Data Anonymization in Apache Hive
Apache Hive makes it easy to run SQL over large data sets, but that same convenience can expose customer identifiers, account numbers, salary fields, medical attributes, and other sensitive records to far more people than necessary. In that setting, data masking and broader anonymization techniques help teams preserve analytical value while reducing direct exposure of personally identifiable information. Hive’s current UDF manual documents built-in masking functions such as mask, mask_first_n, mask_last_n, mask_show_first_n, mask_show_last_n, plus hashing functions like sha2, which makes Hive a practical place to implement anonymization close to the data layer.
At the policy layer, current Hive masking guidance shows that Apache Ranger can dynamically mask or anonymize sensitive Hive columns in near real time, including options such as partial reveal, hash, nullify, and date-only masks. The same guidance notes that policies can be scoped to specific users, groups, and conditions, which is exactly what shared analytics environments need when one table is queried by analysts, support staff, and engineers with different privileges. See the current Ranger masking guidance for Hive for the policy model behind that approach.
That is why anonymization in Hive should be treated as part of database security, not as a last-minute reporting trick. The best designs combine SQL transformations, role-aware runtime masking, monitoring, and controlled non-production copies so teams can keep working with data without routinely exposing raw identifiers.
What anonymization really means in Hive
In practice, anonymization in Hive usually covers several patterns. Some teams need partial reveal, such as keeping only the first or last few characters of an identifier for support workflows. Others need one-way hashes so they can join records without keeping the original value visible. And when data must leave production for QA or training, teams often need stronger transformations that remove direct identifiers entirely. The common thread is minimization: expose only what a user or system truly needs.
That goal becomes much easier to manage when anonymization is paired with access controls, role-based access control, and broader data security practices. In other words, anonymization is strongest when it is not the only barrier.
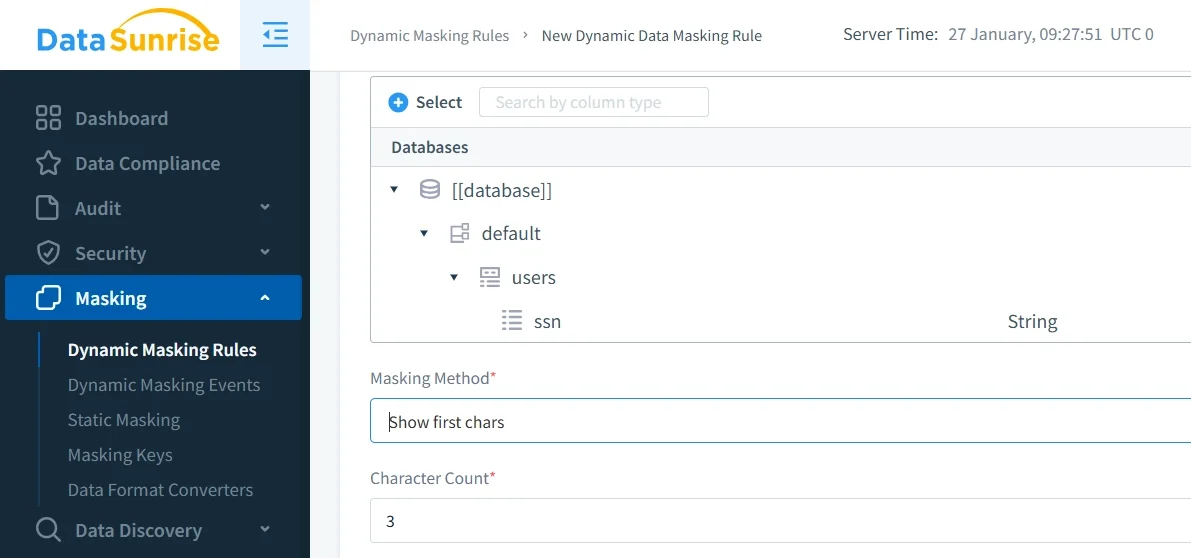
Native Hive anonymization techniques
For teams that want anonymization directly in SQL, Hive already provides a solid base. The platform supports built-in data masking functions and lets administrators or developers preserve only selected characters while hiding the rest. The same function set also includes hashing options that are useful when the business needs stable pseudonymous keys instead of the original value.
