Data Obfuscation in Amazon OpenSearch
Data obfuscation in Amazon OpenSearch stops being a “nice-to-have” the moment your cluster stops being “just logs.” OpenSearch indexes are packed with observability payloads, security events, and application traces—exactly the places where emails, phone numbers, IP addresses, and IDs love to quietly appear. If you don’t plan for data obfuscation in Amazon OpenSearch, you’re basically volunteering to leak sensitive fields through dashboards, ad hoc searches, and incident-response queries.
AWS delivers the managed platform for Amazon OpenSearch Service, but the responsibility for protecting regulated data still belongs to the organization operating the cluster. Obfuscation gives you a practical middle ground: OpenSearch stays usable for search, analytics, and investigations, while sensitive values are protected at the point users actually see them—query results.
What “Sensitive Data” Looks Like in OpenSearch Indices
OpenSearch rarely stores neat, well-modeled tables. It stores documents—often semi-structured JSON—and those documents frequently contain regulated fields. Typical examples include:
- Customer identifiers and account IDs embedded in payloads
- Email addresses, phone numbers, and names (PII)
- IP addresses and device identifiers tied to individual users
- Authentication events, session metadata, and access logs
- Support notes, internal comments, and error messages with user context
Because documents can evolve over time (new fields appear, nested objects grow, pipelines change), protection can’t depend on a one-time review. Obfuscation should be policy-driven and continuously enforced—not a spreadsheet exercise you revisit once a year.
Why Data Obfuscation Is a Compliance Control, Not a Cosmetic Feature
Teams often assume that access controls alone solve the problem. They don’t. Authorization determines who can query an index. Obfuscation determines what they can actually see in the returned data. That distinction matters when your cluster falls under data compliance regulations such as GDPR, HIPAA, PCI DSS, or internal control frameworks like SOX compliance.
A defensible approach to data obfuscation in Amazon OpenSearch should support:
- Least-visibility for broad-read roles (dashboards, investigations, analytics)
- Consistent enforcement across environments and access paths
- Audit-ready evidence proving what policy was applied and when
Obfuscation Techniques That Work in Search Workloads
Obfuscation is an umbrella term. In search and analytics systems like OpenSearch, the most practical techniques are the ones that preserve usability (search relevance, aggregations, investigations) while reducing exposure. The table below maps common approaches to OpenSearch realities.
| Technique | Where it’s applied | What users see | Best fit in OpenSearch |
|---|---|---|---|
| Dynamic masking | Query time (results layer) | Obfuscated values based on policy/role | Dashboards, SOC searches, broad-read analytics users |
| Partial masking | Query time (results layer) | Only a safe portion revealed (e.g., last 4) | Triage workflows where context matters but full values don’t |
| Field suppression | Query time (results layer) | Field removed or nulled for unauthorized roles | High-risk fields like SSNs, card-like values, tokens |
| Ingestion-side redaction | Before indexing | Sensitive data never lands in the cluster | Secrets and credentials you never want searchable |
From a governance standpoint, dynamic methods are usually the fastest win because you can protect production access paths without rebuilding pipelines or reindexing data. This is the core idea behind dynamic data masking and broader data masking strategies: enforce visibility rules at the moment of access.
Architecture: Enforce Obfuscation Where Queries Actually Flow
Effective obfuscation depends on one non-negotiable reality: queries must pass through the control point. If users (or apps) can hit OpenSearch directly, they can bypass protection. That’s why many teams implement a dedicated policy enforcement layer using flexible deployment modes that fit different OpenSearch topologies.
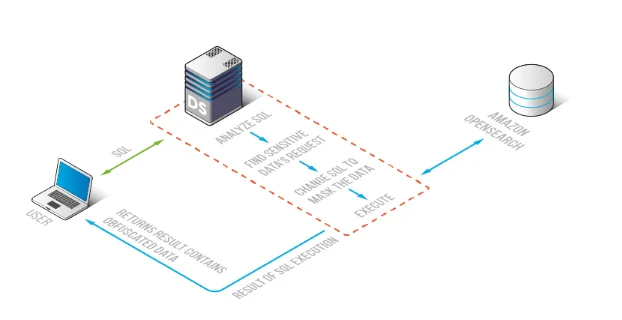
A typical architecture: DataSunrise enforces data obfuscation policies between users and Amazon OpenSearch, so results are protected before they reach clients.
This enforcement-layer approach pairs naturally with governance requirements: you can apply policy consistently, centralize evidence, and avoid relying on every dashboard or script to “do the right thing.”
Step 1: Discover What Must Be Obfuscated
You can’t protect what you haven’t identified. OpenSearch often stores sensitive values inside nested JSON, free-text message fields, and semi-structured payloads—exactly where manual reviews fail. Start with automated data discovery to build a live inventory of sensitive fields and high-risk patterns across indices.
Discovery outputs are not just “nice visibility.” They drive policy scope, reduce blind spots, and help explain to auditors exactly what data was in scope and why.
