Data Anonymization in ScyllaDB
Modern distributed databases process vast volumes of operational and customer data. When that data includes personally identifiable information (PII), financial records, or healthcare details, anonymization becomes a security necessity—not an optional enhancement.
ScyllaDB is a high-performance NoSQL database compatible with Apache Cassandra. It delivers exceptional throughput and low latency. However, when it comes to structured data anonymization, its native toolset focuses primarily on access control and encryption rather than transformation-based privacy controls.
As regulatory frameworks such as GDPR, HIPAA, and PCI DSS continue tightening requirements, organizations must ensure that sensitive information cannot be reconstructed in non-production environments.
This guide explains how anonymization works in ScyllaDB, explores native limitations, and demonstrates how DataSunrise delivers Zero-Touch Data Masking, Autonomous Compliance Orchestration, and Centralized Policy Management across distributed NoSQL clusters.
Understanding Data Anonymization in ScyllaDB
Data anonymization refers to transforming sensitive data so it can no longer identify individuals. Unlike encryption, anonymization removes reversibility. Once transformed, the original value cannot be restored.
In ScyllaDB environments, anonymization is commonly required for:
- Test and staging environments
- Analytics clusters
- Machine learning pipelines
- Data sharing with third parties
Without anonymization, copied production datasets introduce regulatory exposure and breach risk.
For broader context, see What is Data Masking and related Masking Types.
Native ScyllaDB Capabilities Relevant to Anonymization
ScyllaDB does not provide built-in static anonymization functions. Instead, it delivers foundational security controls designed to restrict access and protect data confidentiality at the infrastructure level. These controls are important, but they do not replace structured anonymization workflows required for regulated environments.
Role-Based Access Control (RBAC)
ScyllaDB supports granular permission management through role-based access control. Administrators can restrict operations such as SELECT, INSERT, UPDATE, and ALTER at the keyspace or table level. By defining roles and assigning privileges, organizations can reduce unnecessary exposure of sensitive tables.
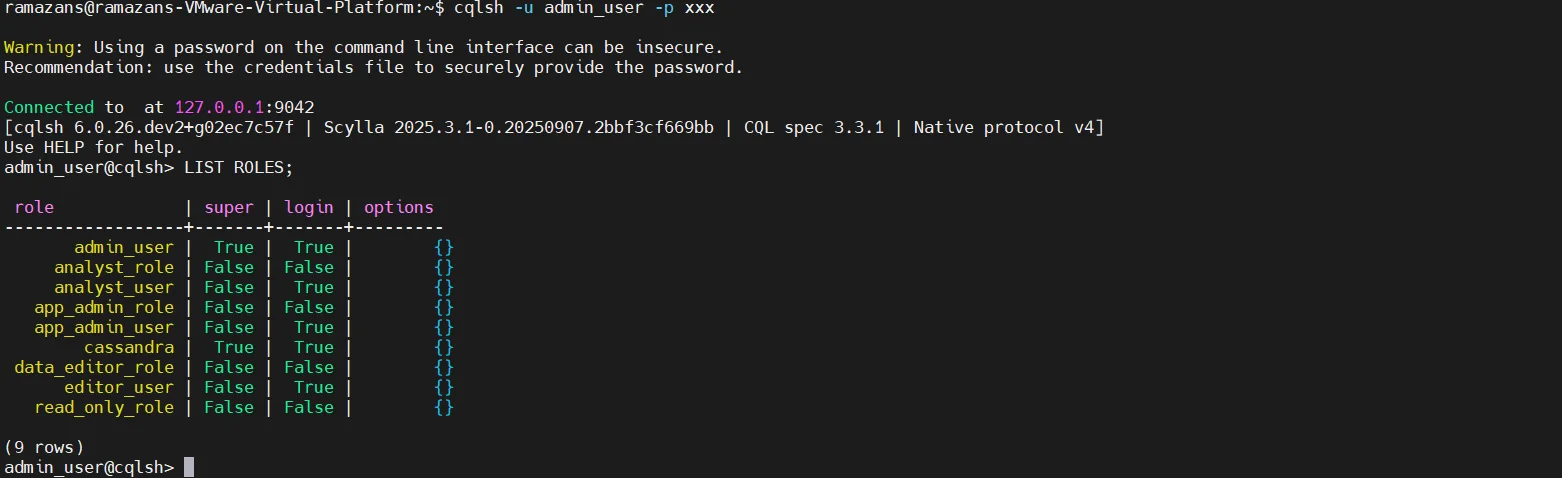
For example, a read-only analyst role can be created and limited to specific objects within a keyspace:
CREATE ROLE analyst
WITH PASSWORD = 'StrongPassword'
AND LOGIN = true;
GRANT SELECT ON keyspace1.customers TO analyst;
You can also restrict write operations explicitly:
REVOKE MODIFY ON keyspace1.customers FROM analyst;
RBAC strengthens enforcement of the Principle of Least Privilege. However, it does not modify or transform sensitive values. If a user has permission to read a column, the original data is returned in full.
