Data Anonymization in Apache Cloudberry
In today's data-driven landscape, organizations using massively parallel processing databases face mounting pressure to protect sensitive information while maintaining analytics capabilities. Apache Cloudberry, an advanced MPP database built on PostgreSQL, requires robust static masking strategies to meet modern database security demands.
According to the 2024 Cost of a Data Breach Report, organizations with comprehensive data anonymization reduce breach costs by up to 62%. With average breach costs reaching $4.88 million, implementing effective data protection for Apache Cloudberry has become a business imperative.
This article explores Apache Cloudberry's native anonymization capabilities and demonstrates how DataSunrise's Zero-Touch Data Masking enhances security with Autonomous Compliance Orchestration. For comprehensive platform details, refer to the Apache Cloudberry documentation.
Native Apache Cloudberry Data Anonymization Approaches
Apache Cloudberry, built on PostgreSQL, provides several native anonymization methods:
1. View-Based Anonymization
Create views that mask sensitive data:
-- Create anonymized view
CREATE VIEW customer_anonymized AS
SELECT
customer_id,
'Customer_' || customer_id::text AS name,
LEFT(phone, 3) || '-XXX-XXXX' AS phone,
account_balance
FROM customers;
GRANT SELECT ON customer_anonymized TO analytics_team;
2. Function-Based Data Masking
Implement reusable data masking functions:
-- Email masking function
CREATE OR REPLACE FUNCTION mask_email(email_address TEXT)
RETURNS TEXT AS $$
BEGIN
RETURN SUBSTRING(email_address, 1, 2) || '****' ||
SUBSTRING(email_address, POSITION('@' IN email_address));
END;
$$ LANGUAGE plpgsql IMMUTABLE;
-- Apply masking
SELECT customer_id, mask_email(email) AS email
FROM payment_details;
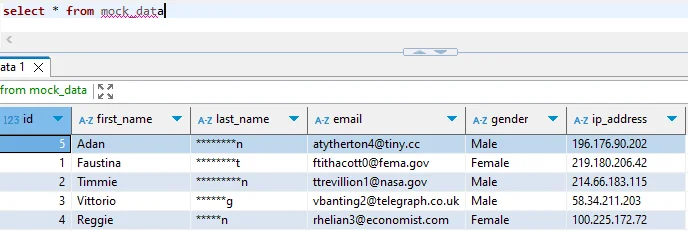
Enhanced Data Anonymization for Apache Cloudberry with DataSunrise
While Apache Cloudberry provides foundational anonymization tools, DataSunrise offers enterprise-grade capabilities with No-Code Policy Automation and Surgical Precision Masking.
Key Advantages of DataSunrise for Apache Cloudberry
Auto-Discover & Mask: DataSunrise's NLP Data Discovery automatically identifies sensitive data across schemas and tables, ensuring 95% greater coverage than manual approaches with intelligent classification based on GDPR, HIPAA, and PCI DSS patterns.
Zero-Touch Data Masking: Implement sophisticated policies through an intuitive interface without complex SQL. Autonomous Compliance Orchestration reduces implementation from weeks to hours with consistent enforcement across distributed segments.
Dynamic Context-Aware Protection: Real-time dynamic masking adapts to user roles and application context. The same data appears differently to different users, eliminating multiple anonymized dataset copies.
Centralized Policy Management: Manage anonymization for Apache Cloudberry alongside over 40 data storage platforms through a unified interface, ensuring consistent protection across heterogeneous environments.
Implementing DataSunrise for Apache Cloudberry Data Anonymization
- Connect to Apache Cloudberry: Establish connection through DataSunrise's interface with connection parameters.
