Data Anonymization in Vertica
Data anonymization in Vertica is a critical capability for organizations that rely on large-scale analytics while processing personal, financial, or regulated information. Vertica is designed for high-performance analytical workloads, which makes it ideal for BI reporting, customer analytics, and data science. At the same time, this analytical flexibility increases the risk that sensitive values may appear in query results, exports, or downstream systems if they are not properly protected.
In modern Vertica environments, multiple teams and tools often access the same datasets. Analysts explore data interactively, BI dashboards run scheduled queries, and machine learning pipelines extract large training datasets. Because these workloads operate on shared tables, organizations must ensure that sensitive attributes remain protected without breaking analytical workflows or duplicating data.
This article explains how data anonymization can be implemented in Vertica using centralized enforcement, dynamic anonymization techniques, and continuous auditing, with DataSunrise Data Compliance acting as the protection layer.
Why Data Anonymization Is Necessary in Vertica
Vertica’s architecture prioritizes analytical performance. Data is stored in columnar ROS containers, recent updates reside in WOS, and projections create multiple optimized physical layouts of the same logical tables. While this design accelerates queries, it also complicates fine-grained data protection.
In practice, several factors increase the need for anonymization:
- Wide analytical tables often combine metrics with PII or payment data.
- Projections replicate sensitive columns across multiple nodes.
- Shared clusters support BI tools, ETL jobs, notebooks, and ML pipelines.
- Ad-hoc SQL queries bypass curated reporting layers.
- Native RBAC controls access but not value-level visibility.
As soon as a user has SELECT access, Vertica returns all selected values in clear form. Consequently, organizations require anonymization mechanisms that operate at query time rather than relying solely on static permissions.
For additional context, see the official Vertica architecture documentation.
Centralized Anonymization Architecture for Vertica