A practical Hive anonymization strategy usually combines four approaches:
- full masking for values that should never be visible in analytics;
- partial masking for identifiers that still need to be recognized by suffix or prefix;
- hashing for consistent joins and deduplication without exposing the raw source;
- generalization for fields like dates or geography where trend analysis matters more than exact values.
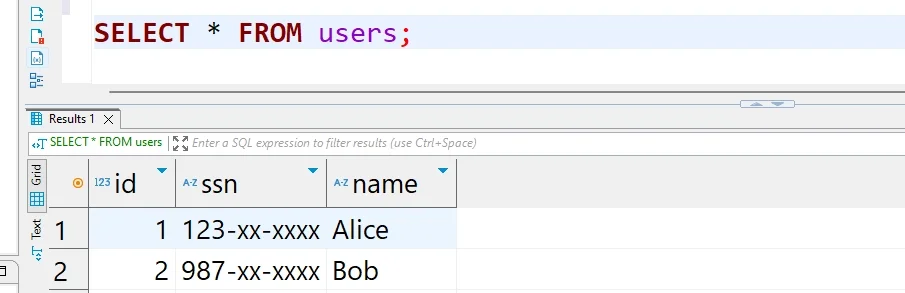
SELECT
id,
mask_show_first_n(ssn, 3) AS anonymized_ssn,
sha2(lower(email), 256) AS email_hash,
year(created_at) AS signup_year,
mask(name) AS masked_name
FROM default.users;This pattern works well for derived views, extracts, and reporting layers. It also helps teams decide when to use static data masking for copied data sets and when in-place masking makes more sense for tightly controlled environments.
Start by classifying Hive columns according to exposure risk, then map each class to a default anonymization method. For example, use full masking for direct identifiers, one-way hashes for join keys, and year-level generalization for dates in non-production analytics. That policy-first approach keeps anonymization consistent even as tables and users change.
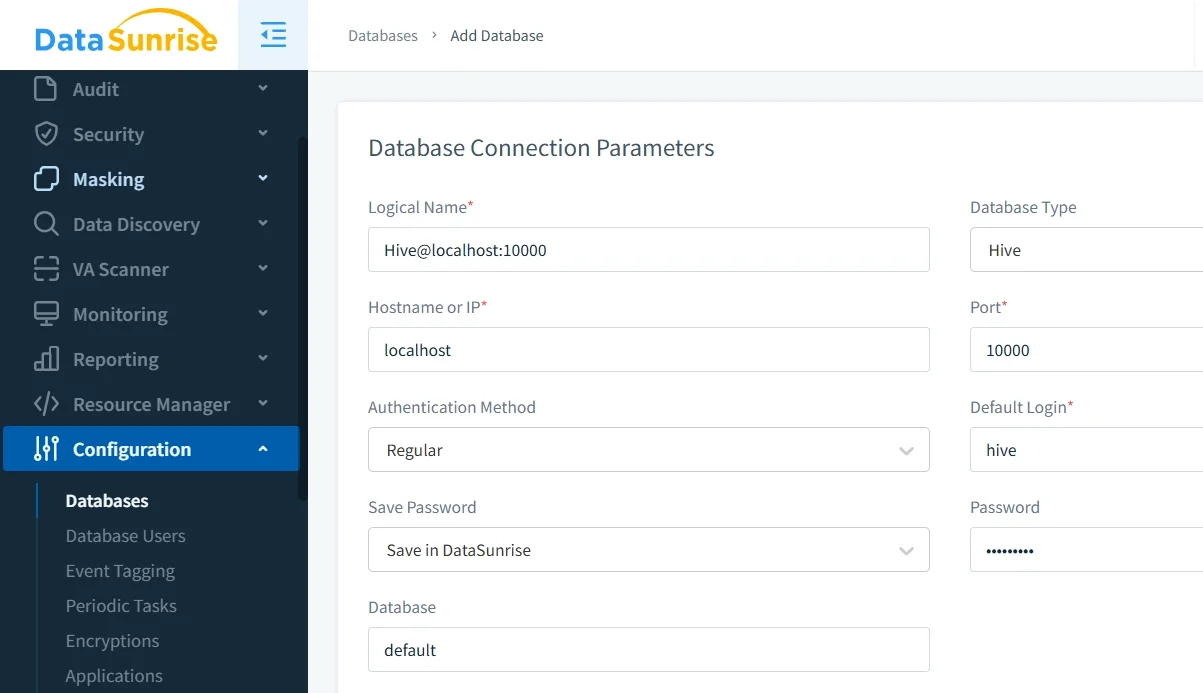
Dynamic anonymization for shared Hive access
Static SQL transformations are useful, but they are not always enough. In many Hive deployments, the same table must be presented differently to different audiences. Finance may need more detail than marketing, and support may need recognizable fragments that external users should never see. Current Ranger guidance for Hive addresses exactly this use case: masking policies are column-specific, can be filtered by user, group, and condition, and are applied to query results without requiring application rewrites or duplicate protected copies of the same dataset.
