Data Anonymization in Sybase
Data anonymization in Sybase addresses a critical gap in protecting sensitive data outside production environments.
Sybase ASE provides access control and encryption mechanisms but does not include native capabilities for irreversible data anonymization. As a result, when data is copied to development, analytics, or external systems, sensitive information often remains exposed. According to IBM’s data security guidance and the NIST Data Privacy Framework, protecting sensitive data across its lifecycle requires consistent anonymization and governance controls beyond basic access restrictions.
Organizations typically implement anonymization using custom SQL scripts, export pipelines, or transformation logic. These approaches lack consistency, are difficult to audit, and do not scale across environments. A more structured approach integrates centralized controls such as Data Discovery and Data Masking to ensure consistent handling of sensitive data across systems.
This article examines native anonymization techniques in Sybase, their limitations, and a centralized approach for consistent enforcement.
What is Data Anonymization in Sybase
Data anonymization is the process of transforming sensitive data so that it cannot be linked to an individual or entity. Unlike data masking, which obscures portions of data while keeping its structure intact, anonymization is irreversible. Once transformed, the original data cannot be reconstructed, making it ideal for environments where privacy and compliance are essential.
Anonymization ensures that even if the data is accessed or exposed, it cannot be traced back to its original source, reducing the risk of data breaches and unauthorized access to personal or confidential information. This makes it crucial for organizations that handle sensitive data and need to meet regulations such as GDPR, HIPAA, or PCI-DSS.
Typical anonymization targets include:
- Personally identifiable information (PII): Data such as names, addresses, and phone numbers.
- Financial records: Information about transactions, bank accounts, and credit cards.
- Healthcare data: Medical records and healthcare-related information.
- Authentication-related attributes: Usernames, passwords, and security answers.
The goal of data anonymization is to maintain the dataset’s structure and usability while eliminating exposure risks. This allows organizations to use data for testing, development, or analytics without compromising privacy. Data Discovery and Data Masking are key techniques used in this process to identify and protect sensitive information across various environments.
Anonymization is particularly useful in testing environments, where real data would violate compliance standards. It also plays a key role in data-sharing initiatives, enabling organizations to share data with third parties without risking privacy breaches.
As data is increasingly shared across cloud platforms, anonymization ensures that even if data is intercepted, it cannot be linked back to individuals or organizations.
Native Data Anonymization Techniques in Sybase
Sybase does not provide built-in anonymization features. As a result, organizations typically implement data anonymization using manual methods, which are often inconsistent, difficult to audit, and prone to human error. These approaches do not scale effectively across environments, making them less reliable for ensuring data privacy and compliance at an enterprise level.
SQL-Based Data Substitution
One of the most common techniques for anonymization is direct SQL-based data substitution. This method involves using update queries to replace sensitive information with anonymized or synthetic data.
For example:
UPDATE customers
SET email = 'user_' + CONVERT(VARCHAR, customer_id) + '@example.com',
phone = '0000000000';
This method modifies the production data or its copies directly. While it can be effective for small datasets, it requires careful coordination to ensure referential integrity and consistency across related tables. Additionally, this method is prone to errors due to its manual nature. If not implemented correctly, it can lead to data inconsistencies, which compromises its effectiveness.
Export and Transformation Pipelines
Another approach involves exporting data, transforming it externally, and then reloading it into the system. Typically, this process includes exporting data to an intermediate file, applying transformations using external tools or scripts, and then re-importing the modified data back into the system.
For example:
bcp mydb..customers out customers.dat -c -U user -P pass
After exporting the data, external scripts or tools are used to apply anonymization logic. However, this method introduces several risks:
- Sensitive data exposure: During export, sensitive data is often temporarily stored in raw form before being transformed.
- Lack of enforcement at the database level: Anonymization is only applied after the data is exported, leaving the data vulnerable to exposure during the export phase.
- Pipeline failures: If there’s a failure in the export or transformation pipeline, the anonymized data may not be correctly re-imported, leaving datasets only partially anonymized.
View-Based Obfuscation
Views are another method used for obfuscating sensitive data in Sybase. By creating a view that replaces sensitive information with generic values or masked data, organizations can attempt to obscure sensitive data when accessed through the view.
