
Data Anonymization in Amazon Athena
Amazon Athena is brilliant at making data in S3 immediately useful. Analysts can query it, support teams can inspect it, and engineers can feed it into notebooks or reports without building much infrastructure first. That same convenience is also what makes privacy mistakes easy. Once a lake becomes operationally valuable, raw emails, IP addresses, account identifiers, and note fields tend to appear in places where nobody originally intended them to travel.
That is where anonymization enters the picture. In strict privacy language, anonymization implies that data can no longer be tied back to a real person in any practical way. In day-to-day database operations, teams often use the term more broadly for protected outputs that are masked, de-identified, generalized, or otherwise transformed enough for analytics and testing. A practical Athena rollout usually starts with data discovery, classification of Personally Identifiable Information (PII), and a clear decision about which fields require stronger treatment than ordinary data masking.
That decision should never live in isolation. The same program also needs access controls, role-based access control, and the principle of least privilege. Those controls decide who can query Athena. Anonymization decides what version of the value they should receive once the query is allowed to run.
The Core Challenge with Data Anonymization in Amazon Athena
Athena sits in an awkward but common position. It is easy enough for broad business use, but powerful enough to expose highly sensitive data with a perfectly ordinary SQL statement. That creates three familiar problems.
- Live query exposure. Analysts and support engineers need production-like visibility, but not always the raw value. This is where dynamic masking and runtime anonymization are most useful.
- Copied data drift. Once Athena results are exported into dev, QA, or training datasets, the risk changes. That is where static masking and stronger irreversible transformations usually make more sense.
- Utility pressure. Teams still need the data to work. In some cases, realistic but non-real values generated through synthetic data generation are a better fit than partial reveal.
In other words, anonymization in Athena is less about picking a buzzword and more about matching the transformation to the workload. A support view may only need a recognizable email pattern. A lower-environment dataset may need stronger de-identification. A shared analytics layer may need a consistent runtime policy that balances privacy and usability.
Start with the columns that create the highest combination of privacy risk and operational visibility: email, phone number, IP address, account ID, payment references, and free-text notes. Those are usually the fields most likely to spread from Athena into exports, dashboards, notebooks, and shared reporting.
Technical Solutions: Query-Level and Policy-Based Anonymization
There is no single anonymization technique that fits every Athena workflow. Most teams end up using a mix of native SQL transformations, controlled views, and policy-based masking for live access. The articles on data masking for Amazon Athena, dynamic masking for Amazon Athena, and the step-by-step guide to masking data for Amazon Athena all point to the same practical truth: Athena protection works best when query-time transformation and governance stay close together.
| Technique | Best Fit | What It Preserves | Main Trade-Off |
|---|---|---|---|
| Partial masking | Live SQL results and support workflows | Pattern recognition | May be too weak for copied datasets |
| Deterministic replacement | Cross-table joins and repeated identifiers | Referential consistency | Needs careful key handling |
| Generalization | Location, demographic, and reporting fields | Trend analysis | Reduces analytical precision |
| Irreversible anonymization | Non-production copies and vendor sharing | Privacy strength | Often removes operational detail |
For small scopes, Athena teams often begin with SQL itself. An inline transformation can be enough when the goal is to preserve shape without disclosing the original value in full.
SELECT
id,
first_name,
last_name,
CONCAT(SUBSTR(email, 1, 2), '****', SUBSTR(email, -4)) AS anonymized_email,
REGEXP_REPLACE(ip_address, '(\\d+)\\.(\\d+)\\.(\\d+)\\.(\\d+)', '$1.$2.XXX.XXX') AS anonymized_ip
FROM danielarticletable;
That approach works, especially when combined with Athena views so users query a protected logical layer rather than the raw table directly. For stricter per-user exposure boundaries, Lake Formation data filtering can enforce column-, row-, and cell-level restrictions. The limitation is not capability so much as scale. Once many users, tools, and environments depend on the same protected logic, manually repeated SQL becomes fragile.
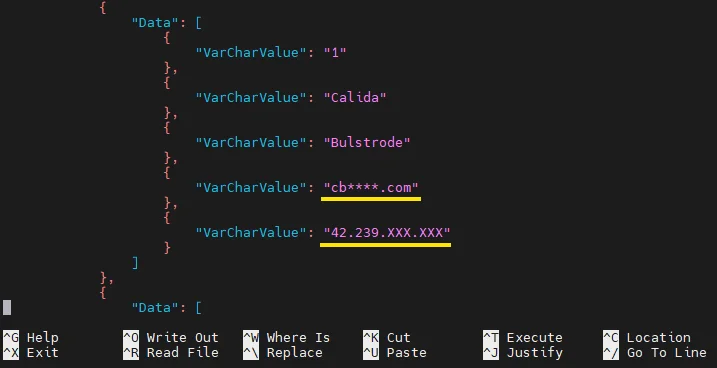
For downstream processing, many teams add a second safety layer before writing Athena results into files or DataFrames. That is especially useful for test data management workflows and broader data-driven testing, where protected outputs need to remain useful outside the original query console. Strong anonymization only helps if it survives the trip from SQL result to the rest of the workflow.
import re
from typing import Dict
def anonymize_row(row: Dict[str, str]) -> Dict[str, str]:
"""Protect selected Athena fields before export."""
row["email"] = re.sub(r"(^..).+(@.*$)", r"\1****\2", row.get("email", ""))
row["ip_address"] = re.sub(r"^(\d+\.\d+)\.\d+\.\d+$", r"\1.XXX.XXX", row.get("ip_address", ""))
return row
None of this replaces a broader database security model. It simply means the anonymized version of the truth stays closer to the places where users actually work.
