
AI Data Generator

As data-driven insights have become crucial for businesses of all sizes, the demand for high-quality, diverse datasets has skyrocketed. However, obtaining real-world data can be challenging, time-consuming, and often raises privacy concerns. This is where AI data generator comes into play, offering a powerful solution through synthetic data generation. Let’s dive into this fascinating world and explore how AI is transforming the landscape of data creation.
Given that DataSunrise implements its own feature-rich and easy-to-use synthetic data generation capabilities, we will delve deeper into this topic, specifically exploring the open-source tools available today.
Understanding Synthetic Data
Synthetic data is artificially created information that mimics the characteristics and statistical properties of real-world data. It’s generated using various algorithms and AI techniques, without directly copying actual data points. This approach offers numerous advantages, particularly in scenarios where real data is scarce, sensitive, or difficult to obtain.
The Need for Synthetic Data
Overcoming Data Scarcity
One of the primary reasons for using synthetic data is to overcome the shortage of real-world data. In many fields, especially emerging technologies, gathering sufficient data to train machine learning models can be challenging. AI data generators can produce vast amounts of diverse data, helping to bridge this gap.
Protecting Privacy and Security
With increasing concerns about data privacy and security, synthetic data offers a safe alternative. It allows organizations to work with data that closely resembles real information without risking the exposure of sensitive personal or business data. This is particularly crucial in industries like healthcare and finance, where data protection is paramount.
Enhancing Model Training
Synthetic data can be used to augment existing datasets, improving the performance and robustness of machine learning models. By generating additional diverse examples, AI models can learn to handle a wider range of scenarios, leading to better generalization.
Types of Synthetic Data
AI data generators can produce various types of synthetic data:
1. Numerical Data
This includes continuous values like measurements, financial figures, or sensor readings. AI generators can create numerical data with specific statistical properties, such as:
- Probability density distribution
- Mean
- Variance
- Correlation between variables
2. Categorical Data
Categorical data represents discrete categories or labels. AI generators can create synthetic categorical data while maintaining the distribution and relationships found in real-world datasets.
3. Text Data
From simple phrases to complex documents, AI can generate synthetic text data. This is particularly useful for natural language processing tasks and content generation.
4. Image Data
AI-generated images are becoming increasingly sophisticated. These can range from simple geometric shapes to photorealistic images, useful for computer vision applications.
Mechanisms for Synthetic Data Generation
Several approaches and techniques are used in AI data generation:
Statistical Modeling
This approach involves creating mathematical models that capture the statistical properties of real data. The synthetic data is then generated to match these properties.
Machine Learning-Based Generation
Advanced machine learning techniques, particularly generative models, are used to create highly realistic synthetic data. Some popular methods include:
- Generative Adversarial Networks (GANs): These involve two neural networks competing against each other, with one generating synthetic data and the other trying to distinguish it from real data.
- Variational Autoencoders (VAEs): These models learn to encode data into a compressed representation and then decode it, generating new data samples in the process.
- Transformer Models: Particularly effective for text generation, these models have revolutionized natural language processing tasks.
Rule-Based Generation
This method involves creating synthetic data based on predefined rules and constraints. It’s often used when the data needs to follow specific patterns or business logic.
AI-Based Tools in Test Data Generation
AI plays a crucial role in generating test data for software development and quality assurance. These tools can create realistic, diverse datasets that cover various test scenarios, helping to uncover potential issues and edge cases.
For example, an AI-based test data generator for an e-commerce application might create:
- User profiles with various demographics
- Product catalogs with different attributes
- Order histories with diverse patterns
This synthetic test data can help developers and QA teams ensure the robustness and reliability of their applications without using real customer data.
Generative AI in Data Creation
Generative AI represents the cutting edge of synthetic data creation. These models can produce highly realistic and diverse datasets across various domains. Some key applications include:
- Image synthesis for computer vision training
- Text generation for natural language processing
- Voice and speech synthesis for audio applications
- Time series data generation for predictive modeling
For instance, a generative AI model trained on medical images could create synthetic X-rays or MRI scans, helping researchers develop new diagnostic algorithms without compromising patient privacy.
