How to Apply Static Masking in ScyllaDB
ScyllaDB powers high-throughput NoSQL workloads where performance and scalability are non-negotiable. However, development, analytics, QA, and external partner environments rarely need access to real production data. In fact, exposing raw personally identifiable information (PII), financial records, or health data outside production significantly increases regulatory and breach risks. According to the IBM Cost of a Data Breach Report, data exposure continues to generate multi-million-dollar impacts across industries, reinforcing the need for preventive controls rather than reactive remediation. Additionally, privacy frameworks such as the General Data Protection Regulation (GDPR) explicitly require minimizing unnecessary exposure of personal data.
Static masking in ScyllaDB allows organizations to permanently transform sensitive data before it is copied to non-production environments. Instead of restricting access to live systems, static masking creates a sanitized dataset where confidential values are irreversibly replaced while preserving structural integrity and application behavior. This approach aligns with established data masking principles and strengthens broader data security strategies across distributed NoSQL environments.
This guide explains how static masking can be implemented in ScyllaDB, outlines native limitations, and demonstrates how DataSunrise enables Zero-Touch Data Masking with Autonomous Compliance Orchestration across distributed NoSQL clusters.
What is Static Masking?
Static masking is a data protection technique that permanently transforms sensitive values stored in a database. Instead of hiding data at query time, it rewrites the actual stored content so that confidential information cannot be reconstructed.
In practical terms, static masking replaces real production data with realistic but fictional substitutes. The resulting dataset keeps the same schema, formats, and referential logic, but the original values are gone for good.
For example:
- Real email → randomized but valid email format
- Real credit card → structurally correct but non-functional number
- Real full name → consistent pseudonym
Unlike dynamic data masking, which applies masking rules during query execution, static masking modifies the dataset before it is copied to development, analytics, or QA environments.
This method is especially useful when:
- Providing data to external vendors
- Creating staging or testing environments
- Supporting analytics teams
- Sharing datasets across distributed clusters
From a compliance perspective, static masking helps enforce the principle of data minimization required by frameworks such as GDPR and PCI DSS. It reduces the attack surface by ensuring sensitive information never leaves the secure production boundary in usable form.
In short, static masking removes risk at the source rather than attempting to control exposure afterward.
Native Approaches to Static Masking in ScyllaDB
ScyllaDB does not provide built-in static masking functionality. As a result, organizations often attempt to implement masking manually or through external transformation workflows. While technically possible, these approaches introduce operational and compliance risks that become more visible at scale.
1. Manual UPDATE-Based Masking
One of the simplest methods is directly overwriting sensitive columns using UPDATE statements. For example:
UPDATE customers
SET email = 'masked_' + email,
credit_card = 'XXXX-XXXX-XXXX-0000';
At first glance, this seems straightforward. However, the simplicity is deceptive.
There is no centralized rule control, meaning every masking operation depends on manually written SQL. Consistency validation is also absent, so related tables may not remain synchronized. In distributed environments, partial masking becomes a real risk if operations fail mid-process or are applied unevenly across nodes.
Most importantly, there is no structured audit evidence proving that masking was executed properly. From a regulatory perspective, that gap alone can become a serious issue.
2. Export–Transform–Import Workflow
Another commonly used approach follows an external transformation pipeline.
First, data is exported from ScyllaDB using tools such as COPY TO or custom extraction scripts. For example:
-- Export table to CSV
COPY customers TO '/tmp/customers.csv' WITH HEADER = TRUE;
Next, the dataset is transformed outside the database using scripts, ETL tools, or data processing frameworks. A simple example in Python might look like this:
import csv
import uuid
def mask_email(email):
return f"user_{uuid.uuid4().hex[:8]}@example.com"
def mask_credit_card(card):
return "XXXX-XXXX-XXXX-0000"
with open("customers.csv", "r") as infile, open("customers_masked.csv", "w", newline="") as outfile:
reader = csv.DictReader(infile)
writer = csv.DictWriter(outfile, fieldnames=reader.fieldnames)
writer.writeheader()
for row in reader:
row["email"] = mask_email(row["email"])
row["credit_card"] = mask_credit_card(row["credit_card"])
writer.writerow(row)
Finally, the masked dataset is re-imported into a staging or testing environment:
-- Import masked dataset
COPY customers FROM '/tmp/customers_masked.csv' WITH HEADER = TRUE;
Although this method separates production from transformation, it introduces significant operational overhead. Data duplication increases storage usage and expands the attack surface. During export, the original dataset temporarily exists outside the database boundary, which itself may create additional security exposure.