Step 2: Design Role-Based Visibility Rules
Obfuscation works best when it’s role-aware and consistent across environments. OpenSearch clusters typically serve multiple groups—SREs, security analysts, developers, and support teams—and each group needs different visibility. Build governance rules around:
- Role-based access control (RBAC) for predictable policy mapping
- Centralized access controls so environments don’t drift
- Principle of least privilege applied to data visibility, not just endpoints
Visibility rules are where most implementations win or lose. If policies are too strict, teams bypass them. If they’re too loose, you’re back where you started.
Step 3: Configure Dynamic Obfuscation Rules
Once sensitive fields are known and roles are defined, configure dynamic rules that apply obfuscation methods to specific fields. This is where you decide what “protected” looks like: full redaction, partial reveal, or controlled transformation—based on role and data type. If multiple rules can apply, keep outcomes deterministic using rules priority.
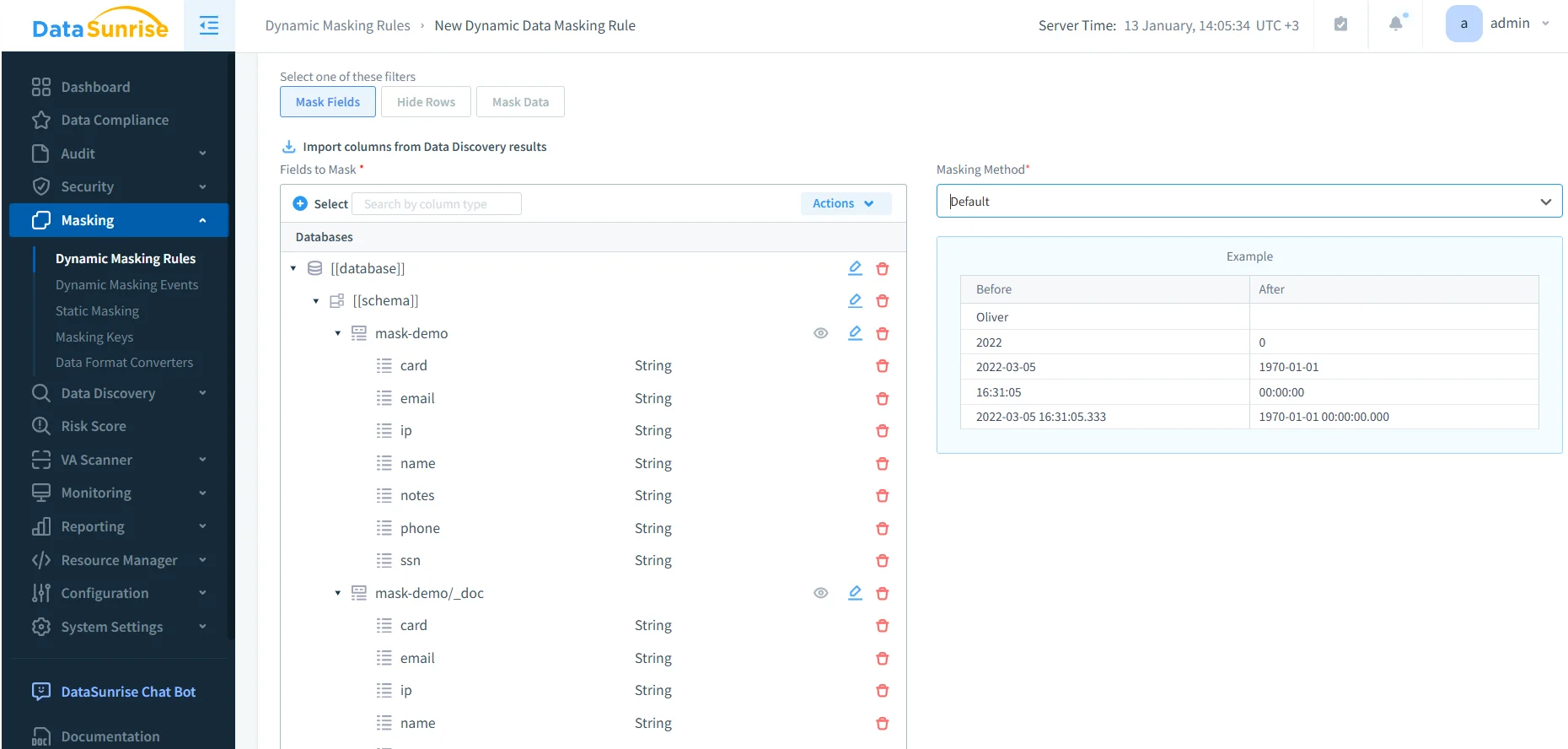
Defining a dynamic masking rule: select sensitive fields discovered in OpenSearch and apply an obfuscation method for controlled query results.
Practical guidance:
- Start with high-risk fields: emails, phones, IPs, SSNs, and card-like strings.
- Preserve operational meaning: partial masking is often enough for troubleshooting without exposing full identifiers.
- Scope before you expand: protect the indices that contain regulated data first, then widen coverage as you validate impact.
