
What is Data Masking?
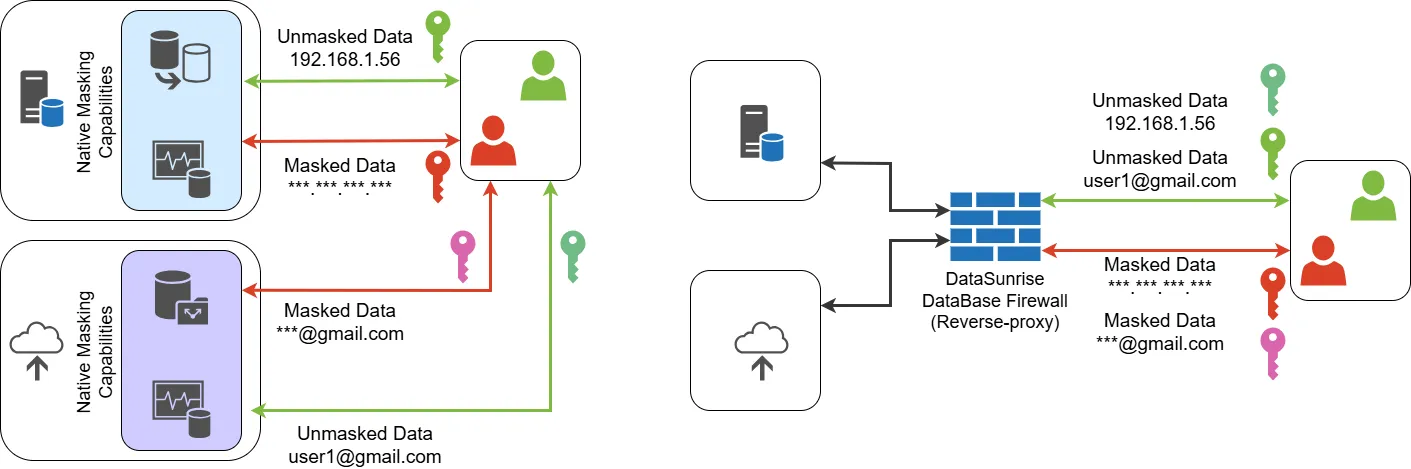
Understanding Data Masking
With data breaches becoming more common and privacy regulations growing more stringent, data masking has become an essential component of modern data security strategies. Organizations must protect sensitive information while ensuring employees, applications, and business processes can continue using data efficiently. According to recent Gartner research, data masking is recognized as a key privacy-enhancing technology, particularly in environments where data is exchanged across departments, third-party partners, and cloud services.
Data masking safeguards sensitive information by replacing confidential values with realistic but fictitious alternatives. Although the original data is concealed or transformed, the dataset retains its structure, formatting, and usability. This allows organizations to safely use information for software development, testing, analytics, and collaboration without exposing real sensitive data.
As regulatory standards such as GDPR, HIPAA, and PCI DSS continue to evolve, many organizations adopt centralized masking policies to provide consistent protection across their environments. DataSunrise supports both static and dynamic data masking through flexible policy management that can be configured according to user roles, access permissions, and contextual requirements.
When implemented as part of a broader security strategy, data masking strengthens data governance, enables secure data sharing, minimizes the risk of unauthorized exposure, and helps organizations maintain compliance across on-premises, cloud, and hybrid environments.
Why Data Masking Matters in Modern Security Strategies
Safeguarding sensitive information requires more than relying on encryption. Data masking adds an additional layer of protection by restricting visibility of confidential data based on least-privilege principles, ensuring that only authorized users with a legitimate business need can access original values.
Organizations operating under regulations such as GDPR, HIPAA, and PCI DSS are required to implement controls that protect sensitive information. Data masking supports these obligations by enabling developers, analysts, and other authorized personnel to use realistic datasets without exposing genuine confidential data.
