
Amazon S3 Sensitive Data Discovery New Capabilities by DataSunrise
Introduction
According to a recent survey, more than 50% of companies host a huge amount of sensitive data in cloud storage, like S3 from Amazon.
DataSunrise Sensitive Data Discovery is available for fast data search, classification, and management. Searching and analyzing data in your data storages ensures you to pinpoint sensitive data in Amazon S3 in time, quickly, and effortlessly. We have upgraded our tool. Before we could discover semi-structured and unstructured data in S3 due to NLP feature, and now we can even more.
DataSunrise Sensitive Data Discovery
Data Discovery for Amazon S3 has new capabilities for the detection and protection of sensitive data. Now Data Discovery is available for:
- Apache Parquet file format;
- Semi-structured files like XML, JSON, CSV;
- Unstructured text formats like Microsoft Word documents;
- Images.
Data Discovery for S3 analyzes not only objects but also their names and paths to them. DataSunrise connects semantic relations with the context of the object for full and comprehensive sensitive data discovery. So you do not need to bother yourself with the specific names of objects that contain sensitive and private information.
Predefined and custom templates for PII. DataSunrise has a lot of predefined templates for sensitive data search like credit card numbers, passport, driving license. For a more flexible search, you can leverage custom information types (might be set up using regular expressions, Lua script, etc.). Thanks to these filters you will have an exhaustive picture of gathered sensitive data. The fine-tuning of the discovery will save your time and other resources. The most important thing is that you will be sure that there is no sensitive data that is not under your control and may lead to data exposure.
On-demand Data Discovery. You can create and run Data Discovery not only manually through the Web Console. Use the system terminal with the Command Line Interface to create automated systems that respond to security events without manual intervention.
Sensitive Data Discovery in images. Companies that store sensitive data in images (driver license, SSN, etc.) will be glad to use DataSunrise Data Discovery with Optical-Character Recognition. The usage of Image discovery enables you to search for sensitive data in images due to the OCR engine. It takes text from the images, then analyzes this information and finds private data from documents. Our Image Data Discovery supports the following file formats: JPG, PNG, GIF, TIFF, PSD.
Compressed and archived files Data Discovery. Together with the objects and different file formats, Data Discovery for S3 can also search sensitive data in compressed and archived formats. Compressed files let you reduce the used space thereby saving the cost. Archived files let you collect and group files in one place combining them. No matter the size of the archive, sensitive data will be discovered.
Sensitive Data Discovery Performance
Sensitive Data Discovery works on different levels in S3. First, you can discover your S3 buckets and objects for sensitive information. It is the simplest way of finding private information that should be protected. But when you have a lot of S3 buckets and objects in them this task will be time-consuming and tiring. With DataSunrise you will be able to save your time, budget, and other resources as far as now DataSunrise supports several techniques to increase performance.
AWS S3 Inventory. It keeps all metadata about your S3 buckets in one place in the form of an archived CSV file. To reduce traffic consumption and operation cost, DataSunrise can get this metadata using S3 Inventory without AWS API calls.
Incremental Data Discovery. With Incremental Data Discovery, there is no need for repetitive discovery of the same objects and buckets for the presence of sensitive data. Incremental scanning mode skips buckets and objects discovered earlier. It scans only new or updated objects, comparing them with the last scanned time. It helps you to save time and money while performing on big volumes of data. Moreover, incremental scanning is optional, so you can disable it any time you need.
Parallel Data Discovery. For the fast search of sensitive data in big data volumes, you can use implemented multiprocessing. It enables the use of multiple DataSunrise servers for parallel data discovery. With parallel discovery, you will be able to optimize the CPU and memory utilization. Multiprocessing usage simplifies the work of data discovery when you need to process a huge amount of data. Also, it reduces the load on the server and does not impact the parallel processes you have. With multiprocessing, you can choose multiple search attributes and exclude specific objects from the scan.
Random Data Discovery. It enables scanning random files in S3 buckets to speed up the Data Discovery process. It is possible to choose the percentage of sensitive data to be discovered across large volumes of data.
Dividing big files into pieces. Big objects consume additional space making in-memory calculations. Now we can divide any object into pieces to increase performance and optimize memory usage. With additional parameters like “DataDiscoveryChunkSize” and others, we can easily discover these pieces and find any sensitive information.
Sensitive Data Discovery Settings and Customizing
You can fine-tune the discovery process by adjusting some additional parameters.
DataSunrise has over 25 customizable parameters. For example:
- “DataDiscoveryMatchesSaveStrategy” allows save Data Discovery occurrences in the Dictionary depending on your particular needs: save first matches, all matches, or unique matches;
- “DataDiscoveryChunkSize” allows partial downloading of the files for Data Discovery to avoid the overflowing of the memory. You can set the chunk size and chunk sum limit;
- “DataDiscoveryMaxFileSizeForChunkProcessing” is for the entire file size to scan as a SUM of chunks. Chunk processing scans until this parameter’s value is reached;
- “DataDiscoveryS3FilePartToRead” is for maximum file size (Mb) for S3 Data Discovery. This parameter works in conjunction with DataDiscoveryFilesThreadPools. It defines the number of threads used for file processing. Each thread processed one file at a time. So, this parameter’s value depends on available system resources.
