
WHEN current_user = 'admin_user' THEN carta_credito
ELSE regexp_replace(carta_credito, '^\d{4}-\d{4}-\d{4}-(\d{4})$', 'XXXX-XXXX-XXXX-\1')
END AS carta_credito
FROM clienti;
Masking Statico
Il masking statico crea copie sanificate permanenti dei database di produzione, permettendo la condivisione sicura e la distribuzione dei dati senza preoccupazioni costanti sulla privacy. Questi dataset mascherati possono essere esportati, condivisi con partner esterni o usati per progetti analitici a lungo termine senza violare normative sulla privacy. Questo è particolarmente prezioso per conformità ISO 27001 e preparazione per audit regolatori.
Masking In-Place
Il masking in-place trasforma i dati direttamente all’interno dei database non di produzione esistenti, specialmente durante i cicli di test pre-release o preparazione di ambienti sandbox. Questo approccio elimina la necessità di risorse duplicate per lo storage, garantendo che i team di sviluppo lavorino con dataset realistici ma protetti.
Requisiti Essenziali per il Masking
Le implementazioni efficaci di data masking devono soddisfare diversi requisiti critici per mantenere sia la sicurezza che l’utilità operativa:
- Preservazione realistica dei dati: I dati mascherati devono apparire e comportarsi come dati reali per garantire un’integrazione senza soluzione di continuità con i sistemi esistenti. I valori sostituiti devono mantenere la stessa struttura, formato e distribuzione statistica degli originali — per esempio, i numeri di carta di credito mascherati dovrebbero superare la validazione checksum, e le date mascherate dovrebbero rimanere in intervalli temporali logici. Questo realismo consente a applicazioni, analisi e ambienti di test di funzionare normalmente senza rischiare l’esposizione di informazioni sensibili.
- Trasformazione irreversibile: Il processo di masking deve essere progettato affinché il recupero dei dati originali sia matematicamente impossibile. Tecniche di randomizzazione forte e algoritmi crittografici impediscono qualsiasi possibilità di reverse engineering o re-identificazione basata su pattern. Questa trasformazione unidirezionale è fondamentale per la conformità a regolamenti come GDPR e HIPAA, che richiedono che i dati anonimizzati non possano essere associati a individui.
- Comportamento consistente: Per mantenere l’integrità dei dati, la logica di masking dovrebbe produrre risultati identici per lo stesso input in tutti i sistemi e periodi temporali. Per esempio, se un ID cliente o numero dipendente appare in più tabelle, deve essere mascherato nello stesso modo ovunque per preservare l’accuratezza relazionale. Questa coerenza supporta test, reporting e auditing affidabili senza compromettere la sicurezza.
- Ottimizzazione delle prestazioni: Il masking efficace deve bilanciare sicurezza ed efficienza. Il processo dovrebbe introdurre un overhead minimo ed evitare di rallentare i sistemi di produzione o le query analitiche. Algoritmi di masking ottimizzati e tecniche di elaborazione parallela permettono alle organizzazioni di proteggere grandi dataset con rapidità — assicurando forti controlli di sicurezza senza impatti sulle prestazioni operative o sull’esperienza utente.
Data Masking nei Framework di Conformità
I regolatori definiscono il data masking come pseudonimizzazione, de-identificazione o minimizzazione dei dati. Di seguito come i principali framework descrivono i requisiti e come il masking li soddisfa:
| Framework | Requisito | Allineamento Masking |
|---|---|---|
| GDPR | Art. 32 — pseudonimizzare o anonimizzare dati personali | Il masking dinamico previene l’esposizione delle PII a utenti non privilegiati. |
| HIPAA | §164.514 — de-identificare 18 identificatori PHI | Il masking statico crea dataset privi di PHI per test, formazione e ricerca. |
| PCI DSS | Req. 3.4 — rendere PAN illeggibile eccetto BIN + ultime 4 cifre | Il masking preservante il formato assicura conformità per i dati delle carte. |
| SOX | Mantenere l’integrità dei dati di rendicontazione finanziaria | Il masking in copie di test previene la fuga di dati finanziari riservati. |
Allineando le policy di masking con gli obblighi di conformità, DataSunrise consente alle aziende di proteggere le informazioni sensibili producendo prove controllabili pronte per gli auditor su database, cloud e ambienti ibridi.
