How to Apply Static Masking in MongoDB
DataSunrise deploys Zero-Touch Data Masking to generate production-safe test datasets without manual reconfiguration or fragile scripting. When teams share MongoDB data for QA, analytics, DevOps, or AI model training, production clones often contain regulated attributes such as email addresses, financial identifiers, and medical information. Without structured masking, every copied environment becomes a latent compliance liability.
Static masking in MongoDB permanently replaces sensitive values in a duplicated dataset rather than filtering them at query time. The outcome is a sanitized, non-reversible data copy that can safely operate outside production boundaries. This approach aligns with major regulatory frameworks including GDPR and HIPAA, while strengthening broader data security strategies and reducing exposure risks across development and testing pipelines.
This guide explores MongoDB-native masking techniques, analyzes their operational limitations, and explains how DataSunrise enables Autonomous Compliance Orchestration for enterprise-grade static masking in MongoDB environments.
What is Static Masking?
Static masking is a data protection technique that permanently transforms sensitive information in a copied dataset. Unlike runtime filtering or role-based obfuscation, static masking modifies the data itself before it is delivered to non-production environments. Once applied, the original values cannot be restored from the masked dataset.
In MongoDB environments, static masking typically applies to collections containing personally identifiable information (PII), payment data, healthcare records, or confidential business attributes. Instead of exposing real values, masking policies replace them with randomized, hashed, tokenized, or format-preserving substitutes. The masked dataset maintains structural integrity, document relationships, and realistic data distribution, which ensures applications continue to function correctly in testing or analytics scenarios.
Static masking differs from dynamic data masking, which alters results at query time based on user roles. While dynamic masking protects production systems in real time, static masking is designed specifically for secure data provisioning. It works closely with automated data discovery processes to identify sensitive attributes before transformation begins.
When implemented correctly, static masking becomes a foundational element of modern data masking strategies. It also strengthens broader database security frameworks by ensuring regulated data is never replicated in readable form across development, testing, analytics, or external environments.
Native MongoDB Approaches to Static Masking
MongoDB does not include a built-in static masking engine. As a result, administrators must simulate masking workflows using aggregation logic or external data transformation processes. While these methods can produce sanitized copies of collections, they require manual effort and careful validation to avoid incomplete masking.
Masking with Aggregation Pipelines
One common approach relies on MongoDB’s aggregation framework. Administrators can create a transformed collection by using operators such as $project, $set, or $merge. For example, an aggregation pipeline may replace email addresses with generated values, overwrite phone numbers with placeholders, and substitute social security numbers with fixed patterns before writing the result into a new collection like users_masked.
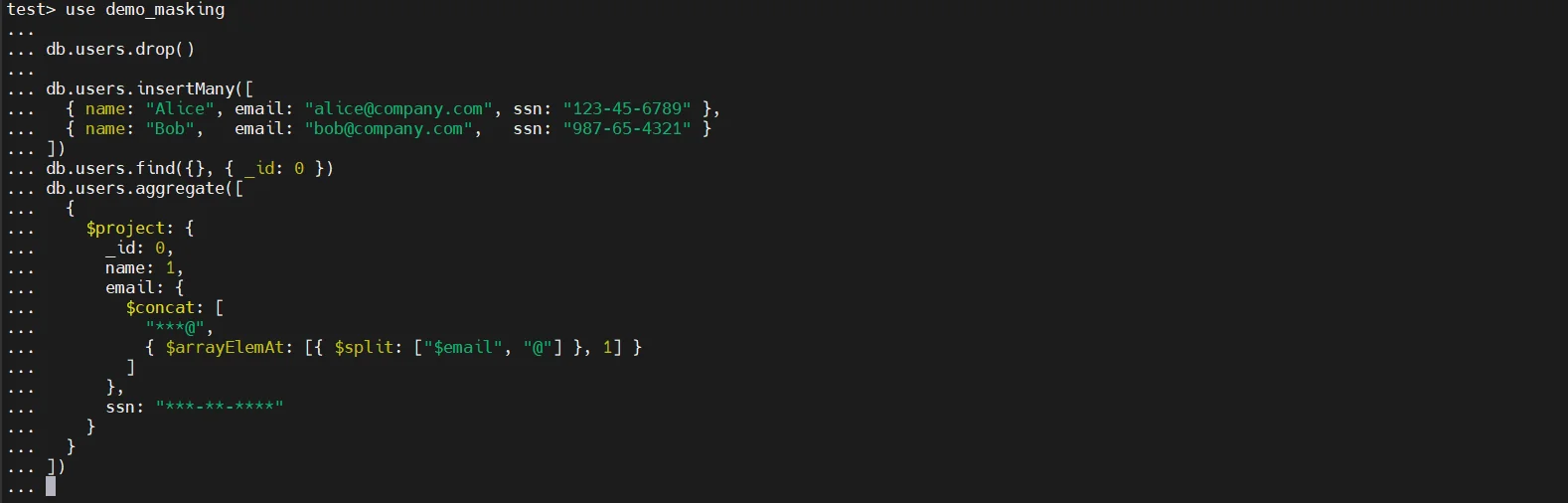
This method effectively creates a duplicated dataset with substituted values. However, it is entirely script-driven. Each collection must be handled individually, and transformation logic must be carefully written and maintained.
The limitations are significant. The process requires manual scripting and offers no centralized rule management. There is no automated sensitive data detection, meaning administrators must already know which fields contain regulated data. Additionally, there is no compliance-ready reporting, and nested documents or array-based structures may be overlooked if transformation logic is incomplete. In large MongoDB environments with flexible schemas, this increases the risk of masking gaps.
