
Static Data Masking in Sybase
Static data masking in Sybase (SAP ASE) is used to protect sensitive information in non-production environments by permanently transforming data values. This approach is typically applied when creating database copies for development, testing, analytics, or external sharing.
Sybase provides robust access control and encryption mechanisms. However, it does not include native capabilities for systematic masking of data at rest. As a result, organizations must implement masking workflows manually or rely on external tools such as static data masking solutions and automated data discovery tools.
This limitation is also acknowledged in enterprise database security practices described in the NIST SP 800-53 security framework and SAP ASE documentation, where masking is treated as an external control rather than a native database feature.
This article explains how static data masking is implemented in Sybase using native techniques, outlines their limitations, and describes how centralized platforms improve consistency and compliance.
What is Static Data Masking
Static Data Masking is a process that replaces sensitive data with fictional, randomized, or obfuscated values in a database copy. The transformation is irreversible and applied directly to stored data, ensuring that the original sensitive values cannot be reconstructed from the masked dataset.
Unlike dynamic data masking, which modifies query results at runtime without changing the underlying data, static masking alters the dataset itself. This means that once the masking process is complete, the protected data is physically stored in its masked form. As a result, any exported, replicated, or shared version of the database contains only sanitized data.
Static masking is typically performed as part of data provisioning workflows, where production data is copied and prepared for secondary use. During this process, masking rules are applied consistently across tables to preserve referential integrity and maintain realistic data distributions.
Typical use cases include:
- Development and QA environments, where teams require realistic datasets without exposing sensitive information
- Data analytics and reporting systems that process large volumes of data outside production boundaries
- Third-party data sharing, including vendors, partners, or external auditors
- Training datasets for internal teams or machine learning models, where real data cannot be used safely
In practice, static data masking enables organizations to balance usability and security by providing functional datasets while eliminating the risk of sensitive data exposure.
Native Static Masking Techniques in Sybase
Sybase does not provide built-in masking functions. Instead, static masking is implemented using SQL operations and external processing workflows.
1. Direct Data Transformation
Sensitive values are replaced using SQL update statements:
-- Mask emails and phone numbers
UPDATE customers
SET
email = 'user_' + CAST(customer_id AS VARCHAR) + '@example.com',
phone = '0000000000';
-- Mask credit card numbers (preserve last 4 digits)
UPDATE payments
SET
credit_card = 'XXXX-XXXX-XXXX-' + RIGHT(credit_card, 4);
-- Mask names with deterministic pattern
UPDATE users
SET
first_name = 'User_' + CAST(user_id AS VARCHAR),
last_name = 'Masked';
-- Mask salary and sensitive numeric fields
UPDATE employees
SET
salary = salary * 0.1,
bonus = 0;
This approach modifies data in-place and is typically used on cloned databases.
2. Export and Transformation Pipelines
Data is exported, transformed externally, and reloaded into a target environment.
Example using BCP:
# Export table data
bcp mydb..customers out customers.dat -c -U user -P password -S server_name
# Example: transform with Python (pseudo-step)
python mask_data.py customers.dat masked_customers.dat
# Import masked data back
bcp mydb_masked..customers in masked_customers.dat -c -U user -P password -S server_name
Example transformation logic (conceptual):
# mask_data.py (simplified example)
import csv
with open('customers.dat', 'r') as infile, open('masked_customers.dat', 'w', newline='') as outfile:
reader = csv.reader(infile)
writer = csv.writer(outfile)
for row in reader:
row[1] = f"user_{row[0]}@example.com" # email masking
row[2] = "0000000000" # phone masking
writer.writerow(row)
After export, transformation scripts (e.g., Python or ETL tools) replace sensitive fields before importing the dataset back into Sybase.
3. Substitution-Based Dataset Generation
New datasets are generated using predefined or synthetic values:
-- Create masked copy of customers
INSERT INTO customers_masked (
customer_id,
name,
email
)
SELECT
customer_id,
'User_' + CAST(customer_id AS VARCHAR) AS name,
'masked_' + CAST(customer_id AS VARCHAR) + '@example.com' AS email
FROM customers;
-- Generate masked orders dataset with preserved relationships
INSERT INTO orders_masked (
order_id,
customer_id,
order_amount
)
SELECT
order_id,
customer_id,
ROUND(order_amount * 0.5, 2)
FROM orders;
-- Replace sensitive columns while keeping structure
INSERT INTO employees_masked (
emp_id,
first_name,
last_name,
salary
)
SELECT
emp_id,
'Emp_' + CAST(emp_id AS VARCHAR),
'Masked',
salary * 0.2
FROM employees;
This method avoids modifying the original dataset but requires additional storage and data synchronization logic.
Static Masking with DataSunrise
DataSunrise provides a centralized approach to static data masking for Sybase environments. It enables policy-driven masking workflows without requiring changes to database schemas, application queries, or existing business logic.
In practice, this means masking is no longer handled through isolated SQL scripts, ad hoc export procedures, or custom transformation utilities maintained by different teams. Instead, masking rules are managed from a single control layer and applied in a repeatable way across the selected dataset.
