Data Anonymization in Amazon OpenSearch
Data anonymization in Amazon OpenSearch becomes essential when log analytics and observability platforms start storing more than operational metadata. OpenSearch clusters frequently ingest authentication events, application payloads, support case references, and telemetry tied to real individuals. Over time, those indices may contain names, emails, phone numbers, IP addresses, device identifiers, and other sensitive attributes.
Unlike structured databases with well-defined schemas, OpenSearch stores semi-structured JSON documents that evolve continuously. Fields can be added dynamically, nested objects may grow over time, and ingestion pipelines often prioritize speed over governance. This flexibility is powerful for analytics—but risky for regulated data.
Amazon provides the infrastructure for Amazon OpenSearch Service, but responsibility for protecting regulated data remains with the organization operating the environment. Anonymization techniques help reduce exposure while preserving search functionality, analytics value, and operational workflows.
This guide explains how to implement data anonymization in Amazon OpenSearch using layered controls such as discovery, dynamic masking, monitoring, and auditing—without disrupting performance or investigative capability.
What Data Anonymization Means in OpenSearch
Data anonymization transforms or removes identifying elements so that individuals cannot be directly identified from query results. In search-driven environments like OpenSearch, anonymization must preserve:
- Search relevance and filtering
- Aggregation and analytics capabilities
- Operational usability for SOC and DevOps teams
Unlike simple access control, anonymization focuses on the output layer—what users actually see when a query runs. In other words, a user may be authorized to query an index, but they should not automatically see raw sensitive values returned in the response.
Sensitive attributes typically include PII, authentication metadata, account identifiers, and contextual user references embedded in logs. Because OpenSearch stores semi-structured JSON documents, these values often appear inside nested fields, arrays, or free-text “message” attributes. This makes static rule-based filtering unreliable unless backed by automated discovery.
Why Anonymization Is a Governance Requirement
Once OpenSearch contains regulated data, it falls under broader data compliance regulations. Frameworks such as GDPR, HIPAA, PCI DSS, and SOX compliance require controlled exposure and traceability.
Anonymization supports compliance objectives by:
- Reducing unnecessary exposure to sensitive fields
- Aligning visibility with role-based responsibilities
- Limiting impact if credentials are misused
- Providing defensible evidence of protective controls
Regulators increasingly expect demonstrable, policy-driven controls—not informal agreements about who “should” look at what data. Anonymization policies must be enforceable, consistent, and auditable.
Core Techniques for Data Anonymization in OpenSearch
| Technique | Application Layer | Operational Impact |
|---|---|---|
| Dynamic masking | Query results | Preserves search functionality while protecting sensitive values |
| Field suppression | Query results | Removes high-risk fields for specific roles |
| Partial masking | Query results | Retains limited context (e.g., last 4 characters) |
| Ingestion filtering | Pre-indexing | Prevents sensitive values from being stored at all |
For most Amazon OpenSearch deployments, dynamic data masking is the most practical anonymization mechanism because it applies protection at query time without requiring reindexing or restructuring of existing indices.
Dynamic masking allows organizations to anonymize data selectively based on identity, role, or contextual rules. This makes it possible to maintain investigative capability for authorized roles while limiting exposure for general users.
Architecture: Enforcing Anonymization on the Access Path
Anonymization only works if queries pass through the enforcement layer. Direct access to OpenSearch bypasses controls. Flexible deployment modes allow positioning anonymization between users and the OpenSearch cluster.
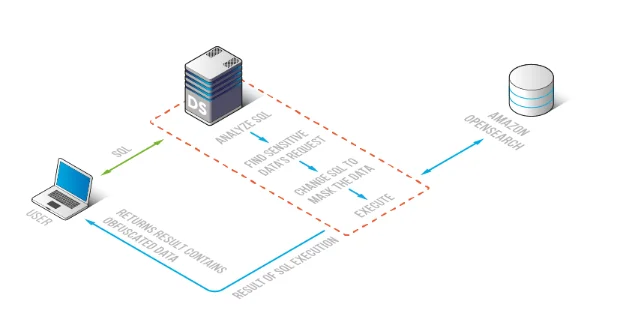
This architecture ensures consistent application of anonymization policies across dashboards, scripts, and investigative workflows. It also centralizes logging and auditing so that enforcement can be validated independently of individual applications.
Step 1: Discover Sensitive Data
Before anonymizing data, identify where sensitive attributes exist. Automated data discovery scans indices for regulated patterns and builds a living inventory of sensitive fields.
Discovery prevents blind spots in nested documents and evolving schemas. It also allows anonymization policies to be driven by actual data risk rather than assumptions about which fields might contain sensitive information.
