Sensitive Data Protection in Elasticsearch
Protecting sensitive information has become a fundamental requirement for organizations that rely on search and analytics platforms. Elasticsearch frequently stores customer records, financial transactions, healthcare data, application logs, and operational metrics that may contain personally identifiable information (PII), protected health information (PHI), payment card data, or confidential business records. Without proper controls, this information can be exposed through search queries, dashboards, APIs, or administrative operations.
Sensitive Data Protection in Elasticsearch combines access controls, document filtering, field restrictions, and encryption to reduce the risk of unauthorized disclosure while supporting regulatory compliance. Proper protection also helps organizations satisfy requirements established by GDPR, HIPAA, PCI DSS, SOX, CCPA, and other security frameworks.
Elasticsearch provides several native security capabilities that help organizations restrict access to sensitive information. These include field-level security, document-level security, role-based access control, ingest pipelines, runtime fields, encryption, and audit logging. While these features create a solid security foundation, managing them across multiple clusters, cloud environments, and evolving compliance requirements often becomes increasingly complex. Elastic provides detailed documentation on its security capabilities and the available Security APIs for implementing these controls.
This article explores Elasticsearch's built-in sensitive data protection capabilities and demonstrates how DataSunrise extends them through centralized policy management, intelligent automation, sensitive data discovery, compliance orchestration, and enterprise-scale protection.
What is Sensitive Data Protection in Elasticsearch?
Sensitive Data Protection refers to the technologies and security controls used to prevent unauthorized users from viewing, modifying, or exporting confidential information stored within Elasticsearch indices.
Depending on business requirements, protected information may include:
- Personally Identifiable Information (PII)
- Protected Health Information (PHI)
- Financial records
- Payment card information
- Employee records
- Customer credentials
- Business-sensitive operational data
- Intellectual property
Effective protection combines multiple security layers rather than relying on a single mechanism. Elasticsearch provides native capabilities that help organizations:
- Restrict access to specific users
- Limit visibility of sensitive fields
- Filter confidential documents
- Protect communication channels
- Monitor access attempts
- Generate audit records
- Encrypt stored data
Each capability addresses a different aspect of data protection, allowing administrators to build layered security models that follow the principle of least privilege.
Native Elasticsearch Sensitive Data Protection
Modern Elasticsearch deployments typically rely on several built-in security features to protect sensitive information from unauthorized access and accidental exposure. Rather than depending on a single mechanism, Elasticsearch uses multiple layers of security that work together to safeguard data throughout its lifecycle.
The primary native capabilities include Field-Level Security (FLS), Document-Level Security (DLS), Role-Based Access Control (RBAC), ingest pipelines, runtime fields, TLS encryption, and audit logging. Combined, these features help organizations restrict access, protect confidential information, and support regulatory compliance while allowing authorized users to continue working with the data they need.
Field-Level Security
Field-Level Security (FLS) controls which document fields individual users or roles are allowed to view. Instead of exposing an entire document, Elasticsearch can selectively hide fields that contain confidential information such as Social Security numbers, bank account details, or personal identifiers.
The following example grants HR personnel access only to selected employee fields while excluding highly sensitive information:
POST /_security/role/hr_viewer
{
"indices": [
{
"names": ["employees"],
"privileges": ["read"],
"field_security": {
"grant": [
"employee_id",
"department",
"position",
"salary_band"
],
"except": [
"ssn",
"passport_number",
"bank_account"
]
}
}
]
}
In this configuration, HR users can view general employee information while identification numbers and banking details remain hidden.