In the absence of effective masking, users with valid system permissions may still gain access to information beyond their job responsibilities, increasing the risk of accidental exposure, insider threats, and compliance violations. Deploying data masking across development, testing, reporting, analytics, and third-party environments helps reduce these risks while preserving the accuracy and usefulness of the underlying data.
| Regulation | Clause | Masking Requirement |
|---|---|---|
| GDPR | Art. 32 | Pseudonymisation of personal data |
| PCI DSS 4.0 | 3.4 | Render PAN unreadable (tokenize, mask) |
| HIPAA | §164.514(b) | De-identify 18 PHI identifiers |
| DORA | Art. 9 | Protect datasets used in resilience testing |
Dynamic masking controls how users see live production data, while static masking generates sanitized copies for development, testing, or external use. DataSunrise simplifies both approaches with clear configuration tools and reliable support for complex schemas and hybrid cloud environments.
Data Masking — Summary, Steps, and Quick Checks
Summary
- Purpose: limit exposure of sensitive values while preserving dataset utility.
- Modes: dynamic (at query time), static (sanitized copies), in-place (non-prod datasets).
- Fit: aligns with GDPR pseudonymization, HIPAA de-identification, PCI DSS masking.
Implementation Steps
- Discover and classify fields (PII/PHI/PCI) across sources.
- Define roles and required visibility levels.
- Select mode per use case (dynamic for prod; static for dev/test/vendor).
- Choose algorithms (redaction, substitution, FPE, tokenization) per column type.
- Configure rules at schema/table/column level; preserve referential integrity.
- Validate in staging; confirm application behavior and analytics accuracy.
- Monitor performance and adjust scope to control latency.
- Document policies; schedule periodic reviews as schemas evolve.
Algorithm Selection
| Data Type | Recommended Approach | Notes |
|---|---|---|
| PAN / card data | Mask BIN + last 4 / tokenization | PCI DSS Req. 3.4 alignment |
| Emails / usernames | Format-preserving substitution | Keep domain/user shape for UX |
| Free-text PII | Dictionary/regex substitution | Scan logs, comments, JSON blobs |
| Dates / amounts | Noise injection / bucketing | Preserve order/statistics |
| IPs / locations | Generalization / randomization | Maintain region if needed |
Quick Checks
- Do masked columns remain valid for application logic and reports?
- Are transformations irreversible for non-privileged users?
- Is referential integrity preserved across related tables?
- Is added latency within target SLOs under peak load?
Common Use Cases for Data Masking
Organizations use data masking in many situations to protect sensitive information while keeping business processes running:
- Vendor collaboration: Organizations can share datasets with third-party partners without exposing customer details or confidential business information. Data masking allows vendors, contractors, and service providers to complete their work without seeing raw sensitive data, which reduces breach risks in external environments with weaker controls.
- Error prevention: Masking helps prevent accidental exposure caused by operator mistakes, administrative errors, or incorrect system settings. It adds another layer of protection, so even if privileged data is exported, logged, or accessed improperly, sensitive fields remain unreadable and the damage from human error stays limited.
- Development and testing: Teams can use realistic datasets for application testing, machine learning, and performance tuning without creating privacy risks. Masking keeps the structure and format of production data intact, supporting debugging, load testing, model training, and integration checks while removing real customer identities and regulated fields.
- Analytics and reporting: Analysts and data scientists can work with production-like data while maintaining compliance with privacy rules. Masked datasets preserve important patterns and relationships, enabling accurate reports, dashboards, and forecasts without exposing PII or violating standards such as GDPR, HIPAA, or PCI DSS.
Examples of Masked Data
Masking strategies often vary depending on compliance requirements, sensitivity classifications, and user permission levels. Certain systems require complete concealment of sensitive information, while others use format-preserving masking to maintain data usability for business operations. DataSunrise supports both approaches across structured databases as well as unstructured data environments.
-- Before masking: 4024-0071-8423-6700 -- After masking: XXXX-XXXX-XXXX-6700
| Masking Method | Original Data | Masked Data |
|---|---|---|
| Credit card masking | 4111 1111 1111 1111 | 4111 **** **** 1111 |
| Email masking | [email protected] | j***e@e*****e.com |
| URL masking | https://www.example.com/user/profile | https://www.******.com/****/****** |
| Phone number masking | +1 (555) 123-4567 | +1 (***) ***-4567 |
| IP address randomization | 192.168.1.1 | 203.45.169.78 |
| Date randomization with year preservation | 2023-05-15 | 2023-11-28 |
| Custom function masking | Secret123! | S****t1**! |
| Dictionary-based substitution | John Smith, Software Engineer, New York | Ahmet Yılmaz, Data Analyst, Chicago |
Implementation Steps for Data Masking
Successful data masking implementation requires systematic planning and execution across multiple phases:
- Data discovery and classification: Locate sensitive fields throughout your infrastructure using automated discovery tools that identify PII, financial data, and regulated information across databases and applications.