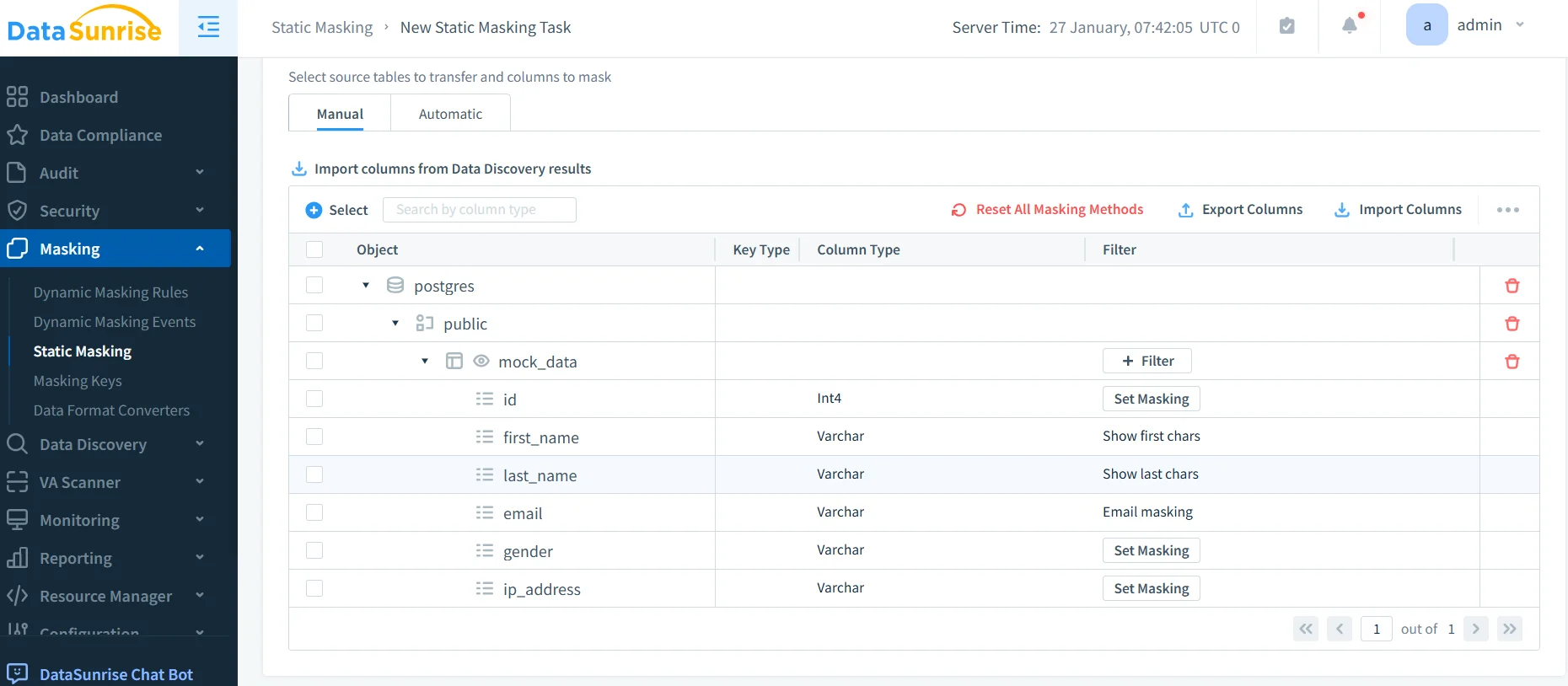
Discover Sensitive Data: Launch automated data discovery scan to identify and classify sensitive columns based on regulatory patterns.
Create Masking Rules: Configure dynamic masking policies with role-based access controls and application-based rules through the intuitive interface.
- Verify and Monitor: Test masking across user roles, validate data integrity, and generate compliance regulations reports.
DataSunrise: Advanced Features for Apache Cloudberry
Compliance Autopilot: Automated mapping to GDPR, HIPAA, PCI DSS, and SOX with one-click compliance evidence generation.
User Behavior Analytics: ML Suspicious Behavior Detection identifies anomalies indicating potential insider threats or compromised credentials.
Real-Time Monitoring: Immediate alerts for unauthorized access attempts with integration to Slack, MS Teams, and email.
Flexible Deployment: Vendor-agnostic protection with native cloud platform support across AWS, GCP, and Azure.
Best Practices for Apache Cloudberry Data Anonymization
| Best Practice | Description |
|---|---|
| Data Classification | Conduct thorough discovery to identify sensitive data and maintain accurate catalogs documenting anonymization policies |
| Performance Optimization | Balance comprehensive anonymization with query performance using Apache Cloudberry's distributed architecture |
| Testing & Validation | Validate that anonymized data maintains statistical properties and referential integrity for analytics workloads |
| Governance | Document policies, maintain audit trails, and conduct regular compliance reviews |
| Leverage DataSunrise | Deploy No-Code Policy Automation to reduce overhead and implement behavioral analytics for proactive threat detection |
Conclusion
As organizations leverage Apache Cloudberry's MPP capabilities for large-scale analytics, robust data anonymization balances data utility with privacy protection. While Apache Cloudberry provides basic anonymization through PostgreSQL views and functions, enterprises with complex data security and compliance needs benefit from advanced solutions.
DataSunrise delivers comprehensive data anonymization with Zero-Touch Data Masking, Auto-Discover & Classify capabilities, and Compliance Autopilot. With support for over 40 data storage platforms and flexible deployment modes, DataSunrise transforms data anonymization into an automated strategic asset.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now