For example:
CREATE VIEW masked_customers AS
SELECT
customer_id,
'***' AS email,
'***' AS phone
FROM customers;
While views can provide some level of data obfuscation by displaying anonymized values instead of sensitive data, this method does not technically perform anonymization. The underlying data remains unchanged in the database, and it can still be accessed directly through queries that bypass the view. Therefore, this approach offers cosmetic masking but does not address the need for irreversible anonymization.
Centralized Data Anonymization with DataSunrise
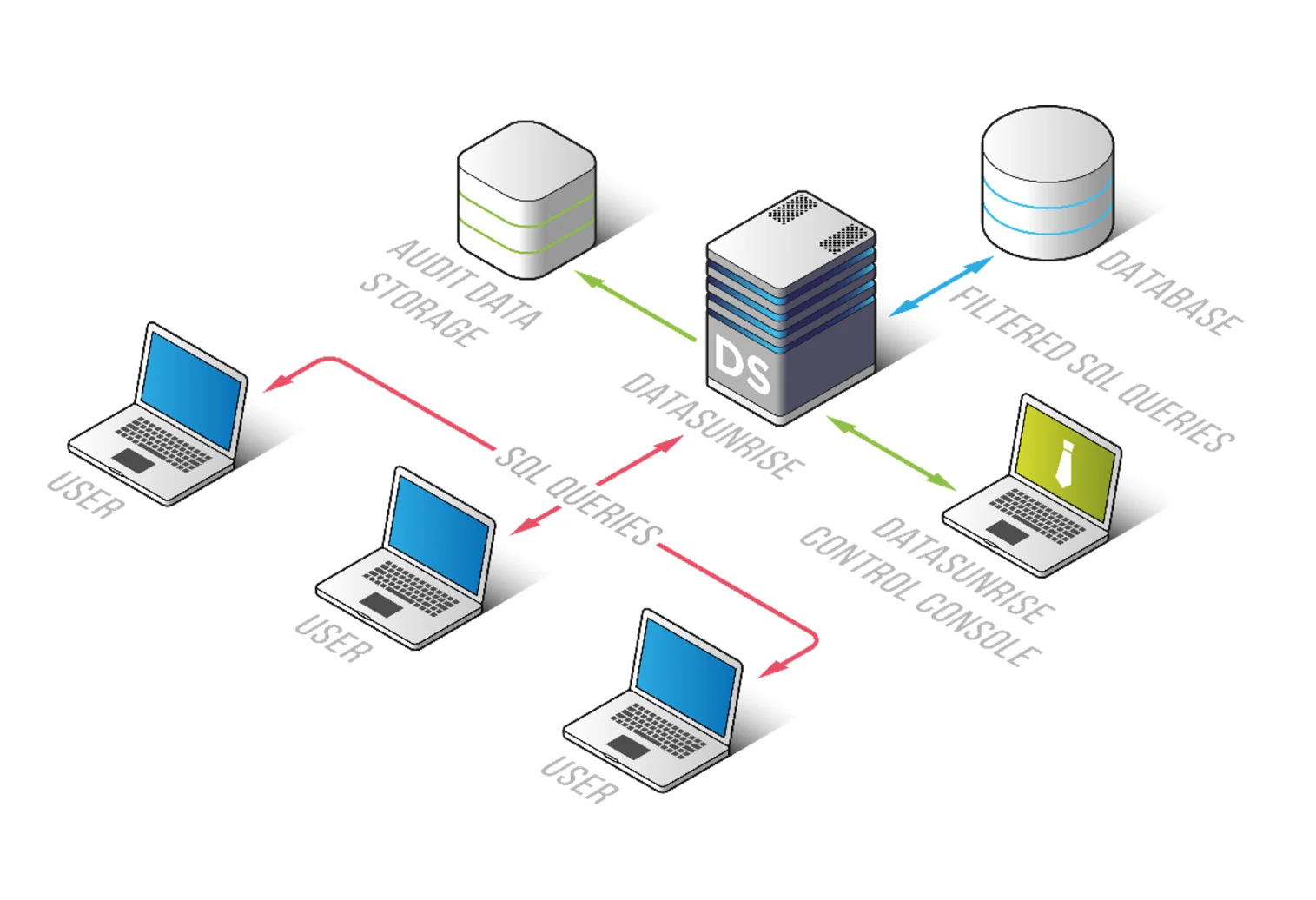
DataSunrise implements anonymization as an external control layer, independent of the database engine. This means that it operates outside the database system itself, ensuring that sensitive data is anonymized without requiring any modification to the underlying database schema. By using DataSunrise’s centralized framework, organizations can define, manage, and enforce anonymization policies across different environments.
