
Data Anonymization in TiDB
TiDB handles transactional workloads, analytics, and operational reporting in one distributed SQL platform, which is great for performance and collaboration, and a bit less charming when sensitive data starts wandering into places it never should. Developers want production-like test data. Analysts want realistic records. Support teams want direct access to troubleshoot issues. Soon enough, raw emails, phone numbers, identifiers, payment fields, and note columns begin showing up in lower environments and shared workflows.
That is where data masking and anonymization strategies become essential. In TiDB, anonymization is not a single feature. It is a set of controls and transformation methods that reduce the risk of exposing real personal or regulated data while preserving enough utility for testing, analytics, or support operations. A good anonymization program usually starts with data discovery, classification of PII, and a clear decision about which fields must be transformed, hidden, generalized, or replaced.
This guide explains how anonymization works in TiDB, which techniques are most useful, and how DataSunrise can help enforce them across live queries and copied datasets. For deeper background on the database engine itself, the official TiDB GitHub repository is a useful companion.
Where anonymization fits in the TiDB data lifecycle
TiDB teams usually need anonymization in three places:
- Live query protection for support tools, analytics platforms, and shared SQL access. This is where dynamic masking helps.
- Copied environments such as QA, development, training, and vendor testing. This is where static masking usually makes more sense.
- Special-case transformations when teams intentionally change stored values directly, which is where in-place masking may apply in controlled scenarios.
A sensible program maps these use cases to internal policies and data compliance regulations before anyone starts writing rules. That step is less glamorous than clicking buttons in a UI, but it saves a lot of misery later.
Start with the fields that create the highest operational and compliance risk—contact data, national identifiers, payment fields, addresses, and free-text notes—then validate the anonymized result with the same SQL tools, ETL jobs, and dashboards your teams already use.
Techniques that work in real TiDB datasets
Not every column should be transformed the same way. Some fields need full redaction. Others work better with pattern-preserving substitution, generalization, or deterministic anonymization that keeps multi-table relationships intact. DataSunrise documents a broad range of masking techniques, but the right technique still depends on the business purpose of the target dataset.
| Field Type | Recommended Technique | Why It Works |
|---|---|---|
| Pattern-preserving anonymization | Keeps a realistic shape while removing the real address | |
| Phone | Template-based replacement | Preserves formatting for tests and interfaces |
| National ID | Full redaction or irreversible substitution | Blocks direct exposure of highly sensitive identity data |
| Card Number | Format-preserving masking | Keeps structure for validation without leaking payment details |
| Address | Generalization or substitution | Retains location logic while lowering privacy risk |
| Notes | Conditional masking | Protects sensitive fragments hidden inside free text |
| Cross-table keys | Deterministic replacement | Preserves referential consistency across related records |
Applying anonymization with DataSunrise in TiDB
A practical anonymization workflow in TiDB is not complicated. You identify the sensitive objects, assign masking methods to the risky columns, run the transformation through the right control path, and verify the output. What matters is discipline: teams need consistent selection criteria, repeatable methods, and evidence that the rule actually executed.
The screenshot below shows a column-level masking setup for the table ds_masking_demo. In this example, the email field already has a configured method, while other columns remain available for additional treatment. That is how real projects usually begin—not with perfect coverage, but with a focused pass over the highest-risk fields.