A proven approach to data anonymization in Vertica is to separate enforcement from storage. In this model, client applications connect through a centralized gateway instead of connecting directly to Vertica. Every SQL query is inspected, anonymization rules are evaluated, and sensitive values are transformed before results are returned.
Many organizations implement this architecture using DataSunrise as a transparent proxy. Because enforcement happens outside Vertica, schemas, projections, and application logic remain unchanged.
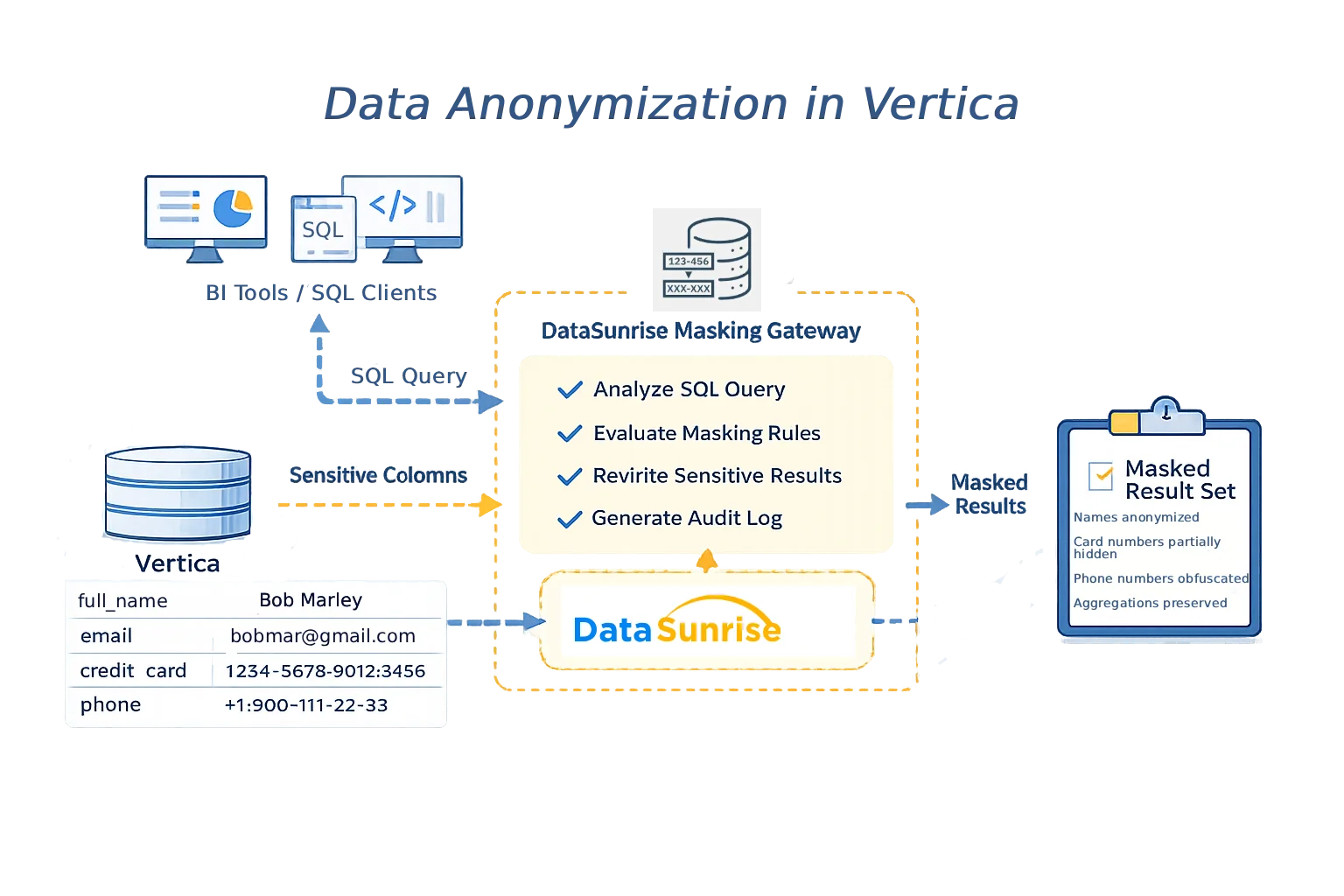
Centralized data anonymization architecture for Vertica with DataSunrise as an enforcement layer.
This architecture ensures that anonymization policies apply uniformly across all access paths, including SQL clients, BI tools, and automated pipelines.
Dynamic Anonymization as the Core Technique
Dynamic anonymization is the most effective technique for protecting sensitive data in Vertica analytics. Instead of permanently modifying stored values, anonymization occurs at query time. When a query references sensitive columns, the returned values are replaced with anonymized representations.
DataSunrise provides built-in dynamic data masking and anonymization mechanisms that evaluate each query against policy rules. These rules can consider:
- Database user or role
- Client application type
- Environment (production, staging, analytics)
- Sensitivity classification of each column
Because anonymization happens only in the result set, Vertica continues to process real values internally. As a result, aggregations, joins, filters, and calculations remain accurate.
Configuring Anonymization Rules in Vertica
To apply anonymization, administrators define a rule that targets a Vertica instance and specifies which columns require protection. Rules typically reference schemas or tables identified through automated discovery.
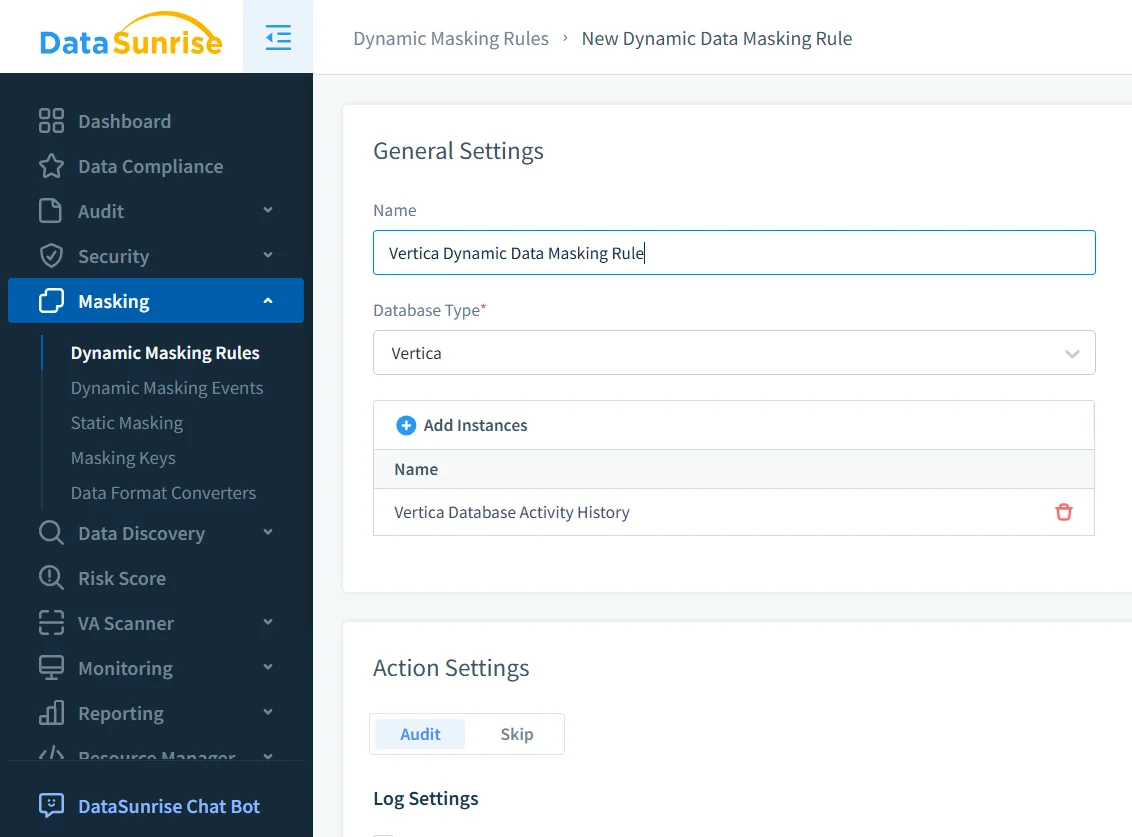
Anonymization rule configuration for a Vertica database instance.
At this stage, administrators enable auditing for anonymization events and define how sensitive values should be transformed. Formats may include full anonymization, partial masking, or tokenization depending on policy requirements.
Before creating anonymization rules, run Sensitive Data Discovery. Discovery-driven policies ensure new sensitive columns automatically inherit anonymization as schemas evolve.
Anonymized Results in Analytical Queries