Risultati Aziendali del Data Masking
- Riduzione dell’esposizione a violazioni: Fino al 60% in meno di campi sensibili visibili ad utenti non autorizzati
- Efficienza nella conformità: Evidenze di audit generate in ore, non settimane
- Velocità operativa: I cicli di QA e testing accelerano circa del 30% con dataset sicuri e simili a quelli di produzione
- Riduzione del rischio legale: Allineamento diretto con clausole GDPR, HIPAA, PCI DSS
Applicazioni per Settore
- Finanza: Masking di PAN e PII per PCI DSS e reportistica SOX
- Sanità: De-identificazione di PHI per conformarsi alle regole di privacy HIPAA
- SaaS & Cloud: Masking multi-tenant per garantire la separazione dati conforme a GDPR
- Retail: Protezione dei dati clienti in pipeline analitiche senza perdere insight
Snippet Nativi di Data Masking su Diverse Piattaforme
La maggior parte dei database offre solo un supporto limitato per il masking nativo, spesso richiedendo codice personalizzato o estensioni. Di seguito esempi da SQL Server e Oracle:
SQL Server: Masking Dinamico Integrato
-- Maschera la colonna carta di credito con esposizione parziale
CREATE TABLE Clienti (
Id INT IDENTITY PRIMARY KEY,
NomeCompleto NVARCHAR(100),
CartaCredito VARCHAR(19) MASKED WITH (FUNCTION = 'partial(0,"XXXX-XXXX-XXXX-",4)')
);
-- Risultato: 4111-2222-3333-4444 → XXXX-XXXX-XXXX-4444
Oracle: Politica Virtual Private Database (VPD)
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'HR',
object_name => 'EMPLOYEES',
policy_name => 'mask_ssn_policy',
function_schema => 'SEC_ADMIN',
policy_function => 'mask_ssn_fn',
statement_types => 'SELECT'
);
END;
/
Entrambi gli esempi mostrano masking nativo della piattaforma, ma mancano della flessibilità per applicare regole consapevoli dei ruoli su più database simultaneamente.
Masking nel Contesto di Conformità
Diverse normative definiscono il masking come pseudonimizzazione, de-identificazione o minimizzazione dei dati. Un requisito tipico è garantire trasformazioni irreversibili mantenendo l’usabilità. Di seguito una mappatura rapida della conformità:
| Framework | Obiettivo Masking | Limitazioni Native |
|---|---|---|
| GDPR | Pseudonimizzazione dati personali | Assenza di masking coerente basato su ruoli |
| HIPAA | De-identificazione identificatori PHI | Mancanza di enforcement a livello campo |
| PCI DSS | Masking PAN eccetto BIN e ultime 4 cifre | Piattaforma-specifico, non unificato |
Il masking nativo soddisfa clausole di base, ma piattaforme unificate come DataSunrise offrono copertura cross-regolamentare out-of-the-box.
Data Masking con DataSunrise
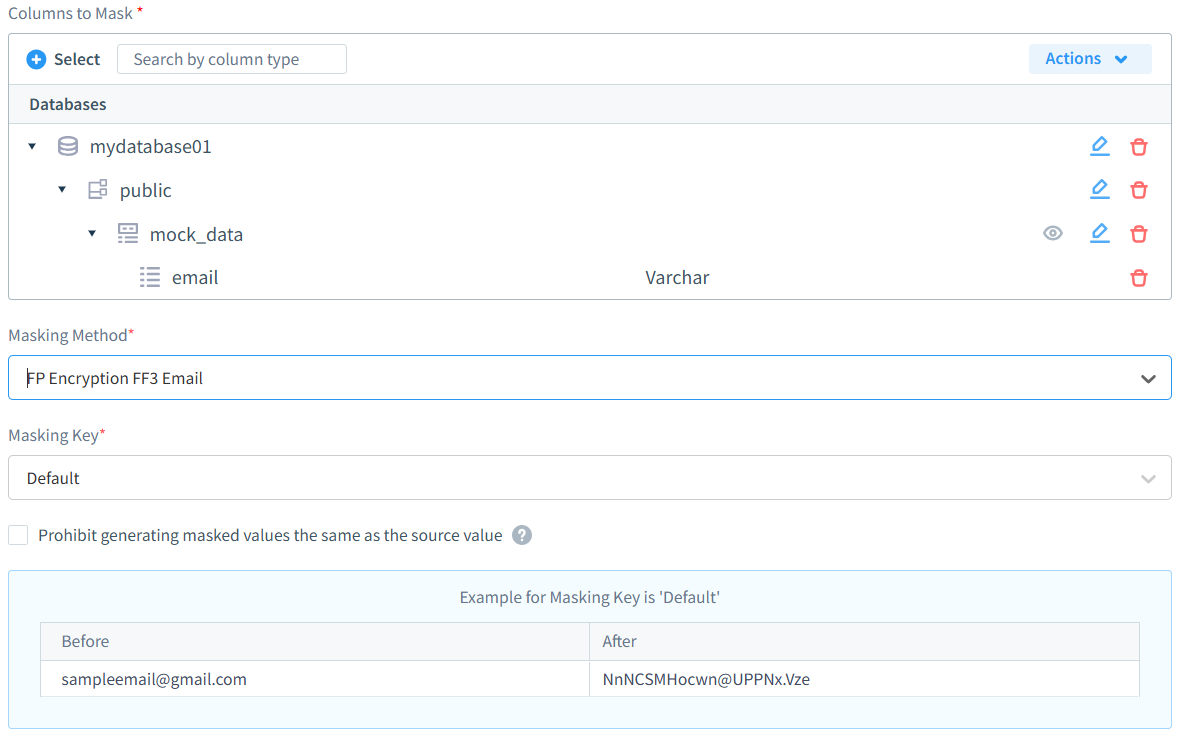
DataSunrise offre capacità di masking enterprise progettate per le moderne esigenze di protezione dati:
- Modalità di masking flessibili: Completo supporto per masking dinamico in tempo reale e masking statico offline, permettendo alle organizzazioni di scegliere approcci ottimali per casi d’uso differenti.