DataSunrise enables organizations to handle sensitive data with consistent protection, regardless of where or how the data is accessed. It ensures that data anonymization is applied systematically and uniformly, reducing the risks associated with inconsistent or manual anonymization practices.
Automated Sensitive Data Identification
DataSunrise automatically detects sensitive data using advanced techniques such as Natural Language Processing (NLP), machine learning, and pattern recognition. This automated process identifies sensitive information across structured, semi-structured, and unstructured environments, ensuring no sensitive data is missed. This eliminates the need for manual tagging or identification, streamlining the process and reducing the risk of human error.
Policy-Based Anonymization Without Custom Scripting
DataSunrise enables organizations to define and enforce anonymization policies centrally, without the need for complex, custom SQL scripts. These policies are applied automatically across all relevant data, ensuring consistency and auditability. By centralizing policy management, DataSunrise removes the complexity of custom scripting and makes anonymization scalable and easier to maintain.
Support for Proxy, Sniffer, and Log-Based Deployment Modes
DataSunrise offers three flexible deployment modes to suit various organizational needs:
- Proxy Mode: All data access is routed through the DataSunrise proxy, where anonymization is applied in real-time, ensuring sensitive data is protected during access.
- Sniffer Mode: DataSunrise operates without modifying the database infrastructure by passively monitoring traffic to and from the database, applying anonymization where necessary.
- Log-Based Mode: Anonymization is applied to data based on activity logs, without the need to directly interact with the data at runtime.
These modes provide flexibility in deployment, allowing organizations to choose the most appropriate method for their environment.
Role-Based and Context-Aware Data Protection
DataSunrise applies anonymization based on user roles and the context of data requests. This ensures that different users, such as administrators, analysts, or support teams, have access to appropriate levels of data. For example, an analyst might see anonymized data, while an administrator can access full data. By enforcing anonymization based on the user’s role and data context, DataSunrise protects sensitive information without compromising workflow efficiency or access.
Unified Control Across Heterogeneous Environments
Whether data is stored in relational databases, NoSQL systems, or cloud platforms, DataSunrise provides a centralized control mechanism to ensure consistent anonymization across all environments. This unified approach simplifies management, ensuring that anonymization policies are enforced universally, regardless of the platform or data storage model. This centralized control is essential for organizations operating in complex, multi-platform environments, ensuring consistency and compliance across the entire infrastructure.
Business Impact of Data Anonymization in Sybase
| Impact | Description |
|---|---|
| Reduced Data Exposure | Sensitive data is removed from non-production environments, ensuring that data in development, testing, or analytics environments remains protected. Data Discovery and Data Masking technologies help automate this process. |
| Improved Compliance | Automated alignment with regulatory frameworks such as GDPR and HIPAA, ensuring that sensitive data is anonymized in compliance with laws and standards. |
| Operational Efficiency | Eliminates manual anonymization workflows by implementing policy-based automation. DataSunrise Compliance Manager provides a unified approach for managing data anonymization rules. |
| Consistency | Uniform policies are applied across all systems, reducing discrepancies between different environments. This is achieved through centralized policy management. |
| Audit Readiness | Full visibility into anonymization processes, providing clear audit trails and reports for regulatory audits. Audit Logs and Audit Trails offer comprehensive monitoring capabilities. |
Conclusion
Sybase provides foundational security controls but does not address anonymization requirements.
Native techniques—SQL updates, export pipelines, and views—are fragmented and lack enforcement. They do not provide consistency or scalability across environments. These methods are prone to errors and manual interventions, making them unreliable for comprehensive data protection.
A centralized anonymization model ensures controlled, repeatable, and auditable data transformation. This approach simplifies data management and ensures that sensitive information is protected consistently across environments.
DataSunrise implements this model through policy-driven anonymization, automated discovery, and unified enforcement. By leveraging Data Discovery, Data Masking, and Audit Logs, it reduces operational complexity while improving data protection. This centralized approach ensures that data anonymization is both scalable and compliant with regulatory requirements.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now