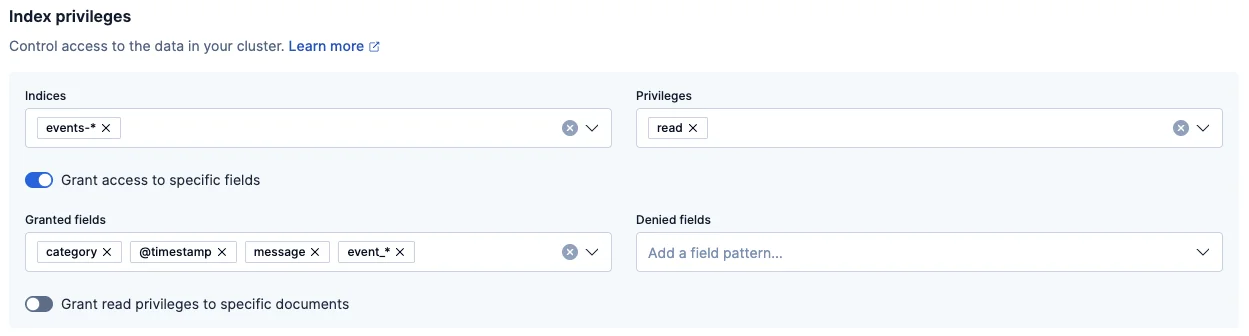
Field-Level Security offers several advantages. It provides granular control over individual fields, integrates directly with Elasticsearch's native security model, remains transparent to client applications, and supports least-privilege access policies. However, organizations with large deployments may encounter challenges because field permissions require manual configuration, role management becomes increasingly complex as environments grow, and Elasticsearch does not automatically identify sensitive fields that should be protected.
Document-Level Security
Document-Level Security (DLS) restricts access to entire documents instead of individual fields. Elasticsearch evaluates a security query before returning search results, ensuring users can retrieve only documents that satisfy predefined access conditions.
The following role limits users to documents belonging only to the EMEA region:
POST /_security/role/finance_team
{
"indices": [
{
"names": ["transactions"],
"privileges": ["read"],
"query": {
"term": {
"region": "EMEA"
}
}
}
]
}
This capability is particularly useful for organizations that need to separate information based on departments, geographic regions, business units, customers, or tenants. For example, employees assigned to the European division may be permitted to search only documents associated with the EMEA region, while users in North America receive results exclusively from their own region.
By filtering documents before they reach users, Document-Level Security significantly reduces the risk of unauthorized information disclosure. Nevertheless, managing complex security queries across numerous indices and user roles can become increasingly difficult as Elasticsearch environments expand.
Role-Based Access Control
Role-Based Access Control (RBAC) serves as the foundation of Elasticsearch authorization. Rather than assigning permissions individually to every user, administrators define reusable roles that specify which cluster operations, index privileges, and management functions are permitted.
The example below creates a security analyst role with monitoring capabilities and read-only access to log indices:
POST /_security/role/security_analyst
{
"cluster": [
"monitor"
],
"indices": [
{
"names": [
"logs-*"
],
"privileges": [
"read",
"view_index_metadata"
]
}
]
}
Using RBAC, organizations can control access to search operations, document updates, index administration, cluster monitoring, snapshot management, and Elasticsearch APIs. When combined with Field-Level Security and Document-Level Security, RBAC enables organizations to implement comprehensive least-privilege security models across their Elasticsearch infrastructure.
Although RBAC provides flexible permission management, enterprise environments frequently require hundreds of specialized roles. Maintaining consistent permissions across multiple clusters, cloud deployments, and development environments often requires significant administrative effort.
Ingest Pipelines
Elasticsearch ingest pipelines process incoming documents before they are indexed. During ingestion, administrators can remove, rename, transform, or enrich document fields to reduce the amount of sensitive information stored within Elasticsearch.
The following ingest pipeline automatically removes payment card information before documents are indexed:
PUT _ingest/pipeline/remove_sensitive_fields
{
"processors": [
{
"remove": {
"field": [
"credit_card",
"cvv"
]
}
}
]
}
Organizations commonly use ingest pipelines to delete payment card numbers, remove authentication credentials, standardize personal information, or transform confidential values before indexing occurs. Since these modifications happen automatically during data ingestion, applications do not require additional changes.
While ingest pipelines effectively protect newly indexed information, they do not automatically secure documents that already exist inside Elasticsearch indices. Historical data typically requires separate remediation or reindexing processes.