- “DataDiscoveryBatchSplitFactor” identifies in how many parts the failed batch will be split for the further rerun of the data discovery task.
Sensitive Data Discovery Reporting
DataSunrise provides multi-layered protection for AWS S3. As a result, DataSunrise operates on a huge amount of data. It enables you to get all the most detailed information about your databases and the data in them by creating custom reports in CSV or PDF format.
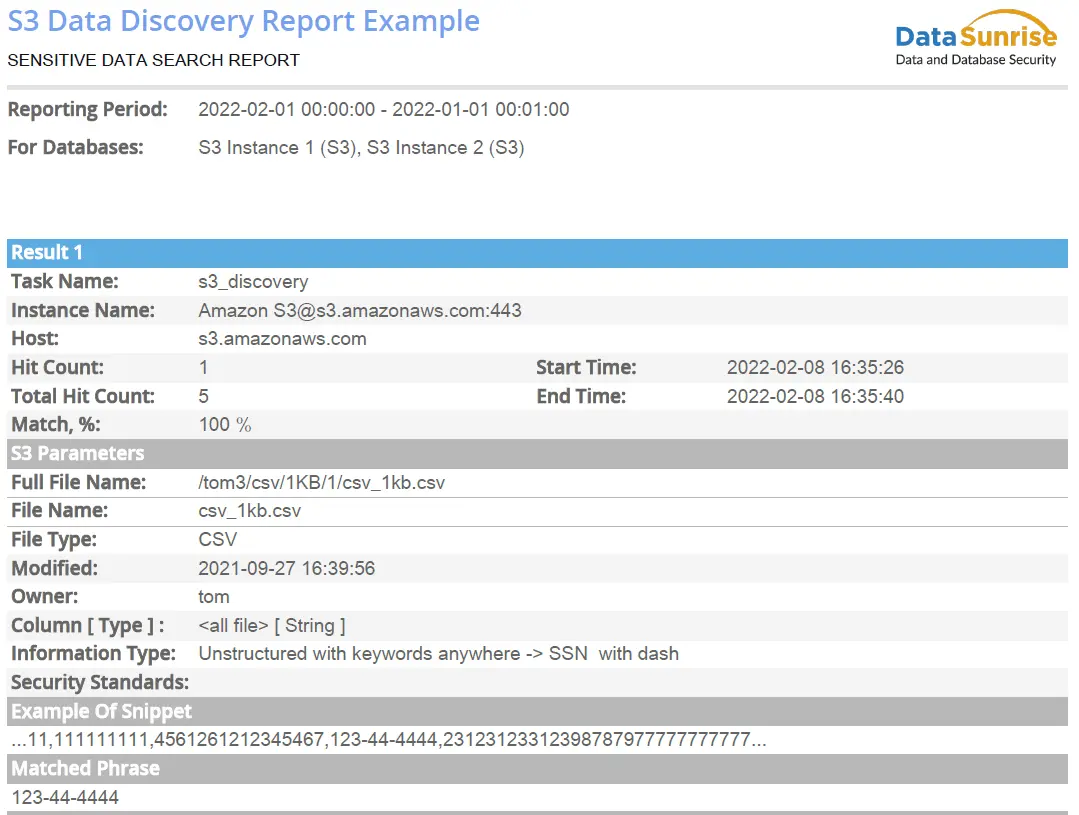
Image 1: Sensitive Data Discovery PDF Report Example
Availability of reports. Now report generation is possible during the Discovery task process, there is no need to wait for the task to complete. It allows you to view intermediate results and use them for analytics.
Usage of reports. Through the results of reports, you can collect analytics and get statistics on data processing speed and attributes and use the received data for specific purposes, including learning your own AI.
With a flexible system of customizable reports, you no longer need to manually monitor information about the protection levels of your databases.
Conclusion
Sensitive Data Discovery enables you to know where sensitive data resides in your AWS S3 buckets and leverage data protection means respectively.
DataSunrise provides a large variety of formats and ways of discovering sensitive data in AWS S3 wherever it resides. With the enhanced performance, Data Discovery will become less time-consuming. You can fine-tune DataSunrise Sensitive Data Discovery to avoid unnecessary repeated searching among big data volumes. Editable search patterns enable you to perform a search for any specific piece of data. With reporting you can get the most detailed information that will let you see intermediate results for analytics, AI learning, and other business processes.
To get started with DataSunrise with Amazon, visit DataSunrise in AWS Marketplace.
