
Data Masking Approaches in AI & LLM Workflows

As artificial intelligence (AI) and large language models (LLMs) transform modern business workflows, protecting sensitive data has become more critical than ever. Data masking helps solve this challenge without slowing innovation. In this article, we explore practical data masking approaches in AI & LLM workflows, with a focus on real-time safeguards and compliance integration.
Why Data Masking Is Crucial in AI Workflows
Generative AI models often process sensitive inputs such as internal logs, emails, personal data, and financial records. These systems may store or reproduce this data unintentionally. Masking prevents these risks by hiding or modifying sensitive information before it reaches the model.
For instance, if a fine-tuned LLM prompt includes a real customer’s name and phone number, the model could memorize and reuse it. A masking layer prevents this by replacing identifiers before ingestion. OpenAI’s data usage policy explains how LLMs may retain user content unintentionally.
Static and Dynamic Masking in LLM Contexts
Static Masking for Preprocessing
Static masking modifies sensitive data at rest and is often used during dataset preparation. DataSunrise’s Static Masking permanently transforms exports while preserving structure.
Google Cloud DLP supports similar static masking, including format-preserving techniques for structured data.
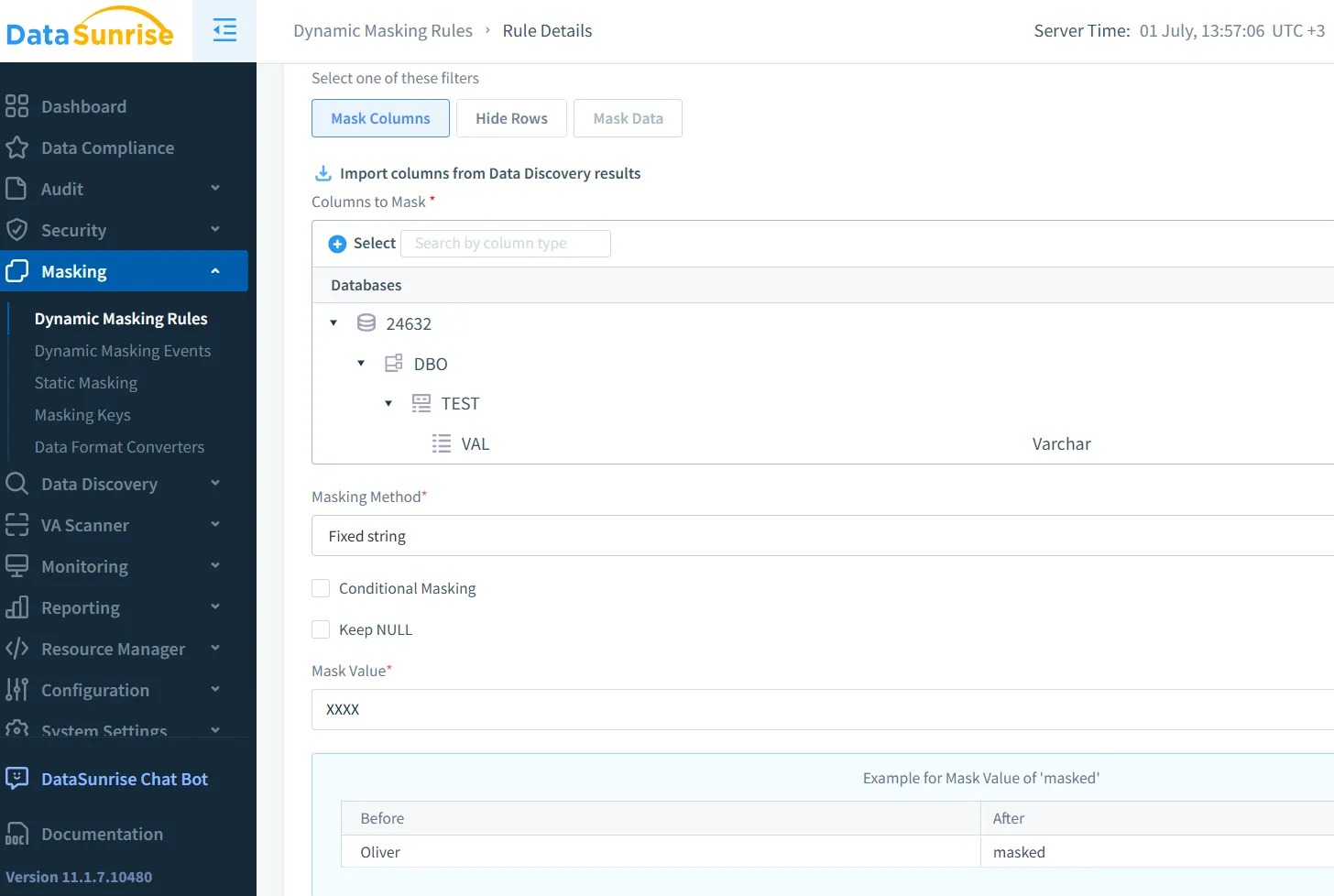
Dynamic Masking for Real-Time Use
Dynamic masking operates on live data. For example, when LLMs process user prompts, masking engines can suppress credit card numbers or national IDs before the model sees them. DataSunrise’s Dynamic Masking is well-suited for this use in production.
Amazon Macie offers a related service that scans and masks data in AWS environments. See more in this AWS post.