Runtime Fields
Runtime fields provide another method for protecting sensitive information by calculating values dynamically during query execution instead of modifying the original indexed documents. This approach allows organizations to present masked or transformed information while preserving the underlying data.
The following runtime field masks email addresses while keeping the original value stored in the index:
PUT employees/_mapping
{
"runtime": {
"masked_email": {
"type": "keyword",
"script": {
"source": """
emit(
doc['email'].value.replaceAll(
'(^.).+(@.*$)',
'$1****$2'
)
);
"""
}
}
}
}
Applications can query the masked_email field instead of exposing the original email address to end users.
Runtime fields offer considerable flexibility for presentation-layer masking and reporting. However, since values are calculated during every search request, extensive use of runtime fields may increase query latency compared to pre-indexed data.
How DataSunrise Enhances Sensitive Data Protection in Elasticsearch
DataSunrise deploys Zero-Touch Data Masking to deliver seamless protection with minimal administrative effort. Through flexible deployment modes and non-intrusive integration, organizations can secure Elasticsearch without modifying applications, changing client behavior, or redesigning existing workflows.
Unlike solutions that require continuous manual tuning, DataSunrise combines Compliance Autopilot, Automatic Policy Generation, Sensitive Data Discovery, Continuous Regulatory Calibration, and Machine Learning Audit Rules into a centralized security platform that continuously adapts to changing environments.
The platform protects structured, semi-structured, and unstructured information while extending governance beyond Elasticsearch to databases, data warehouses, cloud storage, file systems, and hybrid infrastructures.
Zero-Touch Data Masking
Protecting sensitive information often requires more than the native masking capabilities available in Elasticsearch. Instead of relying on individually configured runtime fields or application-side masking, DataSunrise applies masking policies automatically through a centralized management layer.
Security teams define masking policies once and consistently enforce them across Elasticsearch clusters, ensuring confidential information remains protected regardless of where it resides. DataSunrise supports masking for personally identifiable information, financial records, authentication credentials, healthcare information, customer identifiers, and other business-sensitive attributes.
This centralized approach eliminates the need to modify applications, simplifies policy administration, supports dynamic masking during query execution, enables fine-grained access controls, and significantly reduces administrative overhead while maintaining consistent security across the environment.
Sensitive Data Discovery
One of the most difficult aspects of protecting Elasticsearch environments is identifying where sensitive information is actually stored. As clusters grow and new indices are created, manually locating confidential data quickly becomes impractical.
DataSunrise addresses this challenge through automated Sensitive Data Discovery, continuously scanning Elasticsearch indices to identify sensitive information before protection policies are applied. The discovery engine detects personally identifiable information (PII), protected health information (PHI), payment card data, financial records, national identifiers, and custom business-specific patterns.
Unlike manual classification processes, automated discovery significantly reduces the risk of forgotten indices, newly created datasets, or previously unidentified sensitive fields remaining unprotected.
Compliance Autopilot
Modern compliance requirements change frequently, making manual policy management increasingly difficult for security teams responsible for large Elasticsearch environments.
DataSunrise simplifies regulatory compliance through Compliance Autopilot, automatically aligning security controls with frameworks including GDPR, HIPAA, PCI DSS, SOX, CCPA, ISO 27001, and SOC 2. Instead of manually mapping security policies to every regulation, organizations can automatically generate compliance-oriented configurations while reducing operational effort and improving consistency.
This automated approach accelerates audit preparation while helping organizations maintain continuous regulatory alignment.
Automatic Policy Generation
Enterprise Elasticsearch deployments often contain hundreds or even thousands of indices, making manual policy creation time-consuming and error-prone.
DataSunrise streamlines this process through Automatic Policy Generation, creating protection policies based on discovered sensitive information, predefined compliance templates, and organizational security requirements. Newly discovered data can automatically inherit appropriate protection rules without requiring administrators to configure every index individually.
