Data Obfuscation in Apache Hive
Apache Hive gives data teams a familiar SQL layer over large-scale Hadoop and lakehouse storage, but that convenience also concentrates highly sensitive information in a small number of heavily queried tables. Customer names, emails, national identifiers, card fragments, payroll fields, and health-related attributes often sit side by side with the metrics analysts need every day. In that environment, data masking is not a cosmetic feature. It is a control that lets organizations keep analytics moving while reducing unnecessary exposure of Personally Identifiable Information (PII) and other regulated records.
Hive already supports built-in obfuscation functions in its UDF library, and policy engines around Hive can apply contextual masking to query results without forcing teams to clone every protected dataset. The official Apache Hive UDF documentation describes native masking functions such as mask, mask_first_n, mask_show_last_n, and sha2, while current Ranger masking guidance for Hive shows how user-, group-, and condition-based policies can anonymize query output in near real time.
The most effective approach is layered. Use SQL-based obfuscation when you need irreversible derived data, dynamic policies when different audiences need different views, and strong oversight when you must prove who accessed sensitive Hive objects. Combined with database security controls, organizations can protect analytical value without turning every report into a security exception.
Why data obfuscation matters in Hive
Hive is commonly used as a shared analytics plane. Data engineers load raw data, analysts query it through BI tools, data scientists explore it for feature engineering, and QA or support teams may need restricted access for troubleshooting. Without obfuscation, that shared model quietly expands the blast radius of every sensitive column. A single SELECT * can expose more than a role actually needs.
- Least-privilege analytics: teams can combine obfuscation with role-based access control and granular access controls so users see only the minimum level of detail needed for their job.
- Safer data sharing: analysts can still work with distributions, joins, and trends even when direct identifiers are masked or hashed.
- Better operational visibility: controls become much stronger when every query against sensitive tables is paired with activity monitoring, reviewable evidence, and accountable ownership.
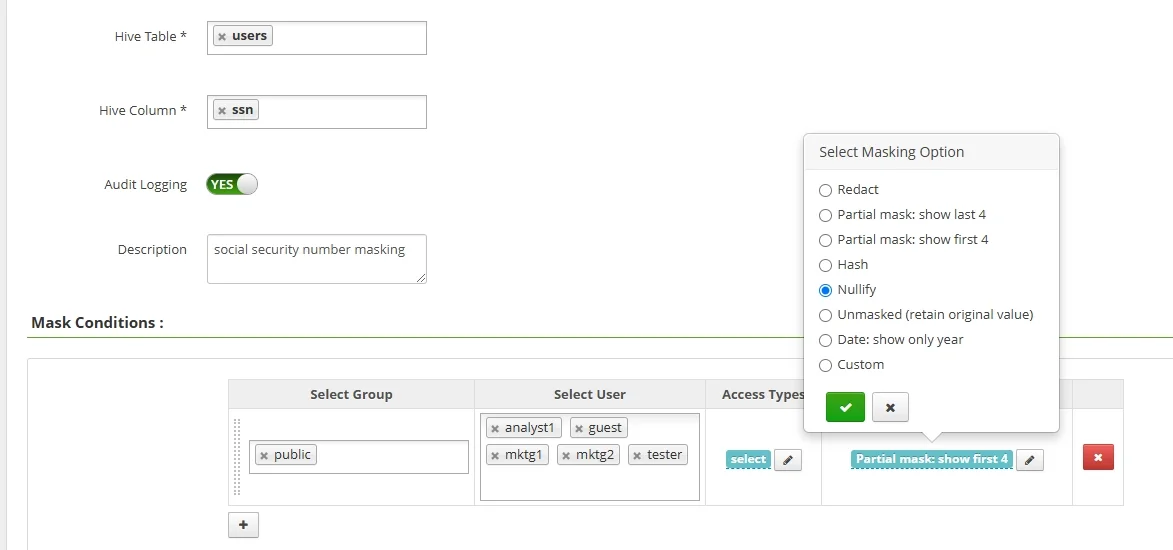
Native obfuscation options in Apache Hive
For direct SQL transformations, Hive gives you several practical patterns. Full masking is useful when the original value should never be visible in a downstream dataset. Partial masking is better when analysts need a recognizable suffix, such as the last four digits of an identifier. Hashing works when you want stable joins without preserving the original raw value. And expression-based transformations with regexp_replace, CASE, or concatenation are useful for custom pseudonymization.
SELECT
customer_id,
mask(name) AS masked_name,
mask(email) AS masked_email,
mask_show_last_n(ssn, 4) AS masked_ssn,
sha2(CAST(card_number AS STRING), 256) AS card_fingerprint
FROM prod.customer_profile;
This pattern is ideal for derived views, secure exports, and non-production copies. It also makes obfuscation logic explicit in code review. The trade-off is that SQL-based obfuscation alone does not understand business context. If finance, marketing, and support all query the same Hive object, you may need separate policies rather than a single universally masked view.
Start by classifying Hive columns into exposure tiers such as public, internal, confidential, and regulated. Then map each tier to a default masking action: for example, hash account identifiers, show only the last four characters of national IDs, and fully redact free-text fields that may contain unpredictable sensitive content.