- Policy mapping and role definition: Establish comprehensive masking policies based on user roles, data sensitivity classifications, and regulatory requirements specific to your industry and geographic presence.
- Rule configuration and testing: Define granular masking rules at the schema, table, column, or data-type level, ensuring that masked data maintains referential integrity and business logic consistency.
- Validation and deployment: Thoroughly test masking functionality across staging environments before production deployment, validating that applications continue to function correctly with masked datasets.
- Monitoring and maintenance: Establish ongoing monitoring to ensure masking policies remain effective as data structures evolve and new sensitive data types are introduced.
Types of Data Masking
| Algorithm | Keeps Format? | Re-ID Risk | Best For |
|---|---|---|---|
| Redaction | No | Lowest | Logs, screenshots |
| Tokenization | Yes | Very low* | Payment tokens |
| Randomization | Optional | Low | PII datasets |
| Format-Preserving Encryption (FPE) | Yes | Very low | Legacy apps |
*Assuming vault‐based detokenization controls.
Dynamic Masking
Dynamic masking obscures sensitive data while queries are processed, leaving the original information unchanged. It provides flexible, real-time access control for multi-user production environments where data visibility depends on user roles, permissions, and access conditions.
CREATE VIEW masked_customers AS
SELECT
id,
name,
CASE
WHEN current_user = 'admin_user' THEN credit_card
ELSE regexp_replace(credit_card, '^\d{4}-\d{4}-\d{4}-(\d{4})$', 'XXXX-XXXX-XXXX-\1')
END AS credit_card
FROM customers;
Static Masking
Static masking creates permanently sanitized copies of production databases, enabling secure data sharing and distribution without ongoing privacy concerns. These masked datasets can be safely exported, shared with external partners, or used for long-term analytics projects without violating privacy regulations. This approach is particularly valuable for ISO 27001 compliance and regulatory audit preparation.
In-Place Masking
In-place masking transforms data directly within existing non-production databases, particularly during pre-release testing cycles or sandbox environment preparation. This approach eliminates the need for duplicate storage infrastructure while ensuring development teams work with realistic but protected datasets.
Essential Masking Requirements
Effective data masking implementations must satisfy several critical requirements to maintain both security and operational utility:
- Realistic data preservation: Masked data must look and behave like real data to ensure seamless integration with existing systems. The substituted values should maintain the same structure, format, and statistical distribution as the originals — for instance, masked credit card numbers should pass checksum validation, and masked dates should remain within logical time ranges. This realism allows applications, analytics, and test environments to operate normally without risking exposure of sensitive information.
- Irreversible transformation: The masking process must be designed so that recovering the original data is mathematically impossible. Strong randomization and cryptographic algorithms prevent any chance of reverse engineering or pattern-based re-identification. This one-way transformation is a cornerstone of compliance with regulations such as GDPR and HIPAA, which require that anonymized data cannot be linked back to individuals.
- Consistent behavior: To maintain data integrity, masking logic should yield identical masked results for the same input across all systems and time frames. For example, if a customer ID or employee number appears in multiple tables, it must be masked in the same way everywhere to preserve relational accuracy. This consistency supports reliable testing, reporting, and auditing without compromising security.
- Performance optimization: Effective masking must balance security with efficiency. The process should introduce minimal overhead and avoid slowing down production systems or analytics queries. Optimized masking algorithms and parallel processing techniques allow organizations to protect large datasets quickly — ensuring strong security controls without affecting operational performance or user experience.