SELECT credit_card_number FROM keyspace1.customers;
If access is granted, the full credit card number is returned without masking or anonymization.
Access control answers the question “Who can see the data?” — it does not answer “How should the data be transformed before being exposed?”
Encryption at Rest and in Transit
ScyllaDB supports TLS encryption for secure communication between clients and nodes, as well as internode encryption across clusters. It also supports disk-level encryption to protect stored data.
Example TLS configuration in scylla.yaml:
client_encryption_options:
enabled: true
certificate: /etc/scylla/ssl/node.crt
keyfile: /etc/scylla/ssl/node.key
truststore: /etc/scylla/ssl/ca.crt
require_client_auth: true
server_encryption_options:
internode_encryption: all
certificate: /etc/scylla/ssl/node.crt
keyfile: /etc/scylla/ssl/node.key
truststore: /etc/scylla/ssl/ca.crt
require_client_auth: true
Example disk-level encryption:
transparent_data_encryption_options:
enabled: true
cipher: AES/CBC/PKCS5Padding
key_alias: scylla_data_key
chunk_length_kb: 64
After configuration changes:
sudo systemctl restart scylla-server
These mechanisms protect confidentiality during storage and transmission. They ensure that unauthorized actors cannot intercept or read raw files at the operating system level.
However, encryption does not anonymize data. Once an authenticated and authorized user queries the database, the original values remain intact:
SELECT email FROM keyspace1.customers WHERE customer_id = 1001;
The decrypted original email is returned.
Manual CQL-Based Anonymization
In the absence of native anonymization functions, administrators sometimes rely on manual CQL scripts to transform sensitive data before exporting or replicating it to non-production environments.
Example static overwrite:
UPDATE keyspace1.customers
SET email = '[email protected]',
phone = '0000000000'
WHERE customer_id = 1001;
Example synthetic replacement:
UPDATE keyspace1.customers
SET email = uuid() || '@example.com'
WHERE email IS NOT NULL;
Example hashing approach (if handled application-side before update):
UPDATE keyspace1.customers
SET email_hash = '5f4dcc3b5aa765d61d8327deb882cf99'
WHERE customer_id = 1001;
While technically feasible, this approach introduces significant limitations. Manual scripting increases the likelihood of human error. There is no centralized governance framework to ensure consistent anonymization policies across teams or environments. Traceability becomes fragmented, and compliance alignment is difficult to validate.
In distributed ScyllaDB clusters, maintaining synchronized anonymization logic across multiple nodes and replication layers becomes operationally fragile. What works in one environment may not be consistently applied elsewhere.
As environments scale, manual anonymization quickly shifts from a tactical workaround to a structural risk.
Data Anonymization in ScyllaDB with DataSunrise
While ScyllaDB delivers exceptional performance and foundational security controls, it does not provide structured, policy-driven anonymization capabilities. DataSunrise extends ScyllaDB with Auto-Discover & Mask and Zero-Touch Data Masking, enabling controlled anonymization without modifying application logic or rewriting CQL queries. This approach aligns anonymization with broader data protection strategies rather than treating it as an isolated task.
Unlike manual scripting approaches, DataSunrise operates through flexible deployment modes—including proxy mode, sniffer mode, and native log-based monitoring—ensuring non-intrusive integration across on-prem, cloud, and hybrid ScyllaDB environments. These options are described in the official overview of Deployment Modes of DataSunrise, where proxy and sniffer architectures are explained in detail.
