
Leveraging Redshift Information Schema for Better Database Performance

Introduction
This article delves into the Redshift database schema, specifically focusing on its information schema implementation. We’ll explore how it compares to similar tools in other database systems, such as Microsoft SQL Server and PostgreSQL. By the end of this guide, you’ll have a solid understanding of how to leverage Redshift’s system tables to optimize your data management strategies.
What is an Information Schema in MS SQL Server?
Before we dive into Redshift’s specifics, let’s start with a familiar reference point: Microsoft SQL Server’s Information Schema.
Understanding the Basics
In MS SQL Server, the Information Schema is a set of views that provide metadata about the objects in a database. It’s a standardized way to access information about tables, columns, views, and other database objects.
For example, to view all tables in a database using MS SQL Server’s Information Schema, you might use a query like this:
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE';
This query would return a list of all base tables in the current database.
Redshift Database Schema: Information Tools
Now, let’s turn our attention to Redshift, an Amazon Web Services petabyte-scale data warehouse. While Redshift is based on PostgreSQL, it has its own set of system tables and views that serve a similar purpose to the Information Schema in other database systems.
System Tables in Redshift
Redshift provides a set of system tables that store metadata about the cloud data, its tables, and other objects. These system tables are prefixed with “PG_” and “STL_”, “STV_”, or “SVV_”.
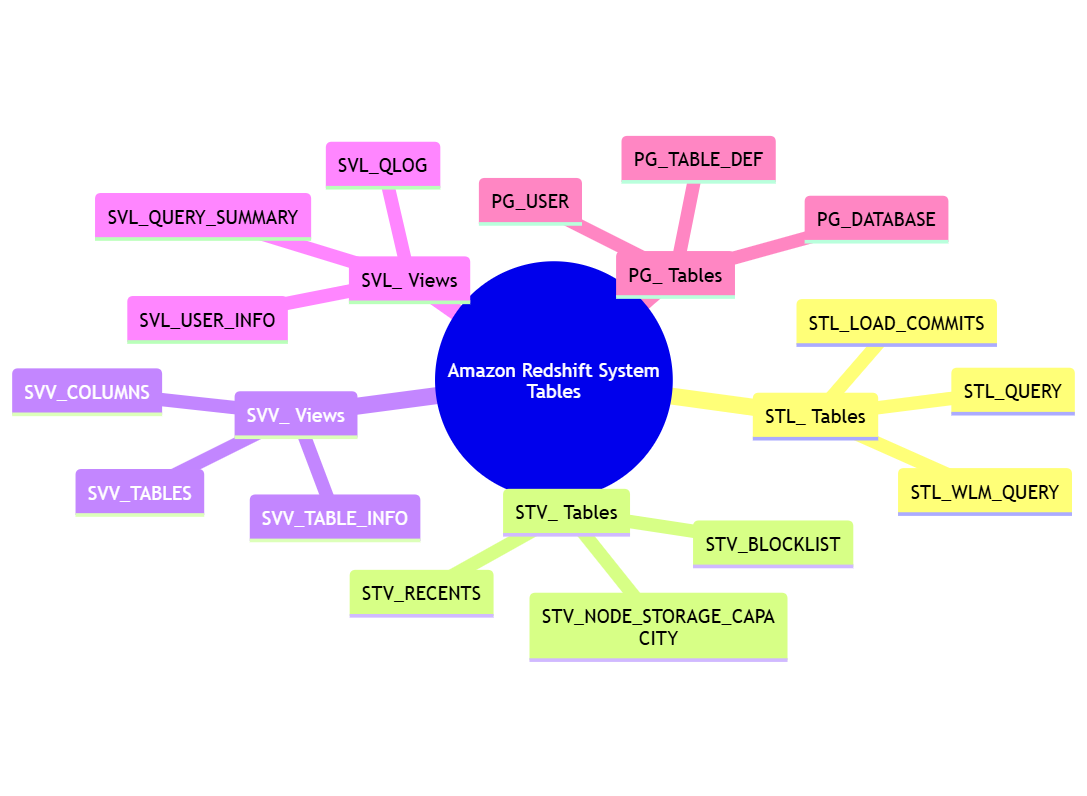
Here are some key system tables in Redshift:
- PG_TABLE_DEF: Contains information about table definitions.
- SVV_COLUMNS: Provides a view of all columns in the database.
- SVV_TABLES: Offers a view of all tables in the database.
Let’s look at an example of how to use these tables:
SELECT tablename, "column", type, encoding FROM pg_table_def WHERE schemaname = 'public';
This query will return information about all columns in tables within the ‘public’ schema, including their names, data types, and encoding.