That model aligns closely with dynamic data masking in DataSunrise. Query-time anonymization is especially valuable when raw Hive tables must remain intact for trusted processes, while less-privileged users receive masked results on demand. It also works well alongside database encryption because encryption protects data at rest and in transit, while anonymization limits what a user can actually see after access is granted.
Another operational advantage is where enforcement happens. In most Hive deployments, policy-driven masking is attached to the normal Hive access path rather than bolted onto downstream dashboards. That makes runtime anonymization more durable, easier to audit, and simpler to manage as users and datasets change.
Building anonymized Hive copies for development and testing
There are also cases where query-time masking is not enough. Development, QA, offshore engineering, vendor support, and machine learning sandboxes often need data that can be shared repeatedly without depending on live production policies. In those situations, the safer approach is to create an anonymized copy and validate it before use. This is where data discovery becomes critical: many Hive tables contain more sensitive columns than teams initially expect, especially when free-text notes, legacy columns, or denormalized exports are involved.
A strong workflow is to discover sensitive fields, create a transformed copy, and then decide where synthetic replacement is better than masking. For example, synthetic data generation can preserve statistical usefulness in cases where even hashed or partially revealed values create re-identification risk. That complements broader test data management practices and helps keep non-production environments useful without keeping them dangerous.
If you use Ranger-based masking alongside Hive ACID compaction, test the workflow carefully in staging before broad rollout. Query-time anonymization rules should be validated together with service accounts, maintenance jobs, and downstream processes so masked results are not applied where full raw values are still required for core platform operations.
Auditability, governance, and compliance
Anonymization is much more credible when it is observable. It is not enough to say a column should be masked; security teams need evidence that the policy was applied, to whom, and when. That is why mature Hive programs pair anonymization with audit, searchable audit logs, and continuous database activity monitoring. For broader programs, centralized data audit and Compliance Manager workflows make it easier to turn policy enforcement into reviewable evidence.
This matters because anonymization in Hive is often part of a wider compliance program. Organizations usually are not anonymizing data just for elegance; they are reducing exposure under internal policy and external regulation. Compliance regulations give the business context, while technical enforcement gives those obligations practical meaning.
| Regulation | Typical Hive Risk | Anonymization Approach |
|---|---|---|
| GDPR | Broad analyst access to personal identifiers | Mask direct identifiers and restrict re-identification paths |
| HIPAA | Clinical or support users seeing more patient detail than required | Dynamic query-time anonymization plus audit evidence |
| PCI DSS | Payment-related fields leaking into BI tools or QA copies | Hash, truncate, or nullify sensitive payment values |
| SOX | Finance tables queried across multiple operational roles | Role-aware exposure rules with retained access evidence |
DataSunrise for Apache Hive anonymization
For teams that need more than hand-written SQL, DataSunrise adds a centralized control plane around Hive anonymization. It helps combine masking policy management, discovery, monitoring, and governance in one workflow. In practice, that means teams can connect Hive, identify risky columns, define rule logic, and review enforcement without depending on scattered scripts or one-off views.
That broader operating model is where supporting controls matter. Vulnerability Assessment helps uncover configuration weaknesses around the environment, the Security framework ties anonymization to access policy and monitoring, and continuous data protection keeps the focus on reducing real-world exposure rather than just changing how a single query looks.
Conclusion
Data anonymization in Apache Hive works best as a layered design. Native Hive functions handle direct SQL transformations. Policy-driven masking handles shared access in real time. Static anonymized copies protect non-production and external use cases. Audit and compliance workflows prove that the controls are doing what they are supposed to do.
Used that way, anonymization does not block analytics. It makes analytics safer, more governable, and easier to scale across teams that should never need the same level of visibility into sensitive data.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now