Manual rule maintenance becomes unavoidable, especially when schemas evolve. If a new sensitive column is added, transformation scripts must be updated immediately — otherwise, unmasked data may slip through.
More critically, this workflow does not provide automated compliance alignment. There is no built-in validation that masking policies meet the requirements of regulations such as GDPR, HIPAA, or PCI DSS.
From a compliance standpoint, both native approaches lack traceability, structured enforcement, and centralized governance. Static masking in enterprise environments must be controlled, repeatable, and auditable — not dependent on manual scripts and fragmented workflows.
Applying Static Masking in ScyllaDB with DataSunrise
While native approaches rely on scripts and fragmented ETL pipelines, DataSunrise delivers enterprise-grade Static Masking through Autonomous Compliance Orchestration. The platform introduces Zero-Touch Data Masking with centralized governance, removing the operational risks associated with manual transformation across distributed ScyllaDB clusters.
Unlike ad-hoc SQL updates, DataSunrise provides centralized policy management, automatic policy generation, context-aware protection, and continuous regulatory calibration. These capabilities turn static masking from a technical workaround into a structured compliance mechanism.
The platform operates in non-intrusive modes such as proxy-mode or traffic monitoring, meaning ScyllaDB internals remain untouched. Architecture flexibility allows integration into production environments without schema modification or engine-level adjustments. Detailed options are available in the Deployment Modes of DataSunrise documentation.
Step 1: Connect ScyllaDB to DataSunrise
After deployment, the first step is connecting your ScyllaDB cluster by specifying the node IP address, port, and authentication credentials. This integration does not require modifying database schemas or altering existing application logic.
Once connected, DataSunrise establishes secure monitoring and transformation control across all cluster nodes. Governance becomes unified under a Centralized Data Compliance Platform, ensuring policies are enforced consistently in distributed environments.
Rather than relying on isolated masking scripts tied to specific exports or environments, the connection forms a persistent compliance control layer.