By automating policy creation, organizations accelerate deployments, reduce configuration errors, and maintain consistent protection as Elasticsearch infrastructures continue to expand.
Continuous Regulatory Calibration
Security and compliance requirements rarely remain static. New regulations, schema modifications, and changing business requirements continually introduce new protection challenges.
DataSunrise addresses this through Continuous Regulatory Calibration, continuously evaluating existing protection policies against newly discovered sensitive information and evolving compliance requirements. Periodic discovery tasks automatically identify newly created indices, schema modifications, additional sensitive fields, and emerging compliance gaps.
This ongoing validation minimizes regulatory drift, reduces manual audits, and helps organizations maintain a consistent security posture over time.
Machine Learning Audit Rules
Traditional security policies rely primarily on predefined conditions and manually created rules. While effective for known threats, static rules may overlook previously unseen attack patterns.
DataSunrise enhances threat detection through Machine Learning Audit Rules, enabling intelligent analysis of database activity to identify suspicious access behavior. The platform can detect unusual search frequencies, excessive document exports, abnormal access locations, privilege misuse, and unexpected access to confidential Elasticsearch indices.
Machine learning continuously improves detection accuracy by adapting to normal user behavior, reducing false positives while increasing the likelihood of identifying insider threats, compromised accounts, and unauthorized data collection.
Centralized Policy Management
Many organizations operate multiple Elasticsearch clusters across development, testing, staging, production, and cloud environments. Managing security independently within each deployment often leads to inconsistent policies and increased administrative complexity.
DataSunrise provides a centralized management platform for masking policies, sensitive data discovery tasks, audit rules, compliance reporting, security policies, and user access controls. Administrators can manage protection across all Elasticsearch environments from a single interface instead of configuring each cluster separately.
Centralized governance simplifies administration while improving consistency, visibility, and operational efficiency.
Cloud, On-Premises, and Hybrid Support
Modern enterprises rarely deploy Elasticsearch in a single infrastructure. Many organizations operate a combination of on-premises clusters, private cloud platforms, public cloud services, and hybrid architectures.
DataSunrise provides consistent protection across on-premises deployments, private clouds, public cloud environments, multi-cloud architectures, and hybrid infrastructures. Security policies remain synchronized regardless of where Elasticsearch workloads operate, allowing organizations to maintain unified governance without introducing additional operational complexity.
Native Elasticsearch vs DataSunrise Sensitive Data Protection
| Feature | Native Elasticsearch | DataSunrise |
|---|---|---|
| Sensitive Data Discovery | Manual identification | Automated discovery of sensitive data |
| Data Protection | FLS, DLS, RBAC, runtime fields | Zero-Touch Data Masking with centralized policies |
| Compliance | Manual policy management | Compliance Autopilot with automatic policy generation |
| Threat Detection | Native audit logs | Machine Learning Audit Rules and anomaly detection |
| Management | Per-cluster administration | Centralized management across cloud, on-premises, and hybrid environments |
Conclusion
Elasticsearch provides a strong foundation for protecting sensitive information through Field-Level Security, Document-Level Security, Role-Based Access Control, ingest pipelines, runtime fields, encryption, and audit logging. These native capabilities help organizations restrict access to confidential data and establish an effective baseline for security.
However, enterprise environments often require more than manual security configuration. As Elasticsearch deployments expand, organizations need automated sensitive data discovery, centralized policy management, intelligent compliance automation, and continuous monitoring to maintain consistent protection while reducing administrative effort.
DataSunrise enhances Elasticsearch with Zero-Touch Data Masking, Compliance Autopilot, Automatic Policy Generation, Continuous Regulatory Calibration, and Machine Learning Audit Rules. Through centralized governance, organizations can simplify regulatory compliance, strengthen data masking, improve database activity monitoring, and enforce consistent security policies across cloud, on-premises, and hybrid environments.
Learn more about DataSunrise's Database Firewall capabilities, or schedule a live demo to see how DataSunrise strengthens sensitive data protection for Elasticsearch.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now