Tools and Libraries for Synthetic Data Generation
Several tools and libraries are available for generating synthetic data. One popular option is the Python Faker library. Unlike more complex tools, it does not rely on machine learning or AI-related techniques. Instead, Faker utilizes robust, classic approaches for data generation.
Python Faker Library
Faker is a Python package that generates fake data for various purposes. It’s particularly useful for creating realistic-looking test data.
Here’s a simple example of using Faker to generate synthetic user data:
from faker import Faker
fake = Faker()
# Generate 5 fake user profiles
for _ in range(5):
print(f"Name: {fake.name()}")
print(f"Email: {fake.email()}")
print(f"Address: {fake.address()}")
print(f"Job: {fake.job()}")
print("---")
This script might produce output like:
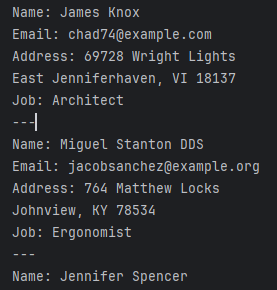
CTGAN Library
CTGAN is a Python library specifically designed for generating synthetic tabular data using Generative Adversarial Networks (GANs). It’s a part of the Synthetic Data Vault (SDV) project and is well-suited for creating synthetic versions of structured datasets. CTGAN functions much more like an AI data generator compared to Faker.
Here’s how you can use CTGAN in Python:
Here’s a basic example of how to use CTGAN (at the moment the Readme recommends installing the SDV library which provides user-friendly APIs for accessing CTGAN.):
import pandas as pd
from ctgan import CTGAN
import numpy as np
# Create a sample dataset
data = pd.DataFrame({
'age': np.random.randint(18, 90, 1000),
'income': np.random.randint(20000, 200000, 1000),
'education': np.random.choice(['High School', 'Bachelor', 'Master', 'PhD'], 1000),
'employed': np.random.choice(['Yes', 'No'], 1000)
})
print("Original Data Sample:")
print(data.head())
print("\nOriginal Data Info:")
print(data.describe())
# Initialize and fit the CTGAN model
ctgan = CTGAN(epochs=10) # Using fewer epochs for this example
ctgan.fit(data, discrete_columns=['education', 'employed'])
# Generate synthetic samples
synthetic_data = ctgan.sample(1000)
print("\nSynthetic Data Sample:")
print(synthetic_data.head())
print("\nSynthetic Data Info:")
print(synthetic_data.describe())
# Compare distributions
print("\nOriginal vs Synthetic Data Distributions:")
for column in data.columns:
if data[column].dtype == 'object':
print(f"\n{column} distribution:")
print("Original:")
print(data[column].value_counts(normalize=True))
print("Synthetic:")
print(synthetic_data[column].value_counts(normalize=True))
else:
print(f"\n{column} mean and std:")
print(f"Original: mean = {data[column].mean():.2f}, std = {data[column].std():.2f}")
print(f"Synthetic: mean = {synthetic_data[column].mean():.2f}, std = {synthetic_data[column].std():.2f}")
The code produces an output like this (notice the difference in statistical parameters):
Original Data Sample: age income education employed 0 57 25950 Master No 1 78 45752 High School No … Original Data Info: age income count 1000.00000 1000.000000 mean 53.75300 109588.821000 std 21.27013 50957.809301 min 18.00000 20187.000000 25% 35.00000 66175.250000 50% 54.00000 111031.000000 75% 73.00000 152251.500000 max 89.00000 199836.000000 Synthetic Data Sample: age income education employed 0 94 78302 Bachelor Yes 1 31 174108 Bachelor No … Synthetic Data Info: age income count 1000.000000 1000.000000 mean 70.618000 117945.021000 std 18.906018 55754.598894 min 15.000000 -5471.000000 25% 57.000000 73448.000000 50% 74.000000 112547.500000 75% 86.000000 163881.250000 max 102.000000 241895.000000
In this example:
- We import the necessary libraries.
