Data Masking
Working with data assets securely means eliminating the risk of breaches — and that’s exactly what data masking enables. Instead of exposing real information, the process replaces it with fictitious but meaningful content. Substitution can involve fixed strings or advanced techniques such as shuffling or format-preserving encryption.
Masking can be implemented in two ways: dynamic or static, depending on where the data replacement occurs. DataSunrise supports both approaches, offering comprehensive protection for your sensitive information.
Learn About Solutions in the Cloud or on-Premises
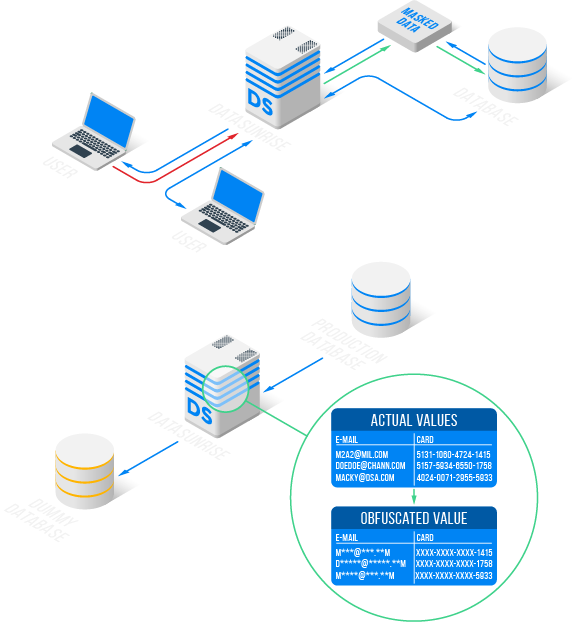
Dynamic Masking
Replacement of sensitive data in real time when the client accesses the database.
Learn MoreJoin Innovative Solutions
Download3 Key Points to Protect Your Confidential Data

Ensuring Compliance
Sensitive data is the most valuable asset of any company and pseudonymization is obligatory according to such regulations as GDPR, SOX, PCI DSS, HIPAA, and more.
With DataSunrise you can become compliant in just a few clicks.

Modern Data Masking
Built-in anonymization techniques and fully customizable data masking rules help meet strict security demands.
You can protect an entire database or apply rules to specific columns or schemas — perfect for development, testing, or training.

Reliable Protection
Prevention of sensitive data leak and exposure, complete obfuscation of sensitive data.
Data protection and De-identification of PHI, PII or other sensitive data. Easy to install, configure and manage both on-prem and in the cloud.