Centralized ScyllaDB Integration
After installation, ScyllaDB clusters are connected to DataSunrise through a centralized management console. The platform creates a unified control plane that applies anonymization and monitoring rules consistently across distributed nodes.
This centralized model is the same architectural principle used in Database Activity Monitoring, where policies are enforced uniformly across multiple data stores. It eliminates per-node configuration inconsistencies and reduces operational risk.
In addition, DataSunrise integrates anonymization workflows with broader Data Audit processes, ensuring that every transformation action is traceable and reviewable. This is critical in regulated industries where anonymization must be demonstrable—not just assumed.
The unified architecture also supports heterogeneous infrastructures, as described in the overview of supported data storage platforms, allowing anonymization governance across SQL, NoSQL, cloud-native, and hybrid deployments.
Sensitive Data Discovery Before Anonymization
Effective anonymization begins with visibility. Before transformation rules can be applied, organizations must identify where regulated or sensitive data resides.
DataSunrise includes advanced discovery mechanisms such as NLP-based analysis, pattern-driven detection, ML-assisted classification, and OCR scanning for unstructured content. These capabilities are explained in detail in the Data Discovery section of the Knowledge Center.
For example, identification of personally identifiable information follows structured classification standards described in the article on Personal Information (PII). Instead of relying on column naming assumptions, DataSunrise analyzes actual data patterns, ensuring anonymization policies are applied with surgical precision.
This discovery layer integrates naturally with broader data security strategies and continuous protection frameworks, making anonymization part of a unified compliance-first architecture rather than a post-processing step.
Static Data Anonymization Policies
Once sensitive data is identified, anonymization policies can be defined and enforced centrally. DataSunrise supports multiple transformation techniques, including substitution, hashing, tokenization, randomization, and synthetic data replacement.
Static anonymization strategies are described in the Static Masking guide, while in-database transformation approaches are outlined in In-Place Masking. For development and analytics environments requiring realistic datasets without exposing sensitive values, Synthetic Data Generation provides additional flexibility.
Policies are enforced using Automatic Policy Generation and Compliance Autopilot, eliminating the need for manual scripting or environment-specific transformation logic. Instead of rewriting CQL statements for each dataset copy, anonymization becomes embedded within the security architecture itself.
By combining discovery, centralized enforcement, auditing integration, and automated compliance alignment, DataSunrise transforms ScyllaDB anonymization from an operational workaround into an enterprise-grade governance framework.
Business Impact of Autonomous Data Anonymization
Organizations implementing centralized, policy-driven anonymization achieve measurable operational and compliance outcomes:
| Business Outcome | Impact Description |
|---|---|
| Quantifiable Risk Reduction | Sensitive data never leaves production environments in readable or exploitable form. |
| Streamlined Compliance Workflows | Automatic Compliance Policy Generation reduces audit preparation time and simplifies regulatory reporting. |
| Significant Reduction in Manual Effort | Eliminates repetitive scripting, manual exports, and environment-specific anonymization logic. |
| Optimized Total Cost of Compliance | Centralized governance lowers operational overhead and reduces long-term compliance expenses. |
| Scalable for Growth | Supports organizations from startups to Fortune 500 enterprises with flexible deployment and pricing models. |
Conclusion
ScyllaDB provides high-performance distributed data processing with strong access controls and encryption capabilities. However, it does not natively deliver structured, policy-driven anonymization for regulated environments where continuous data compliance alignment is required.
Manual CQL-based transformations introduce operational risk, inconsistency, and compliance gaps. Without centralized oversight or integrated data audit controls, organizations struggle to demonstrate that anonymization policies are applied consistently across environments.
DataSunrise delivers Zero-Touch Data Masking through its advanced static data masking capabilities, backed by Autonomous Compliance Orchestration and Enterprise-Grade Policy Enforcement for ScyllaDB across on-premise, cloud, and hybrid infrastructures. Its architecture integrates seamlessly with broader database activity monitoring frameworks, ensuring every transformation remains traceable and auditable.
By combining Sensitive Data Discovery, Compliance Autopilot, and centralized governance, organizations eliminate exposure at the source while accelerating time-to-compliance and strengthening overall data security posture.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now