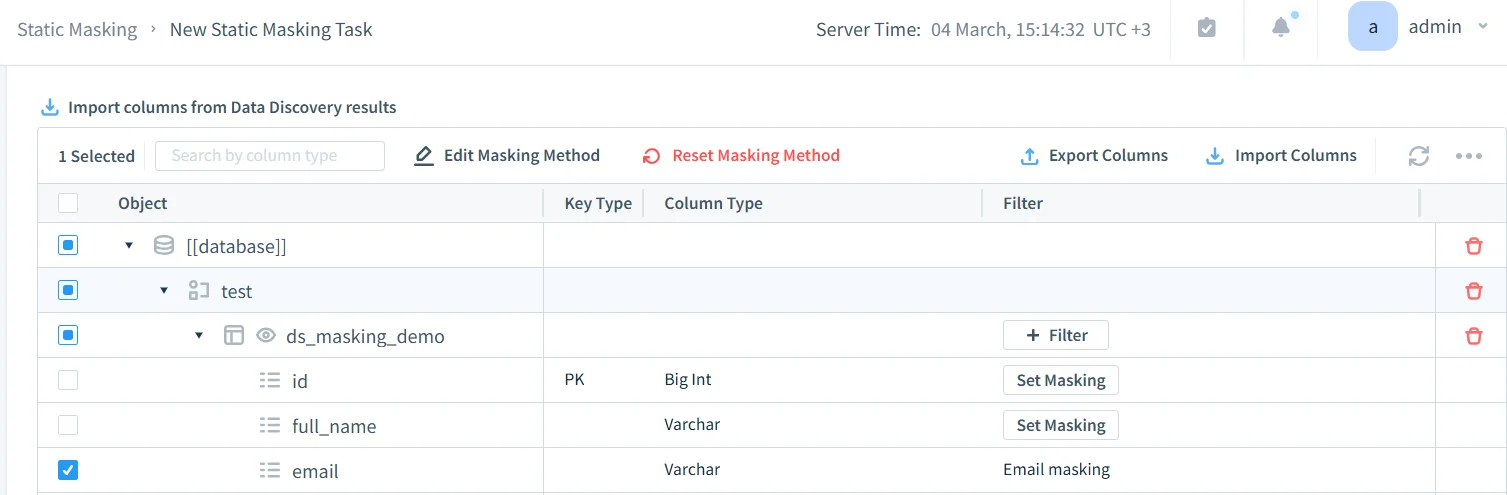
At this stage, it helps to connect anonymization to operational visibility. Teams often pair these controls with database activity monitoring, detailed audit logs, and a defensible audit trail. If your process needs formal review and sign-off, the audit guide is a useful reference for structuring approvals and checks.
Before running the job, review the selected fields one more time. It sounds obvious, but this is where teams catch the things that hurt later: missed note columns, identity fields that should have been fully anonymized, or linked keys that need deterministic treatment rather than random replacement.
How to validate anonymized TiDB output
Validation is where theory meets reality. A rule can execute perfectly and still fail the project if the transformed values break joins, filters, application logic, or reporting outputs. That is why teams should test anonymized results with real SQL, real dashboards, real ETL jobs, and real downstream scripts instead of one cheerful screenshot in the admin console.
A simple validation query can be enough to confirm whether protected fields still behave correctly:
SELECT
id,
full_name,
email,
phone,
national_id,
card_number,
card_exp,
address_line,
ip_addr,
notes,
created_at
FROM testv2.ds_masking_demo;
The result below shows a practical anonymization outcome. Email values are heavily transformed while other columns remain available for the testing workflow. That balance is the whole point: keep the data usable, but stop exposing the raw version everywhere.

An anonymization project can still fail even when the transformation job completes successfully. If the protected output breaks business logic or still allows easy re-identification, teams will either bypass the dataset or ship a weak control into production. Test both utility and privacy risk before declaring the rollout finished.
Supporting controls that make anonymization stronger
Field-level transformation works best when it sits inside a broader security model. The security guide helps frame anonymization as part of an overall protection strategy rather than an isolated feature. Teams also strengthen their query paths with a database firewall, targeted security rules against SQL injections, and periodic vulnerability assessment checks. That matters because one weak access route can undo a lot of otherwise careful masking work.
At scale, governance matters just as much. DataSunrise can feed evidence into Compliance Manager and extend the same operating model across many supported data platforms. That is how anonymization becomes part of a repeatable database security program instead of a pile of inconsistent one-off rules.
Why anonymization supports compliance in TiDB
| Framework | Typical TiDB Risk | Anonymization Outcome |
|---|---|---|
| GDPR | Personal data appears in support tools, copied datasets, and analytics outputs | Supports data minimization and controlled disclosure |
| HIPAA | Healthcare-related records spread into non-clinical workflows | Reduces unnecessary visibility of protected data |
| PCI DSS | Payment details leak into copied systems or shared query results | Restricts exposure of cardholder data |
| SOX | Financial records become too broadly available across reporting and testing access | Improves accountability and controlled handling |
Conclusion
Data anonymization in TiDB is not about making data look prettier or ticking a compliance checkbox. It is about reducing the chance that live queries, copied datasets, and downstream workflows keep exposing real sensitive values long after the original application finished with them. The process is manageable: discover the risky fields, choose the right transformation for each one, enforce it consistently, and validate the result against real usage.
With the right DataSunrise controls in place, teams can protect high-risk fields without destroying the value of the dataset itself. That is the real win: useful data, lower exposure, stronger evidence, and far fewer opportunities for somebody to do something spectacularly reckless with production truth.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now