Data Masking in Compliance Frameworks
Regulators frame data masking as pseudonymization, de-identification, or data minimization. Below is how major frameworks describe requirements and how masking addresses them:
| Framework | Requirement | Masking Alignment |
|---|---|---|
| GDPR | Art. 32 — pseudonymize or anonymize personal data | Dynamic masking prevents exposure of raw PII to non-privileged users. |
| HIPAA | §164.514 — de-identify 18 PHI identifiers | Static masking creates PHI-free datasets for testing, training, and research. |
| PCI DSS | Req. 3.4 — render PAN unreadable except BIN + last 4 digits | Format-preserving masking ensures compliance for payment card data. |
| SOX | Maintain integrity of financial reporting data | Masking test copies prevents leakage of sensitive financial records. |
By aligning masking policies with compliance mandates, DataSunrise enables enterprises to protect sensitive information while producing auditor-ready evidence across databases, clouds, and hybrid environments.
Business Outcomes of Data Masking
- Reduced breach exposure: Up to 60% fewer sensitive fields visible to unauthorized users
- Compliance efficiency: Audit evidence generated in hours, not weeks
- Operational speed: QA and testing cycles accelerate by ~30% with safe, production-like datasets
- Lower legal risk: Direct alignment with GDPR, HIPAA, PCI DSS clauses
Industry Applications
- Finance: Masking PANs and PII for PCI DSS and SOX reporting
- Healthcare: De-identifying PHI to meet HIPAA privacy rules
- SaaS & Cloud: Multi-tenant masking to ensure GDPR-compliant data separation
- Retail: Protecting customer data in analytics pipelines without losing insight
Native Data Masking Snippets Across Platforms
Most databases provide only limited native masking support, which often requires custom code or extensions. Below are examples from SQL Server and Oracle:
SQL Server: Built-in Dynamic Masking
-- Mask credit card column with partial exposure
CREATE TABLE Customers (
Id INT IDENTITY PRIMARY KEY,
FullName NVARCHAR(100),
CreditCard VARCHAR(19) MASKED WITH (FUNCTION = 'partial(0,"XXXX-XXXX-XXXX-",4)')
);
-- Result: 4111-2222-3333-4444 → XXXX-XXXX-XXXX-4444
Oracle: Virtual Private Database (VPD) Policy
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'HR',
object_name => 'EMPLOYEES',
policy_name => 'mask_ssn_policy',
function_schema => 'SEC_ADMIN',
policy_function => 'mask_ssn_fn',
statement_types => 'SELECT'
);
END;
/
Both examples demonstrate platform-native masking, but they lack the flexibility to apply role-aware rules across multiple databases simultaneously.
Masking in Compliance Context
Different regulations frame masking as either pseudonymization, de-identification, or data minimization. A typical requirement is ensuring irreversible transformation while maintaining usability. Below is a quick compliance mapping:
| Framework | Masking Objective | Native Gap |
|---|---|---|
| GDPR | Pseudonymize personal data | No consistent role-based masking |
| HIPAA | De-identify PHI identifiers | No field-level policy enforcement |
| PCI DSS | Mask PAN except BIN & last 4 | Platform-specific, not unified |
Native masking satisfies basic clauses, but unified platforms like DataSunrise provide cross-regulation coverage out of the box.
Data Masking with DataSunrise
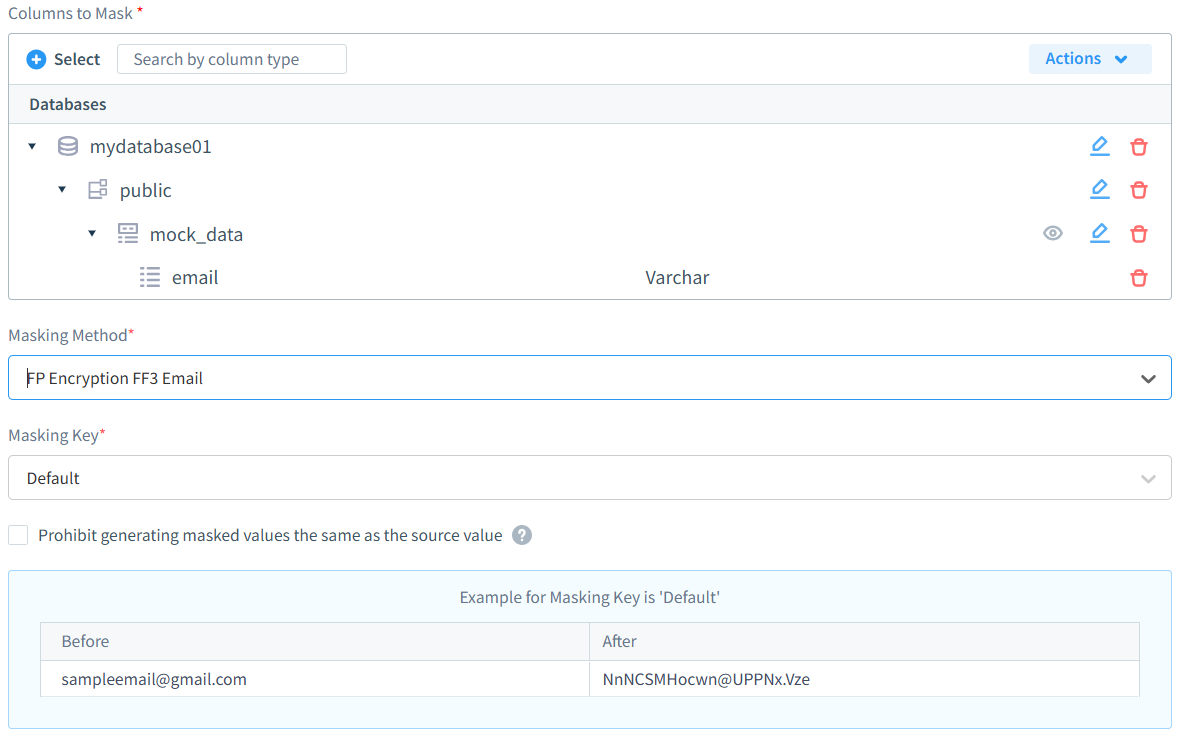