Step 2: Run Sensitive Data Discovery
Before static masking is applied, sensitive data must be identified accurately. Manual identification is unreliable and often incomplete, especially in evolving schemas.
DataSunrise performs automated discovery through Auto-Discover & Mask scanning, NLP-based sensitive data detection, and inspection of structured and semi-structured data formats. This discovery extends across SQL, NoSQL, and hybrid infrastructures.
The Data Discovery module continuously evaluates schema changes and newly added columns. As a result, compliance gaps caused by overlooked fields are minimized, and masking policies remain aligned with real data exposure risks.
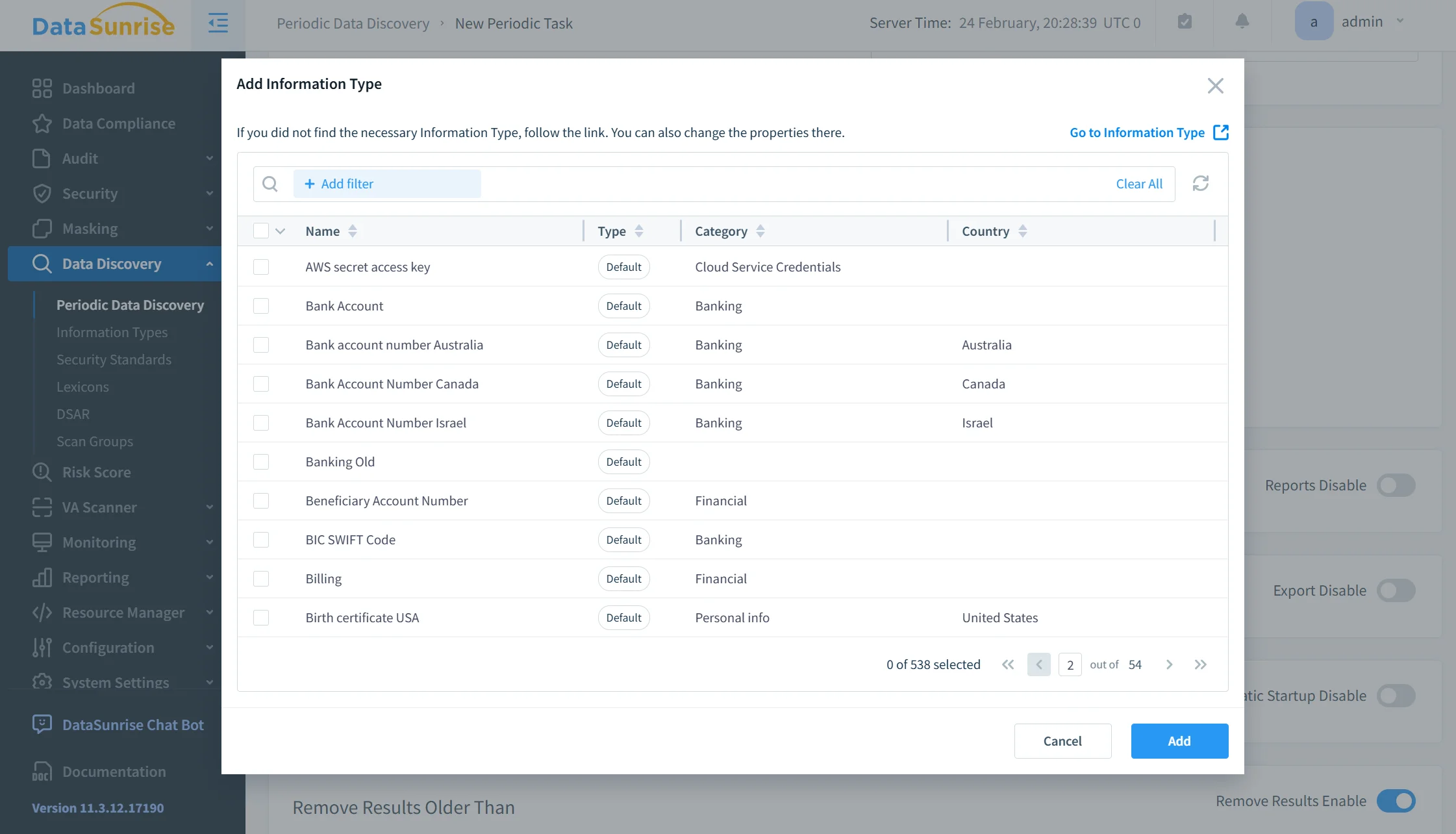
Step 3: Configure Static Masking Rules
After discovery, static masking rules are defined through a centralized interface. Administrators select the ScyllaDB table, identify sensitive columns such as email, phone, or credit card numbers, and assign appropriate masking logic.
Masking methods may include substitution, shuffling, randomized generation, or partial redaction, following the principles described in Static Data Masking.
Rules can be configured with fine-grained precision to preserve referential consistency across distributed partitions. Unlike fragmented scripts embedded in ETL pipelines, policies remain reusable, version-controlled, and centrally governed.
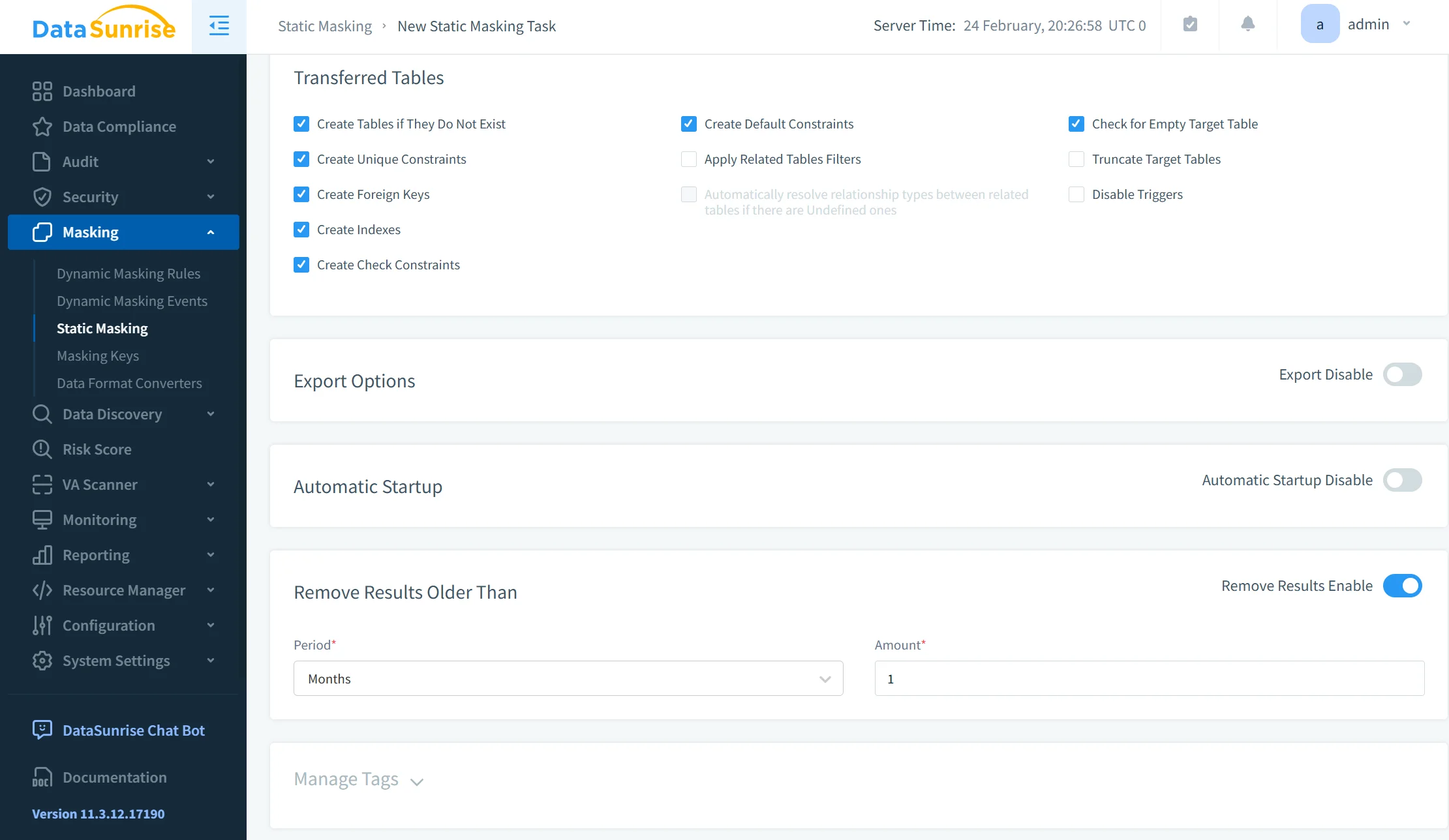
Step 4: Execute Masking Job
Once rules are defined, DataSunrise executes the masking process. Depending on configuration, the system can perform in-place transformation or generate a sanitized dataset copy for non-production use. Masking tasks can be scheduled or integrated into CI/CD workflows.
The execution process guarantees consistent transformation across cluster nodes, preserves referential integrity, and logs all changes for audit traceability. This structured approach replaces manual export–transform–import workflows with a controlled, repeatable, and verifiable process.
Compared to script-based methods, the reduction in manual effort is significant, while time-to-compliance is accelerated through centralized automation and governance.
Business Impact of Static Masking in ScyllaDB