Step 4: Make It Audit-Proof
Obfuscation without evidence is a future audit finding. You need to prove what happened: who queried what, which rule applied, and whether protected values were returned. Centralized evidence typically includes:
- Data Audit controls for governed activity tracking
- Structured audit logs for investigations and reviews
- Immutable audit trails for accountability
- Continuous database activity monitoring to detect abnormal access patterns
AWS also provides service-side logging for baseline visibility: Amazon OpenSearch audit logs. However, many organizations prefer centralized evidence so reporting is consistent across environments and query paths.
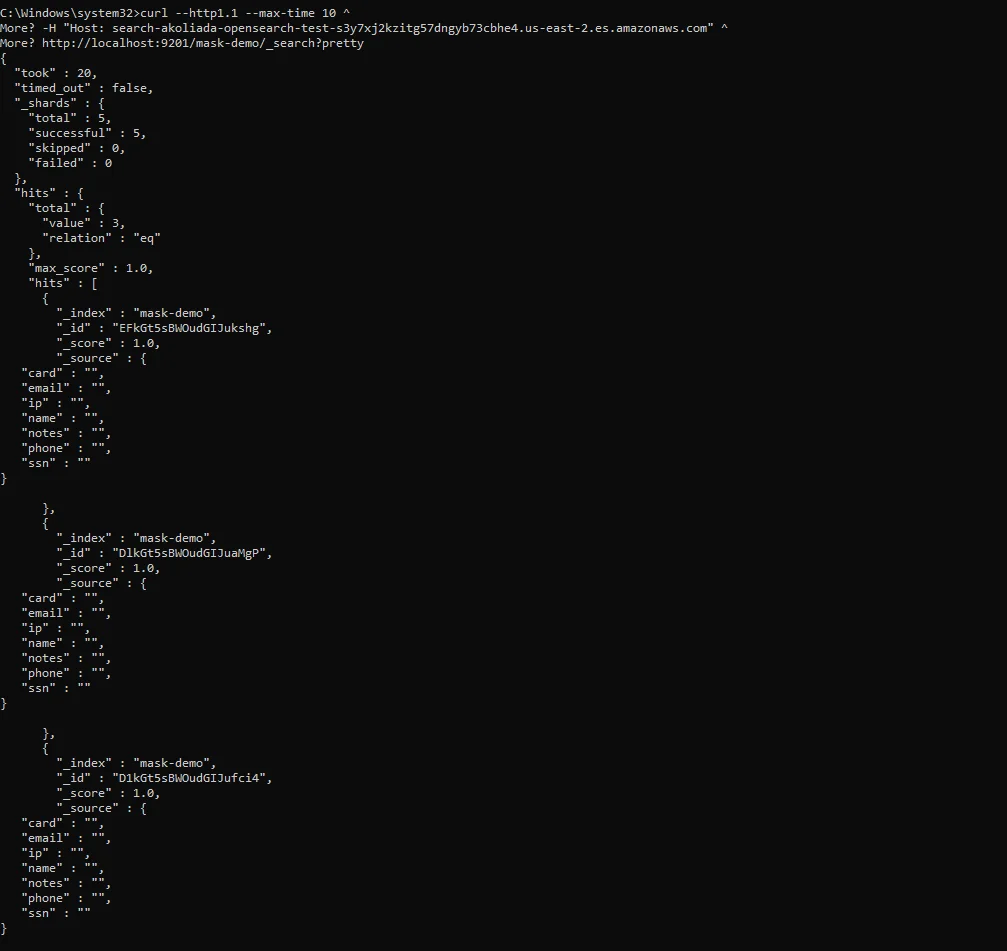
Hardening: Don’t Let Obfuscation Become Your Only Safety Net
Obfuscation reduces exposure, but it’s not a complete security strategy. Real protection combines visibility controls with preventive security guardrails, including:
- Database firewall controls to block abusive access patterns
- Vulnerability assessment to catch configuration drift and security gaps
- Continuous data protection so controls stay effective as indices change
- User behavior analysis to detect anomalous usage beyond allow/deny logic
- Aligned database security policy enforcement across the stack
This is also where automation matters: governance should not depend on human memory. Using Compliance Manager with structured reporting via report generation, teams can turn protection into a continuous control rather than a scramble before audits.
Treat OpenSearch “message” fields and nested JSON as primary sensitive-data carriers. Discover them continuously, then apply dynamic obfuscation to the highest-risk fields first (email, phone, IP, SSN-like values).
Obfuscation is not permission to index secrets. API keys, session tokens, passwords, and private keys should be blocked or stripped at ingestion—because searchable secrets are an exfiltration shortcut.
Conclusion: Make Obfuscation a Quiet, Always-On Control
The goal of data obfuscation in Amazon OpenSearch is not to “hide everything.” It’s to keep OpenSearch functional for search and analytics while preventing raw sensitive values from being exposed to broad-read users and tools. The defensible pattern is consistent: discover sensitive fields, apply role-aware dynamic obfuscation, validate results, and keep audit evidence always on.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now