DataSunrise provides enterprise-grade masking capabilities designed for modern data protection requirements:
- Flexible masking modes: Comprehensive support for real-time dynamic masking and offline static masking techniques, allowing organizations to choose optimal approaches for different use cases.
- Intelligent access controls: Role-aware masking policies and format-preserving algorithms that maintain data utility while enforcing strict privacy protections.
- Enterprise integrations: Seamless integration with existing IAM systems, SIEM platforms, and policy enforcement engines to streamline security operations and compliance reporting.
- Compliance automation: Built-in audit logging and reporting capabilities specifically designed for GDPR, PCI DSS, HIPAA, and SOX compliance requirements.
- Scalable architecture: Support for cloud-native, hybrid, and legacy database environments with minimal performance impact and high availability.
Scaling Data Masking Across Complex Environments
As architectures evolve, data masking must scale across hybrid clouds, distributed microservices, and mixed workloads. Organizations often struggle to maintain consistent masking logic across relational databases, NoSQL stores, and even unstructured repositories like object storage or logs.
- Cross-platform policy enforcement: Apply masking rules uniformly across PostgreSQL, Oracle, SQL Server, MongoDB, and Amazon S3 — ensuring consistent behavior and compliance regardless of backend technology.
- Unstructured and semi-structured support: Mask sensitive values embedded in JSON, XML, log files, and user-generated content using regex-driven or dictionary-based rules.
- CI/CD masking automation: Embed masking validation into DevOps pipelines by integrating DataSunrise masking rules into pre-deployment workflows. Prevent unmasked sensitive fields from leaking into staging or test environments.
- Validation and QA frameworks: Run automated sanity checks to ensure that masking rules don’t break downstream analytics, reporting dashboards, or application logic.
- Policy versioning and rollback: Maintain versioned masking policies that can be rolled back or updated without downtime — critical for agile environments and regulatory change adaptation.
With these capabilities in place, data masking evolves from a siloed control into a dynamic, centralized data protection layer. Instead of relying on ad hoc scripts or isolated security patches, teams gain a unified enforcement engine capable of adapting to any environment — cloud-native, legacy, or both.
Data Masking FAQ
What is the purpose of data masking?
Data masking protects sensitive information by replacing original values with realistic but fictitious alternatives. This allows organizations to use production-like datasets for testing, analytics, development, and third-party collaboration without revealing confidential data.
How is data masking different from tokenization?
Data masking permanently obscures sensitive values using non-reversible substitutes for privacy and compliance purposes. Tokenization, in contrast, replaces data with reference tokens linked to the original values stored in a secure vault, allowing authorized users to restore the original information when needed. This makes tokenization particularly suitable for payment environments governed by PCI DSS.