Step 2: Define Role-Based Visibility Rules
Not all users require full visibility. Apply:
Governance coordination can be managed using Compliance Manager, which aligns anonymization rules with broader compliance programs and reporting requirements.
Step 3: Configure Dynamic Anonymization Rules
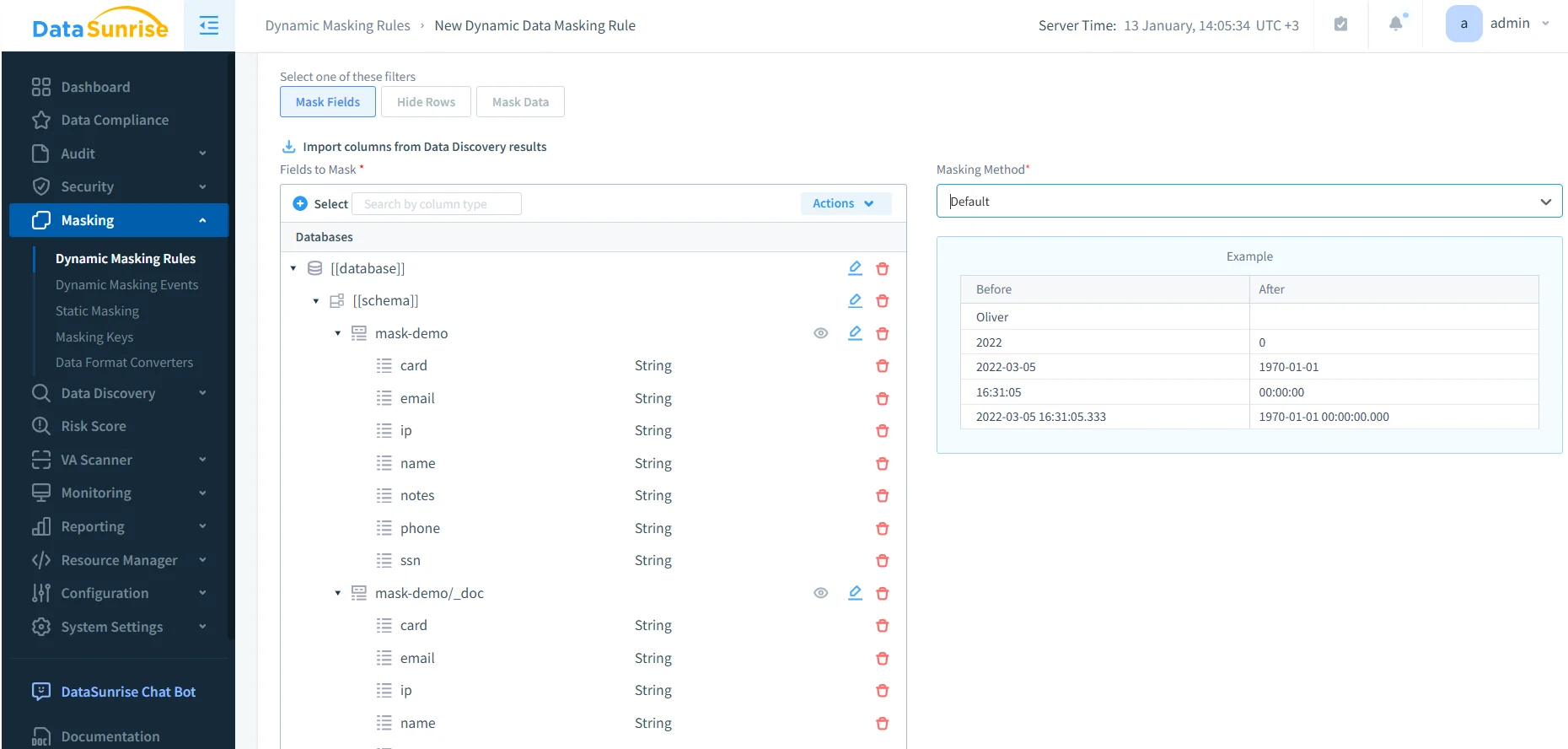
Configuring dynamic anonymization rules for sensitive fields allows you to:
- Start with high-risk identifiers (email, phone, IP, account IDs)
- Preserve analytical context where necessary
- Resolve overlapping rules using rules priority
Validation should include real query testing before and after rule activation to ensure that sensitive values are properly anonymized while analytics remain intact.
