
What is Partitioning?
As databases grow in size and complexity, performance and maintainability often suffer. Partitioning offers a solution by breaking large database objects—like tables and indexes—into smaller, more manageable segments. This technique is widely used to accelerate query execution, reduce storage costs, and simplify data lifecycle management in enterprise systems and cloud-based platforms.
The main advantages include better controllability, performance, and availability. This approach allows administrators to optimize and maintain different parts of the database independently, improving query efficiency and system uptime while enabling more targeted management strategies.
- In some cases, this method improves performance when accessing partitioned tables.
- It can also define leading columns in indexes, reducing index size and increasing memory access efficiency. When a large portion of a section is used in the result set, scanning that section is much faster than scanning scattered data.
- Massive uploading and deletion are possible by simply adding or removing sections, which enhances performance.
- Rarely accessed information can be moved to lower-cost storage systems.
In DataSunrise, large Audit Storage tables are divided into smaller sections to improve access and performance. DataSunrise’s Database Activity Monitoring stores results directly in this internal database.
- Administrators can manage data more easily by splitting it into time-based segments, which they can then archive or exclude from queries.
- Read/write speed improves significantly when interacting with storage tables.
- Deleting outdated audit logs becomes faster and more efficient.
DataSunrise supports this technique for the following Audit Storage database platforms:
- PostgreSQL
- MySQL
- MS SQL Server
Partitioning Parameters
Can be found in System Settings -> Additional parameters.
- Partitions Length (days) – Defines the duration of each section (or minutes if AuditPartitionShort = 1). Located in System Settings -> Audit Storage. Changing this resets the structure: existing sections are removed and replaced with new ones.
- AuditPartitionCountCreatedInAdvance – Number of future-ready partitions. These empty slots enable uninterrupted data writing.
- AuditPartitionFirstEndDateTime – Specifies the first section’s upper time boundary. Useful for aligning partitions with a clear time anchor (e.g., Monday 00:00:00).
Partitioning for Compliance and Retention
Many data regulations require timely deletion or archiving of sensitive data. Partitioning makes it easier to manage data lifecycles by isolating older records into distinct segments. This enables faster deletion, easier archival, and improved audit readiness—especially in industries bound by strict retention policies like healthcare, finance, and telecommunications.
Partitioning in Modern Data Environments
In big data environments, data segmentation is critical. Many cloud platforms now offer automatic partitioning options. AWS Redshift uses distribution styles for optimal data arrangement. Azure Synapse employs distribution methods to enhance query performance. Partition-based logic also works well with data lakes handling petabytes of information. It enables faster querying in BI applications and supports time-based access to historical or archival data. Proper strategies help reduce storage costs and align with retention policies.
Effective Data Distribution Strategies
Creating effective database distribution strategies requires careful planning based on access patterns and business requirements. Range organization works best for sequential values like dates, allowing teams to quickly access recent data while archiving older information.
Hash distribution spreads data evenly across storage segments, ideal for load balancing in high-concurrency environments. List-based approaches organize records by specific categorical values, making them perfect for geographic or departmental segmentation.
Many organizations implement hybrid methods, combining multiple distribution techniques to maximize performance benefits while minimizing maintenance overhead. Regular pruning analysis ensures queries consistently target only the necessary data segments, delivering optimal performance as data volumes grow.
Partition Management in DataSunrise
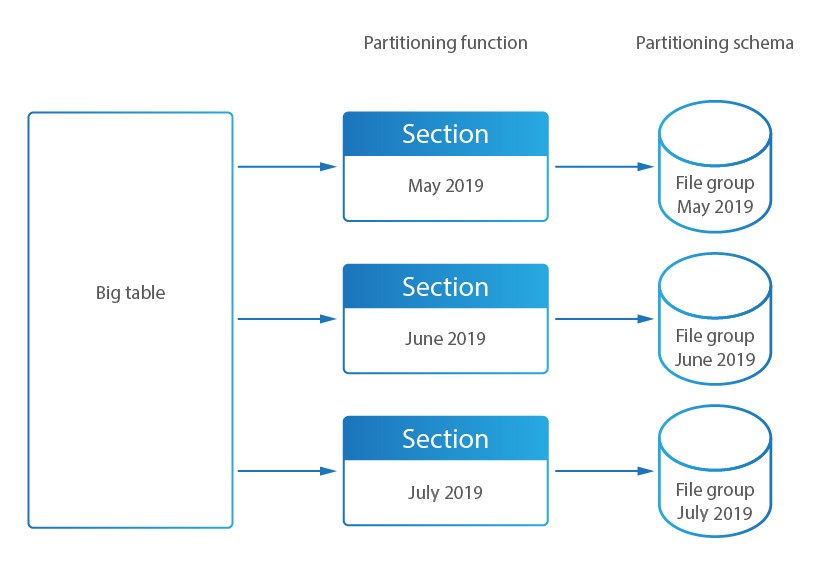
DataSunrise supports automated data segmentation: it creates required tables (for PostgreSQL), maintains up-to-date functions, schemes, file groups, and indexes (for MS SQL), and adjusts keys to match native partitioning models (for MySQL). DataSunrise manages the entire section lifecycle, from creation to cleanup.
The system runs SELECTs through the master table, while it directs INSERT/UPDATEs to specific sections (except for MS SQL Server), improving write performance.
Partitions’ and Tables’ Names
PostgreSQL creates child tables as partitions using the format <table_name>_p<datetime>, where <datetime> is the upper boundary in YYYYMMDDhhmm format.
MySQL uses native mechanisms for partitioning. It generates partition names using the format p<datetime>, following the same timestamp convention.
MS SQL Server applies partitioning using a scheme-based approach instead of child tables.