Dynamic obfuscation for shared Hive access
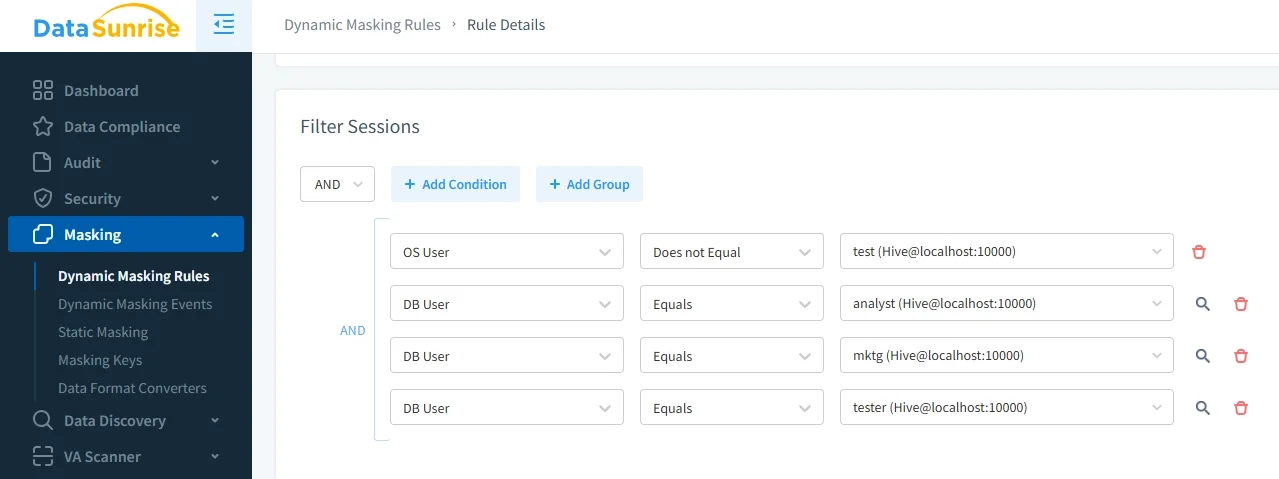
Dynamic masking becomes valuable when the same dataset must be presented differently to different users. Instead of creating multiple protected copies, the masking rule is evaluated at query time. That fits well in shared data lake environments where the raw Hive table remains intact, but the exposed result set changes according to user, group, or session conditions. It is also easier to update than a sprawl of hand-built masked tables.
DataSunrise can strengthen this model with dynamic data masking policies, session-aware conditions, and centralized rule management around Hive access paths. That matters because obfuscation is not only about replacing characters. It is about defining who may see what, under which circumstances, and how exceptions are reviewed.
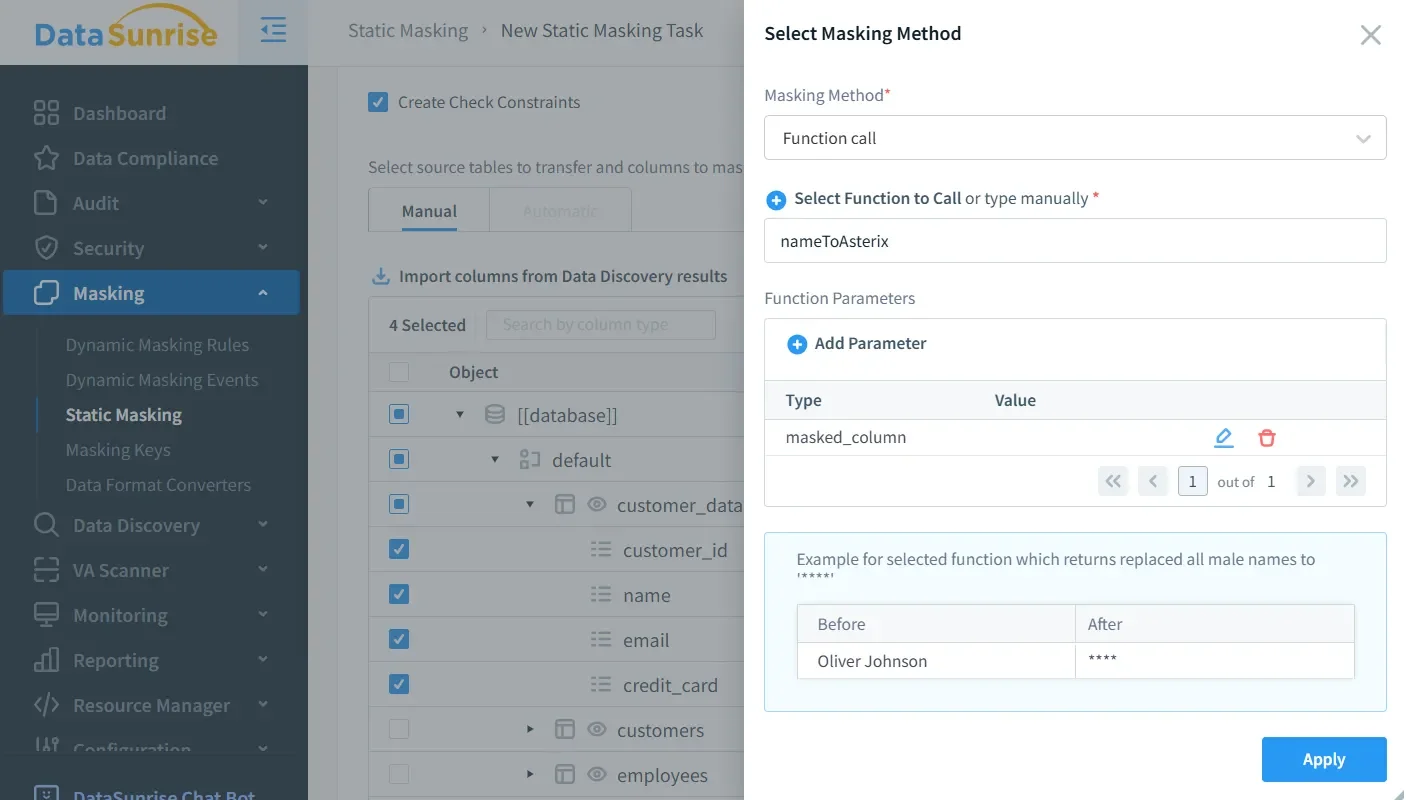
Static obfuscation for development, testing, and data science
Dynamic policies are not always enough. Some teams need a persistently transformed copy of data for QA, training, partner handoffs, or offshore development. In those cases, static data masking is the better fit because the sensitive values are transformed before the dataset is shared. That reduces the chance that copied files, extracts, or sandbox environments leak raw production content.
CREATE TABLE qa_customer_profile AS
SELECT
customer_id,
mask(name) AS name,
CONCAT('user_', customer_id, '@example.invalid') AS email,
mask_show_last_n(ssn, 4) AS ssn,
sha2(CAST(card_number AS STRING), 256) AS card_fingerprint
FROM prod.customer_profile;
Before building a masked copy, run data discovery to find hidden sensitive fields, then validate the result with vulnerability assessment and supporting controls such as database encryption. Good obfuscation design is iterative: discover, classify, mask, test, and review.
Auditability and operational guardrails
Obfuscation is only defensible when you can explain how it is enforced. That is why mature Hive programs pair masking with audit, searchable audit logs, and continuous database activity monitoring. When a user queries a protected table, security teams should be able to answer four questions quickly: which object was accessed, which rule applied, what result was returned, and whether the request matched policy.
DataSunrise helps centralize that workflow with its security guide, broader data compliance regulations coverage, and automated evidence collection through Compliance Manager. This is especially useful in regulated Hive deployments where internal analytics still fall under external review.