- Load your real data into a pandas DataFrame.
- Initialize the CTGAN model.
- Fit the model to your data, specifying which columns are discrete.
- Generate synthetic samples using the trained model.
CTGAN is particularly useful when you need to generate synthetic data that maintains complex relationships and distributions present in your original dataset. It’s more advanced than simple random sampling methods like those used in Faker.
Some key features of CTGAN include:
- Handling both numerical and categorical columns
- Preserving column correlations
- Dealing with multi-modal distributions
- Conditional sampling based on specific column values
Other Notable Tools
- SDV (Synthetic Data Vault): A Python library for generating multi-table relational synthetic data.
- Gretel.ai: A platform offering various synthetic data generation techniques, including differential privacy.

Images Data Generation
While it’s true that Faker, SDV, and CTGAN don’t natively support image and voice data generation, there are indeed open-source tools available for these purposes. These tools represent the closest technology to AI in this field and can currently serve as fully-fledged AI data generators. However, they’re typically more specialized and often require more setup and expertise to use effectively. Here’s a brief overview:
For image generation:
- StyleGAN: An advanced GAN architecture, particularly good for high-quality face images.
- DALL-E mini (now called Craiyon): An open-source version inspired by OpenAI’s DALL-E, for generating images from text descriptions.
- Stable Diffusion: A recent breakthrough in text-to-image generation, with open-source implementations available.
For voice data generation:
- TTS (Text-to-Speech) libraries like Mozilla TTS or Coqui TTS: These can generate synthetic voice data from text input.
- WaveNet: Originally developed by DeepMind, now has open-source implementations for generating realistic speech.
- Tacotron 2: Another popular model for generating human-like speech, with open-source versions available.
These tools are indeed “ready to use” in the sense that they’re openly available, but they often require:
- More technical setup (e.g., GPU resources, specific dependencies)
- Understanding of deep learning concepts
- Potentially, fine-tuning on domain-specific data
This contrasts with tools like Faker, which are more plug-and-play for simpler data types. The complexity of image and voice data necessitates more sophisticated models, which in turn require more expertise to implement effectively.
Best Practices for Using AI Data Generators
- Validate the synthetic data: Ensure it maintains the statistical properties and relationships of the original data.
- Use domain expertise: Incorporate domain knowledge to generate realistic and meaningful synthetic data.
- Combine with real data: When possible, use synthetic data to augment real datasets rather than completely replace them.
- Consider privacy implications: Even with synthetic data, be cautious about potential privacy leaks, especially in sensitive domains.
- Regularly update models: As real-world data changes, update your generative models to ensure the synthetic data remains relevant.
The Future of AI Data Generation
As AI technology continues to advance, we can expect even more sophisticated and versatile data generation capabilities. Some emerging trends include:
- Improved realism in generated data across all domains
- Enhanced privacy-preserving techniques integrated into generation processes
- More accessible tools for non-technical users to create custom synthetic datasets
- Increased use of synthetic data in regulatory compliance and testing scenarios
Conclusion
AI data generators are revolutionizing the way we create and work with data. From overcoming data scarcity to enhancing privacy and security, synthetic data offers numerous benefits across various industries. As the technology continues to evolve, it will play an increasingly crucial role in driving innovation, improving machine learning models, and enabling new possibilities in data-driven decision-making.
By leveraging tools like the Python Faker library and more advanced AI-based generators, organizations can create diverse, realistic datasets tailored to their specific needs. However, it’s crucial to approach synthetic data generation with care, ensuring that the generated data maintains the integrity and relevance required for its intended use.
As we look to the future, the potential of AI data generators is boundless, promising to unlock new frontiers in data science, machine learning, and beyond.
For those interested in exploring user-friendly and flexible tools for database security, including synthetic data capabilities, consider checking out DataSunrise. Our comprehensive suite of solutions offers robust protection and innovative features for modern data environments. Visit our website for an online demo and discover how our tools can enhance your data security strategy.