Export–Transform–Import Workflow
Another common strategy follows an export–transform–import cycle. Administrators first export production data using mongodump.
mongodump --uri="mongodb://prod-host:27017/appdb" --out=/backup/prod_dump
The exported files are then processed using external scripts, typically written in Python or Node.js, to replace or anonymize sensitive values.
# Example transformation snippet (simplified)
import json
with open("users.json", "r") as f:
data = json.load(f)
for doc in data:
doc["email"] = f"masked_{doc['_id']}"
doc["phone"] = "XXX-XXX-XXXX"
doc["ssn"] = "000-00-0000"
with open("users_masked.json", "w") as f:
json.dump(data, f)
After transformation, the sanitized dataset is re-imported into a separate MongoDB instance.
mongorestore --uri="mongodb://dev-host:27017/appdb_masked" /backup/masked_dump
Although technically functional, this approach introduces operational overhead. It requires external tooling, intermediate storage handling, and careful scripting validation. Each execution becomes a custom workflow, which increases the probability of human error. Moreover, as data structures evolve, transformation scripts must be continuously updated, creating long-term maintenance complexity.
Both approaches can produce masked datasets, but neither provides automation, centralized governance, or compliance-aligned orchestration at scale.
Applying Static Masking in MongoDB with DataSunrise
Applying static masking in MongoDB with DataSunrise transforms dataset provisioning from a manual scripting task into a controlled, policy-driven security process. Instead of building custom aggregation pipelines or maintaining export–transform scripts, organizations rely on centralized orchestration to generate production-safe MongoDB copies with consistent governance and compliance alignment.
Static masking operates as a structured workflow in which sensitive data is identified, masking policies are generated, and sanitized dataset copies are created for non-production environments. Each stage is automated, traceable, and centrally managed, ensuring repeatability and operational control.
Sensitive Data Discovery Before Masking
Before applying static masking to MongoDB collections, DataSunrise performs automated Sensitive Data Discovery. The platform scans structured and semi-structured documents, including nested objects and arrays, to detect regulated attributes such as PII, PHI, financial identifiers, and organization-specific sensitive fields.
This discovery phase ensures that masking policies are based on actual data content rather than assumptions. In flexible MongoDB schemas, where fields may vary between documents, this significantly reduces the risk of leaving unmasked attributes in copied datasets.
Policy-Driven Static Masking Configuration
Once sensitive fields are identified, administrators configure a static masking policy through centralized management. Instead of modifying MongoDB queries or writing transformation scripts, masking rules are defined and enforced at the platform level.
For MongoDB collections, policies specify target databases and collections, particular fields or document paths, selected masking techniques such as substitution, hashing, randomization, or format-preserving masking, and the destination environment for the masked dataset copy.
These policies remain reusable and consistently applied across clusters and environments. This eliminates fragmented rule logic and ensures governance standards are maintained across the organization.
Generating Masked MongoDB Dataset Copies
When the masking job is executed, DataSunrise generates a sanitized copy of the selected MongoDB collections. The original production data remains unchanged, while the duplicated dataset contains permanently transformed sensitive values.
During execution, the platform preserves document structure and referential consistency, applies masking transformations according to defined policies, logs execution details for traceability, and produces compliance-ready documentation.
This controlled workflow ensures that development, QA, analytics, and AI training environments operate on safe datasets without exposing regulated information.
Compliance-Aligned Static Masking Across Environments
Applying static masking in MongoDB is not restricted to a single deployment model. DataSunrise integrates using proxy, sniffer, or native log trailing modes, enabling connection without intrusive architectural changes.
Masking policies align with regulatory frameworks such as GDPR, HIPAA, PCI DSS, and SOX. Continuous regulatory calibration ensures that static masking remains consistent with evolving compliance requirements.
As a result, applying static masking in MongoDB with DataSunrise becomes part of a centralized compliance strategy. Organizations gain unified visibility, reduced manual effort, and measurable risk reduction while securely provisioning MongoDB datasets across on-premise, cloud, and hybrid infrastructures.
Business Impact of Static Masking for MongoDB
| Business Outcome | Impact Description |
|---|---|
| Quantifiable Risk Reduction | Eliminates live PII and sensitive production data from non-production MongoDB environments, strengthening overall data security posture and reducing breach exposure. |
| Optimized Total Cost of Compliance | Automates masking workflows and aligns with centralized data compliance initiatives, lowering operational overhead and minimizing manual compliance management costs. |
| Enhanced Audit Preparation | Provides traceable masking logs and one-click compliance evidence integrated with report generation capabilities for internal audits and external regulators. |
| Significant Reduction in Manual Effort | Removes dependency on custom scripts within DevOps pipelines while integrating with broader database activity monitoring frameworks. |
| Streamlined Compliance Workflows | Ensures consistent masking policies across on-premise, cloud, and hybrid MongoDB deployments through centralized governance and automated policy enforcement. |
This structured static masking approach supports regulatory frameworks including GDPR, HIPAA, PCI DSS, SOX, ISO 27001, and NIST, strengthening enterprise-wide governance and compliance posture.
Conclusion
MongoDB offers flexibility and scalability, but it does not natively provide enterprise-grade static masking orchestration. Manual aggregation scripts can create sanitized datasets, yet they lack automation, discovery intelligence, and compliance alignment.
DataSunrise delivers Zero-Touch Data Masking, Autonomous Compliance Orchestration, and Centralized Policy Management for MongoDB and heterogeneous environments. Through integrated Sensitive Data Discovery, reusable policies aligned with Static Data Masking, and audit-ready reporting within a centralized Compliance Manager, organizations eliminate compliance gaps while accelerating secure data provisioning.
If you are ready to apply enterprise-grade static masking in MongoDB without operational complexity, explore DataSunrise Deployment Modes or request a live demo to see autonomous masking in action.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now