- Controlli di accesso intelligenti: Policy di masking consapevoli dei ruoli e algoritmi preservanti il formato che mantengono l’utilità dei dati assicurando rigorose protezioni della privacy.
- Integrazioni aziendali: Integrazione senza soluzione di continuità con sistemi IAM esistenti, piattaforme SIEM e motori di enforcement policy per semplificare operazioni di sicurezza e report di conformità.
- Automazione della conformità: Logging di audit e capacità di reporting integrate specificamente progettate per i requisiti GDPR, PCI DSS, HIPAA e SOX.
- Architettura scalabile: Supporto per ambienti cloud-native, ibridi e legacy con impatto minimo sulle prestazioni e alta disponibilità.
Scalare il Data Masking in Ambienti Complessi
Con l’evolversi delle architetture, il data masking deve scalare oltre i cloud ibridi, microservizi distribuiti e workload misti. Le organizzazioni spesso faticano a mantenere logiche di masking coerenti tra database relazionali, store NoSQL e repository non strutturati come object storage o log.
- Enforcement della policy cross-piattaforma: Applicare regole di masking uniformemente su PostgreSQL, Oracle, SQL Server, MongoDB e Amazon S3 — garantendo comportamento coerente e conformità indipendentemente dalla tecnologia backend.
- Supporto per dati non strutturati e semi-strutturati: Mascherare valori sensibili incorporati in JSON, XML, file di log e contenuti generati dagli utenti utilizzando regole basate su regex o dizionario.
- Automazione masking in pipeline CI/CD: Integrare la validazione del masking nelle pipeline DevOps includendo le regole DataSunrise durante i workflow pre-deployment. Prevenire il rilascio di campi sensibili non mascherati in ambienti di staging o test.
- Framework di validazione e QA: Eseguire controlli automatici per assicurarsi che le regole di masking non compromettano analisi, dashboard o logica applicativa a valle.
- Versioning delle policy e rollback: Mantenere policy di masking versionate che possono essere aggiornate o ripristinate senza downtime — fondamentale per ambienti agili e per adattarsi a cambi regolatori.
Con queste capacità, il data masking si evolve da controllo isolato a livello silos in un livello dinamico e centralizzato di protezione dati. Invece di affidarsi a script ad hoc o patch di sicurezza isolate, i team ottengono un motore di enforcement unificato capace di adattarsi a qualsiasi ambiente — cloud-native, legacy o entrambi.
FAQ sul Data Masking
Qual è lo scopo del data masking?
Il data masking sostituisce i valori sensibili con surrogati realistici per prevenire accessi non autorizzati. Permette l’uso sicuro dei dataset in test, analisi e condivisione con fornitori senza esporre le informazioni originali.
In cosa si differenzia il data masking dalla tokenizzazione?
Il masking crea surrogati non reversibili per privacy e conformità, mentre la tokenizzazione sostituisce i valori con token memorizzati in un vault. La tokenizzazione supporta il recupero reversibile, risultando ideale per i processi di pagamento secondo PCI DSS.
Quali framework di conformità richiedono il data masking?
Framework come GDPR (pseudonimizzazione), HIPAA (de-identificazione) e PCI DSS (masking dei dati dei titolari di carta) richiamano esplicitamente il masking o controlli equivalenti per proteggere i campi sensibili.
Quando usare il masking dinamico rispetto a quello statico?
- Masking dinamico: Offuscamento in tempo reale durante l’esecuzione della query; ideale per database di produzione con accesso basato sui ruoli.
- Masking statico: Crea copie sanificate dei database; ottimo per sviluppo, testing e collaborazione con fornitori.
Quali sono i requisiti essenziali per un masking efficace?
- Preservare formati realistici e logica di business.
- Garantire trasformazioni irreversibili.
- Applicare regole coerenti e ripetibili tra gli ambienti.
- Mantenere bassa latenza nei sistemi di produzione.
Quali strumenti semplificano il masking a livello enterprise?
DataSunrise offre masking centralizzato statico e dinamico con policy consapevoli dei ruoli, generazione di report regolatori e integrazione nelle pipeline DevOps—eliminando script ad hoc e soluzioni isolate.