Which compliance frameworks require data masking?
Frameworks such as GDPR (pseudonymization), HIPAA (de-identification), and PCI DSS (masking cardholder data) explicitly call out masking or equivalent controls to protect sensitive fields.
When should dynamic vs. static masking be used?
- Dynamic masking: Real-time obfuscation during query execution; ideal for production databases with role-based access.
- Static masking: Creates sanitized database copies; best for development, testing, and vendor collaboration.
What are essential requirements for effective masking?
- Preserve realistic formats and business logic.
- Ensure transformations are irreversible.
- Apply consistent, repeatable rules across environments.
- Maintain low latency in production systems.
What tools simplify enterprise-wide data masking?
DataSunrise provides centralized static and dynamic masking with role-aware policies, regulatory report generation, and integration into DevOps pipelines—eliminating ad hoc scripts and siloed solutions.
The Future of Data Masking
Data masking has evolved far beyond its original purpose of concealing credit card numbers or customer identifiers in test environments. Today, it represents a dynamic and intelligent layer of enterprise security. Emerging innovations are transforming how masking is discovered, deployed, and maintained at scale. AI-assisted data discovery now enables systems to automatically detect and classify sensitive information across structured and unstructured sources, while policy-as-code approaches allow organizations to version, audit, and enforce masking rules consistently across CI/CD pipelines and DevOps workflows.
Major cloud and analytics providers are also embedding native masking capabilities directly into their ecosystems, ensuring that sensitive data remains protected throughout ingestion, transformation, and analytical querying. This includes automated enforcement of masking during data movement between environments — such as between production, testing, and AI training pipelines — thereby reducing the likelihood of exposure during large-scale processing.
As part of a unified data protection strategy, advanced masking technologies now integrate seamlessly with database activity monitoring, compliance automation, and sensitive data discovery. Together, they form an adaptive security fabric capable of responding to evolving threats, regulatory requirements, and business demands. In the coming years, masking will no longer be viewed merely as a privacy control, but as a proactive, AI-driven safeguard central to modern data governance and secure digital transformation.
Native Masking vs. DataSunrise
| Capability | Native Database Masking | DataSunrise |
|---|---|---|
| Cross-Database Coverage | Limited (SQL Server, Oracle only) | Yes — Oracle, PostgreSQL, MySQL, MongoDB, SQL Server, cloud DBs |
| Dynamic vs Static Options | One or the other, depending on engine | Both, centrally configured |
| Policy Enforcement | Manual, DB-specific | Role-aware, policy-as-code, versioned |
| Compliance Reporting | Not built-in | Pre-built GDPR, HIPAA, PCI DSS, SOX reports |
| Integration | Minimal | IAM, SIEM, CI/CD, cloud-native pipelines |
Native masking offers a starting point, but DataSunrise provides enterprise-grade, cross-platform controls.
Conclusion
As data ecosystems grow across cloud services, distributed architectures, and hybrid environments, protecting sensitive information remains a major business requirement. Strong data protection supports more than regulatory compliance; it also helps preserve operational resilience, build customer confidence, and reduce security exposure. Data masking supports these goals by replacing confidential values with realistic but non-sensitive alternatives, enabling safer use of data in testing, development, analytics, and other business processes.
Data masking also strengthens least-privilege access strategies and secure data-sharing practices. Internal users, contractors, vendors, and partners can work with usable datasets without viewing genuine confidential information. By enforcing consistent masking rules across different environments, organizations gain better control over how sensitive data is accessed, distributed, and processed.
DataSunrise provides centralized data masking across cloud, on-premises, and hybrid infrastructures. The platform supports the full data protection lifecycle, including sensitive data discovery, classification, dynamic and static masking, policy administration, and compliance reporting. Capabilities such as Static Data Masking help organizations generate secure, production-like datasets for non-production use while maintaining data consistency and structure.
Beyond masking, DataSunrise combines auditing, database activity monitoring, and security policy enforcement within a single platform. This unified approach improves visibility into data access, supports the detection of suspicious behavior, and helps meet compliance requirements through detailed audit trails. With centralized management, automation, and broad platform compatibility, DataSunrise enables organizations to strengthen data security, reduce compliance complexity, and support sustainable business growth.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now