This model is particularly useful in Sybase environments where production data is regularly copied into development, QA, analytics, or partner-facing systems. In such cases, the main requirement is not just to hide a few values, but to produce a sanitized database copy that remains usable, structurally consistent, and operationally safe.
DataSunrise implements Zero-Touch Data Masking and No-Code Policy Automation, allowing organizations to define masking policies once and apply them consistently across structured datasets while reducing manual intervention. This approach also improves control over masking scope, execution order, and validation.
Unlike manual masking methods, which often break referential links or require repeated rewriting after schema changes, DataSunrise is designed to support controlled and repeatable masking workflows at scale.
Implementation Workflow
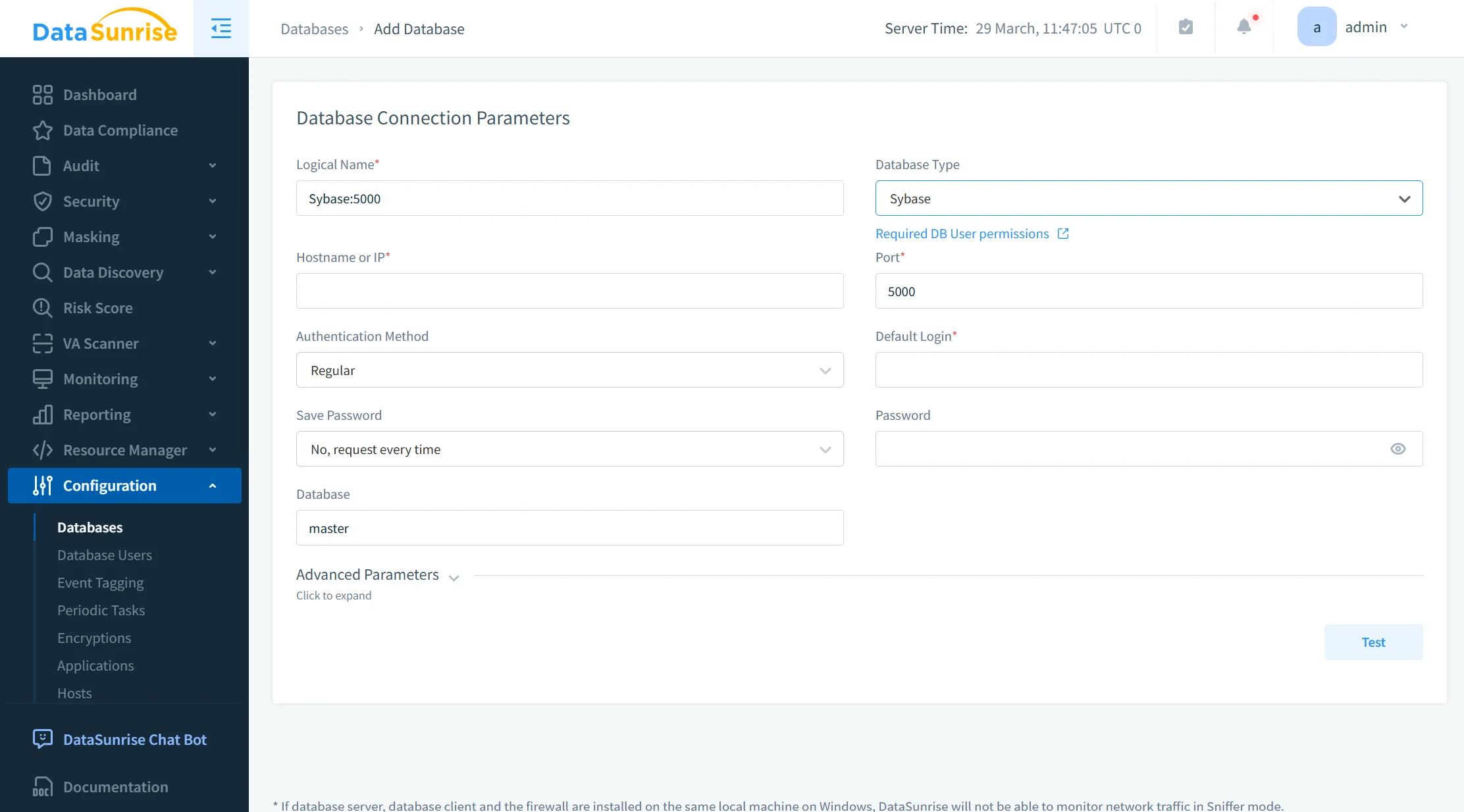
1. Database Connection
The first step is connecting the Sybase instance to DataSunrise. This integration can be performed using supported deployment modes such as proxy mode or sniffer mode, as described in deployment modes, depending on the architecture and monitoring requirements.
This is important because many organizations cannot afford intrusive changes to production systems. In Sybase environments, that usually means the masking platform must work without altering table structures, rewriting application code, or introducing changes into existing query paths.