If your Hive environment uses Ranger masking or row filtering together with ACID compaction, make sure compaction users are excluded from those policies. Vendor guidance warns that otherwise masked or filtered results can be written back during compaction, which can overwrite original unmasked data and lead to data loss.
Compliance alignment for Hive obfuscation
Obfuscation does not replace governance, but it makes governance practical. It allows organizations to minimize direct exposure while still supporting analytics, testing, and operational support. In Hive environments, that can materially reduce risk under common frameworks:
| Regulation | Hive concern | Useful obfuscation control |
|---|---|---|
| GDPR | Unnecessary access to personal data in broad analytics workflows | Mask direct identifiers, log access, and limit exposure by role |
| HIPAA | Use of protected health information in shared query environments | Dynamic masking plus strict audit trails for clinical and support users |
| PCI DSS | Cardholder data appearing in BI results, extracts, or QA copies | Hash or truncate payment fields and monitor sensitive queries |
| SOX | Financial datasets queried by multiple operational teams | Policy-based exposure control with evidence for internal audit |
DataSunrise for Apache Hive obfuscation
For organizations that need more than ad hoc SQL masking, DataSunrise provides a structured control layer around Hive access. It combines discovery, policy enforcement, monitoring, and compliance workflows in one place. That helps teams move from one-off transformations to an operating model that is repeatable and reviewable.
- Discover before you mask: identify risky columns, shadow data, and forgotten replicas before building obfuscation policies.
- Apply the right method: choose partial reveal, nullification, hashing, or custom transformation based on data sensitivity and business use.
- Prove enforcement: connect masked access events to security evidence and compliance reporting.
In practice, good Hive obfuscation is not about hiding everything. It is about exposing only what each user needs, preserving analytical utility, and keeping the raw source under tighter control. When combined with clear ownership, tested rules, and auditable policy changes, obfuscation becomes a durable control rather than a temporary workaround.
Conclusion
Data obfuscation in Apache Hive works best as a layered program: native Hive functions for deterministic transformation, dynamic policies for context-aware exposure, static masking for safe downstream copies, and audit for proof of control. Teams that treat obfuscation as part of architecture rather than a late-stage patch are better prepared to support analytics, development, and compliance at the same time.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now