Organizations implementing Autonomous Static Masking with DataSunrise achieve measurable and operationally meaningful outcomes across security, compliance, and cost control.
| Business Outcome | Impact on ScyllaDB Environments |
|---|---|
| Quantifiable Risk Reduction | Sensitive data never leaves production in usable form, significantly strengthening overall data security and reducing breach exposure in development, QA, and analytics environments. |
| Streamlined Compliance Workflows | Automated rule enforcement supports regulatory frameworks such as GDPR, HIPAA, and PCI DSS while integrating with centralized Compliance Manager capabilities. |
| Significant Reduction in Manual Effort | Eliminates script maintenance, repetitive exports, and fragmented ETL pipelines by replacing them with governed static data masking policies. |
| Optimized Total Cost of Compliance | Reduces audit preparation time, minimizes remediation costs, and accelerates regulatory reporting through structured automation. |
| Scalable for Growth | Flexible architecture supports distributed ScyllaDB clusters of any size, aligning with evolving compliance and security requirements. |
Unlike solutions that require constant tuning and reactive adjustments, DataSunrise delivers Continuous Compliance Alignment across distributed NoSQL infrastructures, ensuring static masking remains consistent as schemas, workloads, and regulatory obligations evolve.
Conclusion
ScyllaDB offers high-performance distributed data processing. However, it does not provide native static masking capabilities for secure non-production data handling.
Manual SQL transformations introduce operational risk, inconsistency, and compliance gaps, especially in distributed NoSQL clusters where centralized control is essential for sustained database security.
DataSunrise delivers Zero-Touch Data Masking, Compliance Autopilot, and Enterprise-Grade Policy Enforcement for ScyllaDB in on-premise, cloud, and hybrid environments. Through governed static data masking and automated regulatory alignment, organizations gain structured protection instead of relying on fragile scripts.
By combining Autonomous Compliance Orchestration with centralized governance under a Data Compliance Platform, organizations eliminate sensitive data exposure at the source while accelerating time-to-compliance and reducing long-term compliance overhead.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now