LLM Prompt Masking in Practice
Consider a customer support chatbot using an LLM. Messages often include private data. A dynamic rule might look like this:
CREATE MASKING RULE mask_pii
ON inbound_messages.content
WHEN content LIKE '%SSN%'
REPLACE WITH '***-**-****';
This rule prevents models from accessing raw Social Security Numbers.
By applying this logic at the middleware layer, teams don’t need to change the model. DataSunrise’s tools for LLM and ML security help automate this process using context-aware detection.
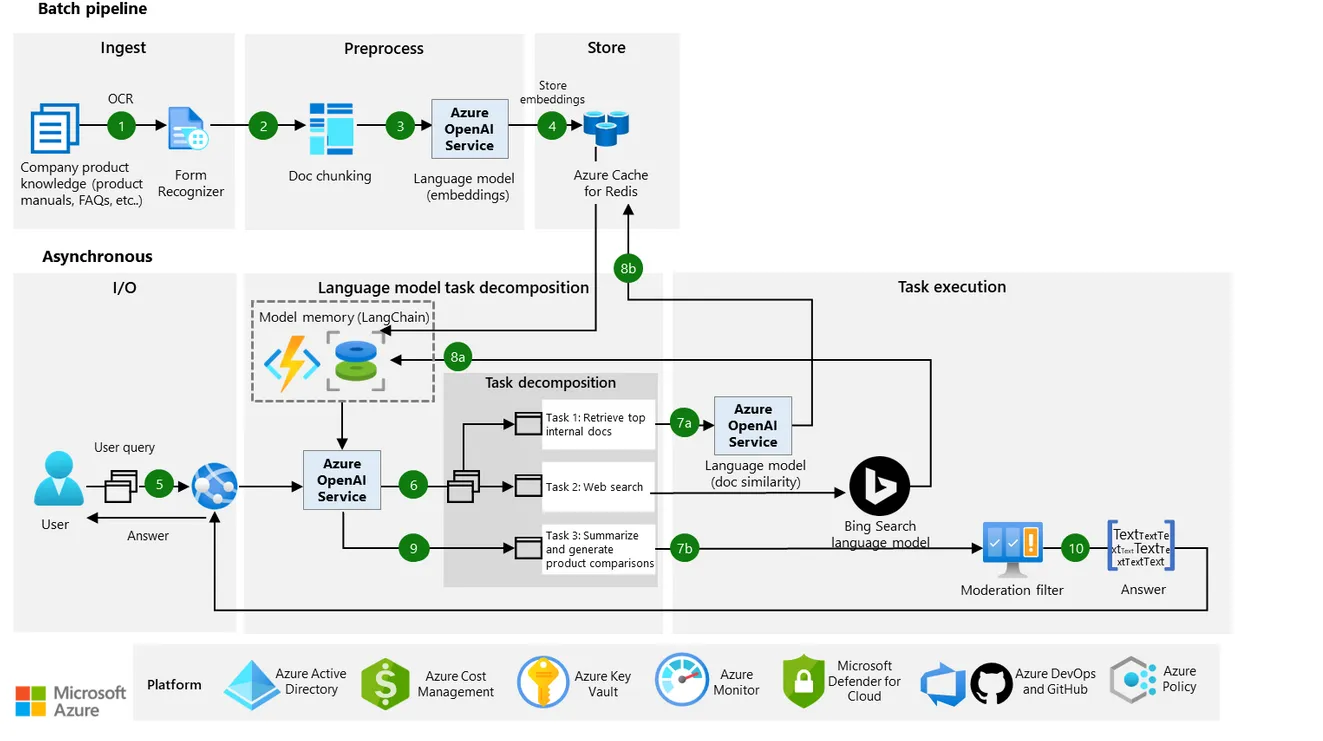
Microsoft’s architecture guidance also highlights real-time masking and responsible data use in LLM workflows.
From Masking to Contextual Access Controls
Masking is most effective when paired with role-based access controls, audit trails, and behavior analytics. A developer in staging may see realistic but fake data, while production inputs remain redacted.
When connected to activity monitoring tools, teams can catch unmasked access or trigger alerts. Masking then becomes a security layer, not just a privacy fix.
This design aligns with NIST Zero Trust principles, which prioritize restricted visibility and strict policy enforcement.
Synthetic Data as a Masking Alternative
Instead of masking real data, many teams now generate synthetic data to train or test AI models. These datasets preserve schema and logic without exposing real people.
The UK ICO recognizes synthetic data as a privacy-preserving method under GDPR, especially for AI and ML development.
Compliance Drivers and AI Risk Management
Regulations like GDPR, HIPAA, and PCI DSS require organizations to justify, anonymize, or mask sensitive data in processing. Masking supports these requirements through data minimization and risk control.
It also fits into data-inspired security models, where governance and protection are embedded in every layer.
Real-World Implementation Patterns
In real-world systems, masking typically happens through:
- Preprocessing scripts for training data
- Middleware engines for runtime masking
- Reverse proxy masking for outputs
- Auditing of inference logs
Using a reverse proxy, developers can intercept and redact sensitive data before it reaches the model or logs.
This layered approach doesn’t just improve protection—it builds trust. Users are more likely to engage when they know their input stays private.
Conclusion: Building Safer LLM Pipelines
Masking is not just a compliance checkbox. It’s a design decision that defines how safely your AI operates. Both static and dynamic masking play critical roles in protecting user data throughout the lifecycle.
When combined with discovery tools, audit policies, and security automation, these techniques help build AI systems that are secure by design.
For teams scaling GenAI, the right masking strategy can prevent breaches, reduce liability, and protect users without hindering innovation.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now