Il Futuro del Data Masking
Il data masking ha superato di gran lunga il suo scopo originario di nascondere numeri di carta di credito o identificatori clienti negli ambienti di test. Oggi rappresenta un livello dinamico e intelligente di sicurezza aziendale. Le innovazioni emergenti stanno trasformando il modo in cui il masking viene scoperto, distribuito e mantenuto su scala. La scoperta dati assistita dall’AI ora consente ai sistemi di rilevare e classificare automaticamente informazioni sensibili tra fonti strutturate e non strutturate, mentre approcci policy-as-code permettono alle organizzazioni di versionare, verificare e applicare regole di masking in modo coerente lungo pipeline CI/CD e workflow DevOps.
I principali provider cloud e di analytics stanno inoltre integrando capacità native di masking direttamente nei loro ecosistemi, garantendo che i dati sensibili rimangano protetti durante l’ingestione, la trasformazione e le query analitiche. Ciò include l’applicazione automatica del masking durante lo spostamento dei dati tra ambienti — come tra produzione, test e pipeline di training AI — riducendo la probabilità di esposizione durante processi di elaborazione su larga scala.
Come parte di una strategia unificata di protezione dati, le tecnologie avanzate di masking si integrano ora senza soluzione di continuità con il monitoraggio attività database, automazione della conformità e scoperta di dati sensibili. Insieme formano un tessuto di sicurezza adattativo capace di rispondere a minacce in evoluzione, requisiti normativi e esigenze di business. Nei prossimi anni, il masking non sarà più visto solo come un controllo privacy, ma come una salvaguardia proattiva guidata dall’AI, centrale nella governance moderna dei dati e nella trasformazione digitale sicura.
Masking Nativo vs. DataSunrise
| Capacità | Masking Nativo del Database | DataSunrise |
|---|---|---|
| Copertura Cross-Database | Limitata (solo SQL Server, Oracle) | Sì — Oracle, PostgreSQL, MySQL, MongoDB, SQL Server, DB cloud |
| Opzioni Dinamiche e Statiche | Solo una o l’altra, a seconda del motore | Entrambe, configurate centralmente |
| Enforcement Policy | Manuale, specifico database | Consapevole dei ruoli, policy-as-code, versionate |
| Reportistica di Conformità | Non integrata | Report predefiniti GDPR, HIPAA, PCI DSS, SOX |
| Integrazione | Minima | IAM, SIEM, CI/CD, pipeline cloud-native |
Il masking nativo offre un punto di partenza, ma DataSunrise fornisce controlli a livello enterprise e cross-piattaforma.
Conclusioni
Con la continua crescita dei volumi di dati gestiti su sistemi e architetture diversificate, la protezione delle informazioni sensibili è diventata sia una priorità strategica che un obbligo normativo. Il data masking si è affermato come uno dei metodi più affidabili per prevenire accessi non autorizzati ai campi sensibili, assicurando che informazioni personali e riservate rimangano nascoste mentre i dataset restano pienamente funzionali per usi legittimi. Ciò consente ai team di eseguire analisi, collaborare con fornitori esterni e condurre attività di sviluppo o testing senza esporre dati reali — preservando la privacy, favorendo la conformità e mantenendo l’efficienza operativa.
DataSunrise semplifica e automatizza il masking a livello enterprise su infrastrutture on-premises, ibride e multi-cloud. La sua piattaforma unificata supporta l’intero ciclo di vita della protezione dei dati — incluse scoperta dati sensibili, classificazione automatica, masking dinamico e statico, gestione granulare delle policy e reportistica pronta per audit. Funzionalità come il Masking Statico forniscono un modo sicuro e coerente per preparare dataset sicuri per sviluppo, analisi e collaborazione esterna. Con automazione intelligente, basso impatto sulle prestazioni e ampia compatibilità con le principali tecnologie database, DataSunrise consente alle organizzazioni di applicare controlli di privacy rigorosi, rispettare normative globali e alimentare l’innovazione guidata dai dati in modo sicuro. In un mondo dove i rischi di esposizione dati continuano a crescere, una strategia moderna e automatizzata di masking è essenziale per la sicurezza e la resilienza a lungo termine.
Proteggi i tuoi dati con DataSunrise
Metti in sicurezza i tuoi dati su ogni livello con DataSunrise. Rileva le minacce in tempo reale con il Monitoraggio delle Attività, il Mascheramento dei Dati e il Firewall per Database. Applica la conformità dei dati, individua le informazioni sensibili e proteggi i carichi di lavoro attraverso oltre 50 integrazioni supportate per fonti dati cloud, on-premises e sistemi AI.
Inizia a proteggere oggi i tuoi dati critici
Richiedi una demo Scarica oraSuccessivo