Step 4: Monitor and Audit Enforcement
Anonymization must be continuously verifiable. DataSunrise provides:
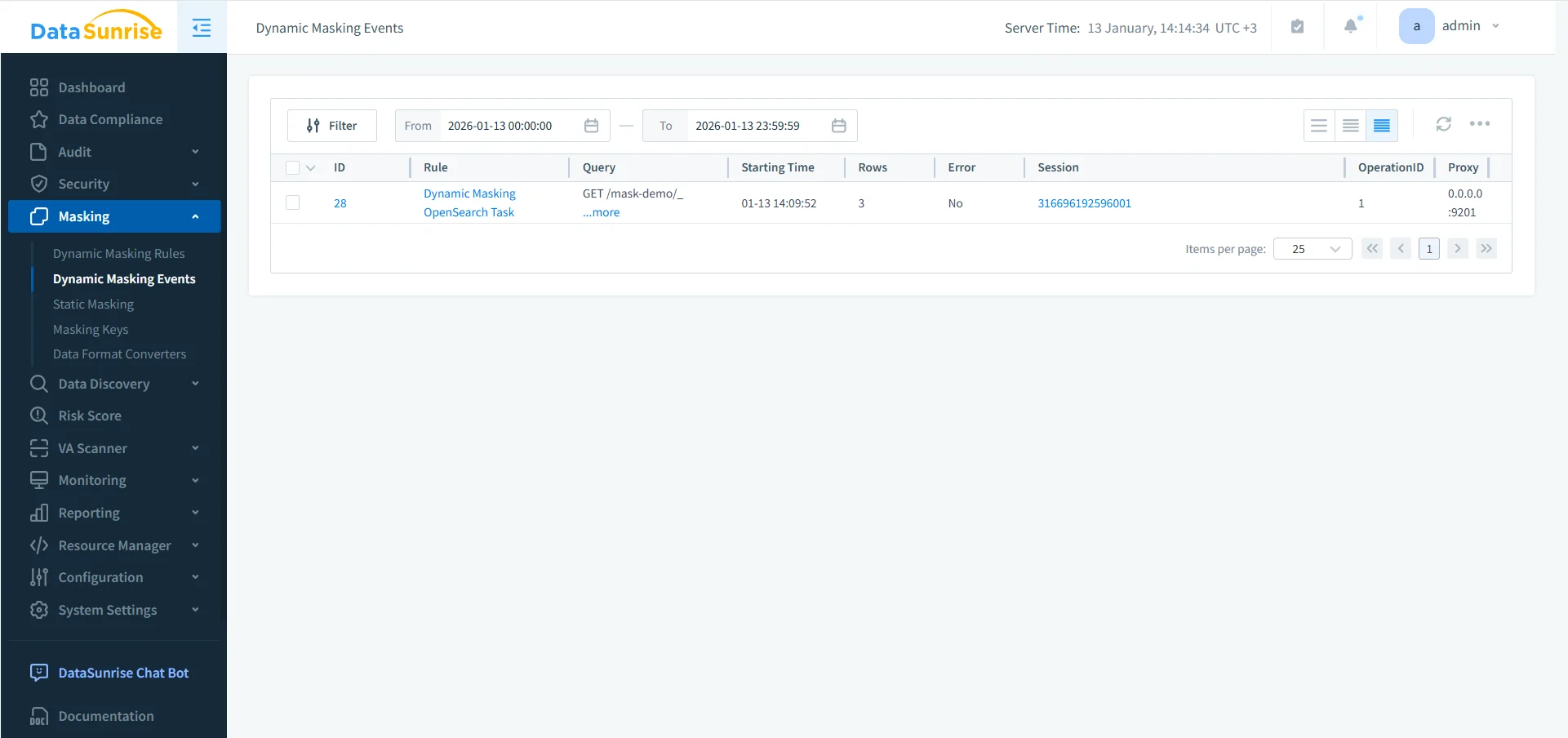
AWS also provides baseline logging: Amazon OpenSearch audit logs. However, centralized auditing ensures consistency across environments and simplifies compliance reporting.
Strengthening Anonymization with Preventive Controls
- Database firewall
- Vulnerability assessment
- Continuous data protection
- User behavior analysis
- Report generation
Implement discovery-driven anonymization and validate masking behavior using real queries before expanding coverage.
Anonymization does not replace ingestion controls. Remove secrets and credentials before indexing—searchable secrets remain high-risk even if partially masked.
Conclusion
Data anonymization in Amazon OpenSearch requires coordinated controls: discovery, role-based visibility, dynamic masking, monitoring, and audit evidence. When implemented correctly, anonymization protects regulated data while preserving operational performance and analytical capabilities.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now