Redshift Database Schema Queries
To get a comprehensive view of your Redshift database schema, you can use queries that combine information from multiple system tables. Here’s an example:
SELECT
n.nspname AS schema_name,
c.relname AS table_name,
a.attname AS column_name,
t.typname AS data_type
FROM
pg_catalog.pg_class c
JOIN
pg_catalog.pg_namespace n ON n.oid = c.relnamespace
JOIN
pg_catalog.pg_attribute a ON a.attrelid = c.oid
JOIN
pg_catalog.pg_type t ON t.oid = a.atttypid
WHERE
c.relkind = 'r' -- Only regular tables
AND n.nspname NOT IN ('pg_catalog', 'information_schema')
AND a.attnum > 0 -- Exclude system columns
ORDER BY
schema_name, table_name, a.attnum;
This query provides a detailed view of your Redshift database schema, including schema names, table names, column names, and data types.
Comparing Redshift and PostgreSQL Information Tools
Given that Redshift is based on PostgreSQL, it’s natural to wonder about the similarities and differences in their information schema tools.
PostgreSQL Information Schema
PostgreSQL, like MS SQL Server, has an INFORMATION_SCHEMA that complies with the SQL standard. It provides views that offer information about all database objects.
For example, to list all tables in PostgreSQL, you might use:
SELECT table_name FROM information_schema.tables WHERE table_schema = 'public';
Redshift vs PostgreSQL
While Redshift is based on PostgreSQL, it doesn’t include the standard INFORMATION_SCHEMA. Instead, it provides its own system tables and views. This is due to Redshift’s specialized nature as a columnar data warehouse, which requires different optimization and management tools.
However, many of the concepts are similar. For instance, where PostgreSQL has information_schema.tables, Redshift has SVV_TABLES. Both provide metadata about tables in the database, but the specifics of what information is available and how it’s accessed may differ.
Leveraging Redshift’s System Tables for Performance Optimization
Understanding Redshift’s system tables can help you optimize your database performance. Let’s explore some practical applications.
Identifying Table Skew
Table skew occurs when data is unevenly distributed across slices in Redshift. This can lead to performance issues. You can use system tables to identify skew:
SELECT
trim(name) AS table,
slice,
count(*) AS num_values,
cast(100 * ratio_to_report(count(*)) over () AS decimal(5,2)) AS pct_of_total
FROM svv_diskusage
WHERE name IN ('your_table_name')
GROUP BY name, slice
ORDER BY name, slice;
This query shows the distribution of data across slices for a specific table, helping you identify potential skew issues.
Monitoring Query Performance
Redshift’s STL_QUERY and SVL_QUERY_SUMMARY tables can help you monitor query performance:
SELECT q.query, q.starttime, q.endtime, q.elapsed/1000000 AS elapsed_seconds, s.segment, s.step, s.maxtime/1000000 AS step_seconds, s.rows, s.bytes FROM stl_query q JOIN svl_query_summary s ON q.query = s.query WHERE q.starttime >= DATEADD(hour, -1, GETDATE()) ORDER BY q.query, s.segment, s.step;
This query provides detailed information about queries run in the last hour, including their execution time and resource usage.
Best Practices for Using Redshift’s Information Schema
To make the most of Redshift’s system tables and views, consider the following best practices:
- Regularly monitor table statistics using SVV_TABLE_INFO to ensure your tables are optimized.
- Use STL_ALERT_EVENT_LOG to identify and address performance issues proactively.
- Leverage SVV_VACUUM_PROGRESS to monitor and manage VACUUM operations.
- Utilize SVV_DATASHARE_OBJECTS to manage data sharing across Redshift clusters.
Remember, while these system tables provide valuable insights, querying them frequently can impact performance. Use them judiciously and consider caching results where appropriate.
Conclusion
Understanding and effectively using Redshift’s information schema tools is crucial for managing and optimizing your data warehouse. While it differs from the standard INFORMATION_SCHEMA found in SQL Server and PostgreSQL, Redshift’s system tables and views offer powerful capabilities for monitoring, troubleshooting, and optimizing your database.
By leveraging these tools, you can gain deep insights into your Redshift database schema, monitor performance, and make informed decisions about data management and query optimization. As with any powerful tool, use these capabilities wisely to balance insight gathering with overall system performance.
For those seeking advanced database security and compliance tools, consider exploring DataSunrise. Our user-friendly and flexible solutions offer comprehensive database protection. Visit our website for an online demo and discover how you can enhance your database security today.
