
How Self-Service Data is Revolutionizing Business Decision-Making

What is Self Service Data(SSD)?
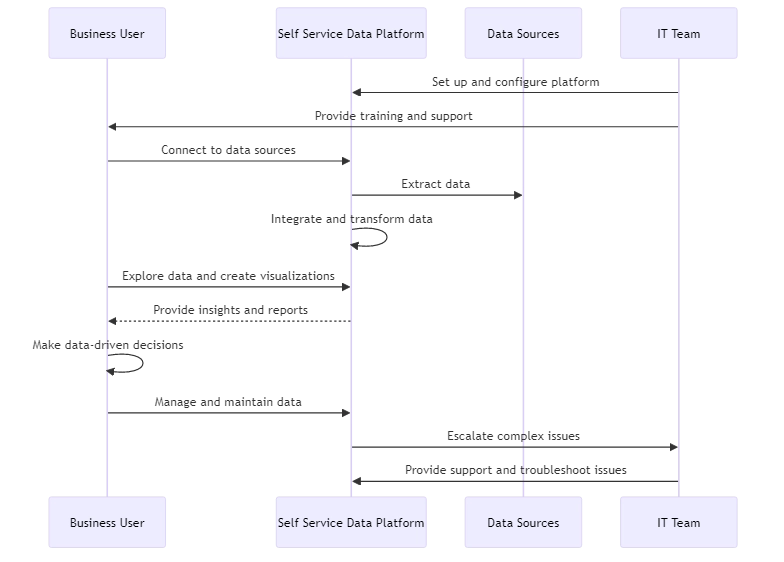
In today’s fast-paced, data-driven business world, organizations need efficient ways to leverage their data assets. Self service data allows business users to access, analyze, and manage data without needing help from IT teams. SSD makes it easier for users to access data and make decisions quickly.
SSD encompasses two main areas: SSD analytics and SSD management. Let’s delve deeper into each of these components.
Self Service Data Analytics
Self service data analytics allows business users to explore data, create visualizations, and derive insights independently. Users can use user-friendly BI and analytics tools to interact with data directly. They do not have to wait for reports from data analysts.
Some key benefits of SSD analytics include:
- Faster time-to-insight: Users can quickly answer business questions without delays.
- Increased agility: Businesses can respond to changing market conditions and opportunities more nimbly.
- Reduced burden on IT: With users serving themselves, IT teams can focus on more strategic initiatives.
For example, consider a marketing analyst who wants to evaluate the effectiveness of a recent email campaign. She can easily get information, make a dashboard with key numbers, and share ideas with her team without IT help.
Here’s a simple Python script that demonstrates connecting to a PostgreSQL database and querying email campaign data:
import psycopg2
conn = psycopg2.connect(
host="localhost",
database="marketing",
user="analyst",
password="password"
)
cur = conn.cursor()
cur.execute("""
SELECT
campaign_name,
SUM(num_delivered) AS total_delivered,
SUM(num_opened) AS total_opened,
SUM(num_clicked) AS total_clicked
FROM email_campaigns
WHERE campaign_date
BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY campaign_name;
""")
results = cur.fetchall()
for row in results:
campaign_name, total_delivered, total_opened, total_clicked = row
open_rate = total_opened / total_delivered * 100
click_rate = total_clicked / total_delivered * 100
print(f"{campaign_name}: Delivered={total_delivered}, Open Rate={open_rate:.2f}%,
Click Rate={click_rate:.2f}%")
cur.close() conn.close()
This script connects to a database for marketing. It looks at email campaign data. It shows the important numbers for each campaign in the first quarter of 2023.
Self Service Data Management
Self service analytics is about using data, while SSD management is about managing and maintaining the data. This includes tasks like data integration, quality assurance, and governance.
SSD management platforms have user-friendly interfaces. Users can connect data sources, clean and transform data, and set business rules easily. This allows domain experts to take ownership of data management tasks without deep technical skills.
Benefits of SSD management include:
- Improved data quality: Data stewards can apply their business knowledge to ensure data is accurate and fit-for-purpose.
- Increased efficiency: Automating data management tasks through self service tools saves time and resources.
- Better governance: Users work within defined guardrails, ensuring compliance with data policies.
Imagine a sales operations manager who needs to integrate Salesforce data with the company’s ERP system. He can easily map data, set rules for changes, and schedule automatic updates using a self-service data tool.
However, some data management tasks may still require code. Here’s an example of using Python and the Pandas library to clean and transform a CSV file:
import pandas as pd
df = pd.read_csv('salesforce_data.csv')
# Remove rows with missing values
df = df.dropna()
# Rename columns to match ERP system
df = df.rename(columns={
'Account': 'CustomerID',
'Industry': 'Vertical',
'AnnualRevenue': 'Revenue'
})
# Convert revenue to numeric type
df['Revenue'] = pd.to_numeric(df['Revenue'], errors='coerce')
# Filter for active customers
df = df[df['Status'] == 'Active']
# Save cleaned data to new file
df.to_csv('salesforce_data_cleaned.csv', index=False)
This script cleans up a Salesforce export file by removing empty values, renaming columns, changing data formats, and organizing rows. The system saves the cleaned data to a new file for easy loading into the ERP system.
Key Enabling Technologies
Several technologies have converged to make SSD a reality:
- Cloud computing: Cloud data warehouses and analytics platforms provide scalable, on-demand resources to store and process data. Users can spin up new projects quickly without provisioning infrastructure.
- NoSQL databases: Flexible, schema-less databases can ingest diverse data types easily. This allows users to work with the semi-structured and unstructured data common in self service scenarios.
- Data visualization: Modern BI tools offer drag-and-drop interfaces for exploring data and building interactive dashboards. Advanced features like natural language querying make analytics even more approachable for business users.
- AI and machine learning: Intelligent algorithms can automate complex data management tasks and surface hidden insights. Features like smart data discovery and automated data prep streamline self service workflows.
Implementing Self Service Data
While the promise of SSD is compelling, implementing it successfully requires careful planning and execution. Some key considerations include:
- Defining clear roles and responsibilities: Make it clear what tasks business users can do on their own and what tasks are still managed by IT.
- Providing training and support: Ensure business users are proficient with self service tools and understand data management best practices. Offer ongoing education and support resources.
- Ensuring data security and compliance: Implement strict access controls and data governance policies to mitigate risks. Regularly audit user activity and permissions.
- Starting small and iterating: Start with a specific example to show the benefits before making self-service options available to everyone. Gather feedback and refine processes continuously.
Real-World Examples
Many organizations have successfully adopted SSD approaches. Here are a few examples:
- Procter & Gamble uses self service analytics to put data in the hands of over 50,000 employees globally. Business users can get answers in minutes rather than waiting weeks for reports.
- Comcast has over 2,000 users regularly interacting with its self service BI platform. The company has seen a 25% reduction in BI costs and 50% reduction in report creation time.
- Hertz uses a SSD management platform to integrate over 100 data sources. Business users can onboard new data sets in hours instead of months. Data quality has improved significantly.
Conclusion
Self service data is transforming how organizations leverage their data assets. By empowering business users with intuitive tools for data analytics and data management, companies can accelerate insights, increase agility, and drive better business outcomes.
While implementing SSD requires thoughtful change management, the benefits are clear. As data keeps growing and businesses speed up, self-service data will become even more important. Organizations that embrace this shift will be well-positioned to compete in an increasingly data-centric world.