Once the database instance is connected, DataSunrise can interact with the environment as a centralized control point for discovery, rule definition, and dataset preparation.
From a technical perspective, this stage establishes:
- access to the Sybase source environment
- visibility into schemas, tables, and columns
- a foundation for identifying which objects contain sensitive values
- a controlled path for applying masking policies to cloned or exported datasets
This architecture is more maintainable than distributing masking logic across shell scripts, SQL jobs, and ETL tools. It also reduces the number of places where masking failures can occur.
2. Sensitive Data Discovery
After connection, the next stage is data discovery. This phase identifies which database objects contain regulated or confidential information and therefore require masking.
In Sybase, the need for discovery is especially important because sensitive data is often spread across business tables without standardized naming conventions. Fields containing personal identifiers, credentials, or financial records may not always be obvious from schema design alone.
DataSunrise automates this step by scanning the database and identifying fields that match known categories of sensitive information, including:
- personally identifiable information (PII)
- financial records
- payment-related attributes
- authentication data
- internal identifiers that should not be exposed in non-production copies
This reduces the risk of partial masking, where obvious fields such as email or phone number are protected, but related identifiers remain untouched.
From an operational standpoint, automated discovery solves two recurring problems:
First, it reduces dependency on manual schema review.
Second, it makes masking preparation more complete and repeatable across large or changing environments.
In environments with frequent schema updates, this also reduces the chance that new sensitive columns appear in downstream copies without being included in the masking process.
3. Masking Policy Definition
Once sensitive fields have been identified, masking rules are defined centrally using data masking policies. This is the stage where security and data utility must be balanced carefully.
The goal is not simply to destroy data values. The goal is to produce a sanitized dataset that still behaves like the original from the perspective of applications, testers, analysts, and support teams.
DataSunrise allows masking policies to be defined once and then applied consistently across tables and related datasets. Supported approaches include:
- substitution
- tokenization
- format-preserving masking
Each technique serves a different purpose.
Substitution is useful when realistic but artificial values are needed, such as replacing real customer names with generated alternatives.
Tokenization is useful when a stable surrogate value is required instead of the original one, especially when the original value should never reappear in downstream environments.
Format-preserving masking is useful when the output must retain structural characteristics such as length, pattern, or data type. This is often necessary for application compatibility, validation routines, and integration testing.
The technical advantage here is consistency.
If the same source value appears across multiple records or related tables, masking rules can be applied in a coordinated way. That matters because non-production systems still need valid joins, usable reports, and coherent test scenarios.
Without centralized policy definition, teams often end up with one masking rule for exports, another for test refreshes, and a third for analytics datasets. That kind of fragmentation turns into operational debt very quickly.
4. Masked Dataset Generation
After discovery and rule configuration, DataSunrise generates the masked dataset.
This stage is where static masking becomes materially different from runtime protection. The result is not a filtered query response. It is a new sanitized data copy in which sensitive values have already been transformed before the dataset is delivered to downstream users or systems.
The masking process is designed to preserve:
- referential integrity
- schema structure
- data type compatibility
- usability for development, QA, analytics, and support workflows
Preserving referential integrity is one of the most critical technical requirements. If customer identifiers, account references, or transaction mappings become inconsistent during masking, the copied environment becomes unreliable. Applications may fail, test scenarios may produce false results, and analytical outputs may no longer reflect realistic patterns.
A controlled masking workflow avoids these problems by applying transformations consistently and systematically across the selected dataset.
In practical terms, masked dataset generation supports use cases such as:
- preparing development copies of production databases
- refreshing QA environments without exposing real personal data
- sharing datasets with contractors or vendors
- supporting analytics teams with non-sensitive but structurally accurate data
This also improves compliance posture because sensitive production values do not need to remain present in environments that do not require them.
Business Impact of Static Masking in Sybase
| Impact | Description |
|---|---|
| Reduced Data Exposure | Sensitive data is removed from non-production environments using static data masking, ensuring it never leaves production in usable form |
| Safer Testing | Dev and QA teams work with sanitized datasets aligned with data security best practices |
| Faster Compliance | Masking workflows support regulatory alignment with frameworks such as GDPR compliance and similar standards |
| Lower Operational Cost | Centralized policies reduce reliance on manual scripts and simplify data management processes |
| Audit Readiness | Masking activities are traceable through structured logging and audit trails |
Conclusion
Sybase provides mechanisms for access control and encryption but does not address data protection in replicated or exported datasets, which increases the need for solutions aligned with modern database security practices.
Native static masking approaches—SQL updates, export pipelines, and substitution methods—introduce complexity and are difficult to maintain at scale, especially without integration into broader data security frameworks.
A centralized masking strategy improves consistency, reduces operational overhead, and ensures compliance across environments, particularly when combined with data compliance regulations requirements.
DataSunrise enables this model by providing automated discovery, policy-driven masking, and controlled dataset generation. This approach ensures that sensitive data remains protected throughout the data lifecycle without requiring manual intervention or custom development.