From the user’s perspective, anonymization is transparent. Queries use standard SQL, and Vertica executes them normally. However, sensitive values appear anonymized in the returned results.
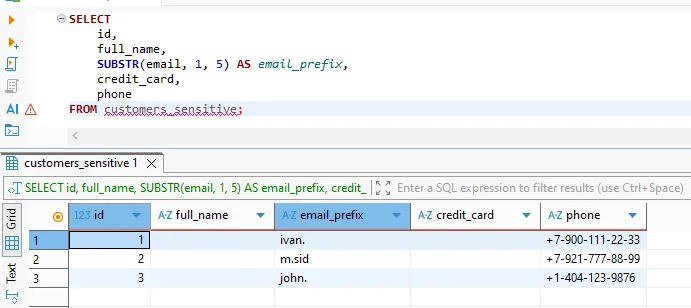
Anonymized result set returned to the client while preserving analytical structure.
This behavior allows analysts to work with realistic datasets while preventing exposure of real identities. At the same time, machine learning pipelines can consume anonymized training data without leaking personal information.
Auditing and Visibility for Anonymized Access
Anonymization must remain auditable to support compliance. Organizations need to demonstrate when anonymization occurred, which rules were applied, and who accessed the data.
DataSunrise automatically records audit events for every anonymized query. These records integrate with Database Activity Monitoring and can be exported to SIEM systems.
Centralized auditing simplifies compliance with regulations such as GDPR, HIPAA, and SOX, while also supporting internal investigations.
Comparing Anonymization Approaches in Vertica
| Approach | Description | Suitability for Vertica |
|---|---|---|
| Static anonymization | Create permanently anonymized datasets | High maintenance, limited flexibility |
| SQL views | Anonymize data using predefined views | Easily bypassed by direct queries |
| Application-layer logic | Anonymization inside BI or apps | Inconsistent coverage |
| Dynamic anonymization | Anonymize results at query time | Centralized and scalable |
Best Practices for Data Anonymization in Vertica
- Begin with automated discovery to identify sensitive fields.
- Apply anonymization at the query layer instead of copying data.
- Test policies using real BI and analytics workloads.
- Review audit logs regularly for unexpected access patterns.
- Align anonymization with broader data security strategies.
Conclusion
Data anonymization in Vertica provides a scalable and analytics-friendly way to protect sensitive information. By anonymizing values dynamically at query time, organizations reduce exposure risks while preserving the power and flexibility of Vertica.
With DataSunrise acting as a centralized enforcement layer, teams gain consistent protection, full audit visibility, and regulatory alignment across dashboards, scripts, and machine learning pipelines—without sacrificing performance.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now