Organizational Strategies for Athena Anonymization
Technical controls fail surprisingly often for organizational reasons. The query may be protected, yet the export is not. The notebook is anonymized, yet the copied CSV is not. The QA dataset was sanitized once, but refreshes quietly restored production truth. To avoid that cycle, strong Athena anonymization programs usually follow four habits:
- Design by audience. Support, BI, engineering, and vendor users rarely need the same degree of visibility.
- Protect the whole path. Query results do not stop at Athena; they move into notebooks, reports, and pipelines.
- Review downstream exposure. Cross-platform visibility matters more when the data estate spans 40+ data platforms.
- Treat anonymization as governance. A policy is more durable than a helpful SQL snippet somebody pasted into a dashboard six months ago.
This is where a formal control plane becomes useful. Instead of trusting every analyst to remember the safe version of a query, you build one layer that applies the logic consistently and makes the result observable.
DataSunrise: The Practical Anonymization Layer for Amazon Athena
DataSunrise is most useful in Athena when anonymization needs to become repeatable instead of improvised. Rather than scattering transformations across user queries, the platform lets teams define the protected scope, assign the masking method, and observe what happened after the query ran.
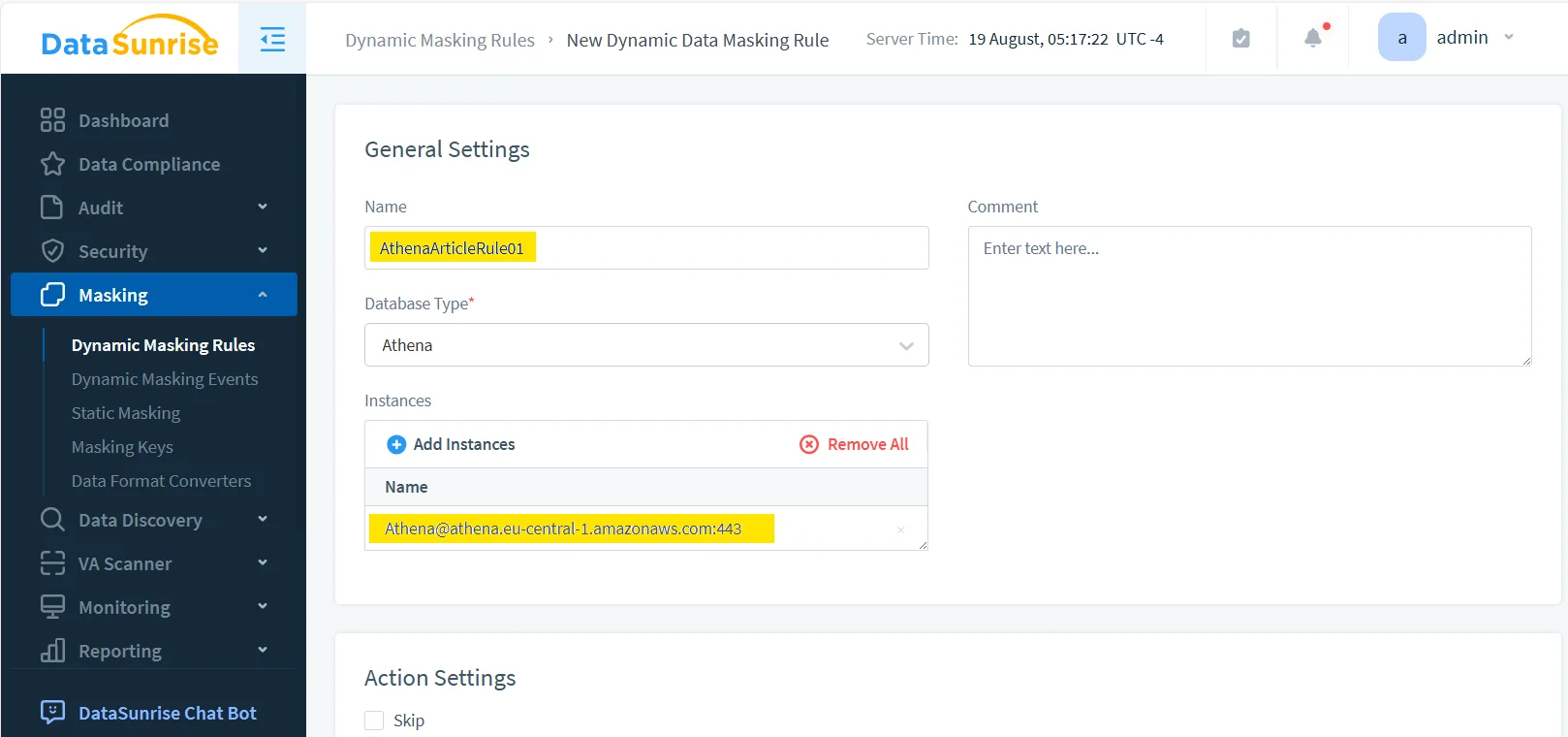
1. Centralized rule management
The first operational advantage is simple visibility. When anonymization lives as policy, administrators can track which rule protects which Athena instance, review priorities, and expand coverage without reverse-engineering a pile of copied SQL.
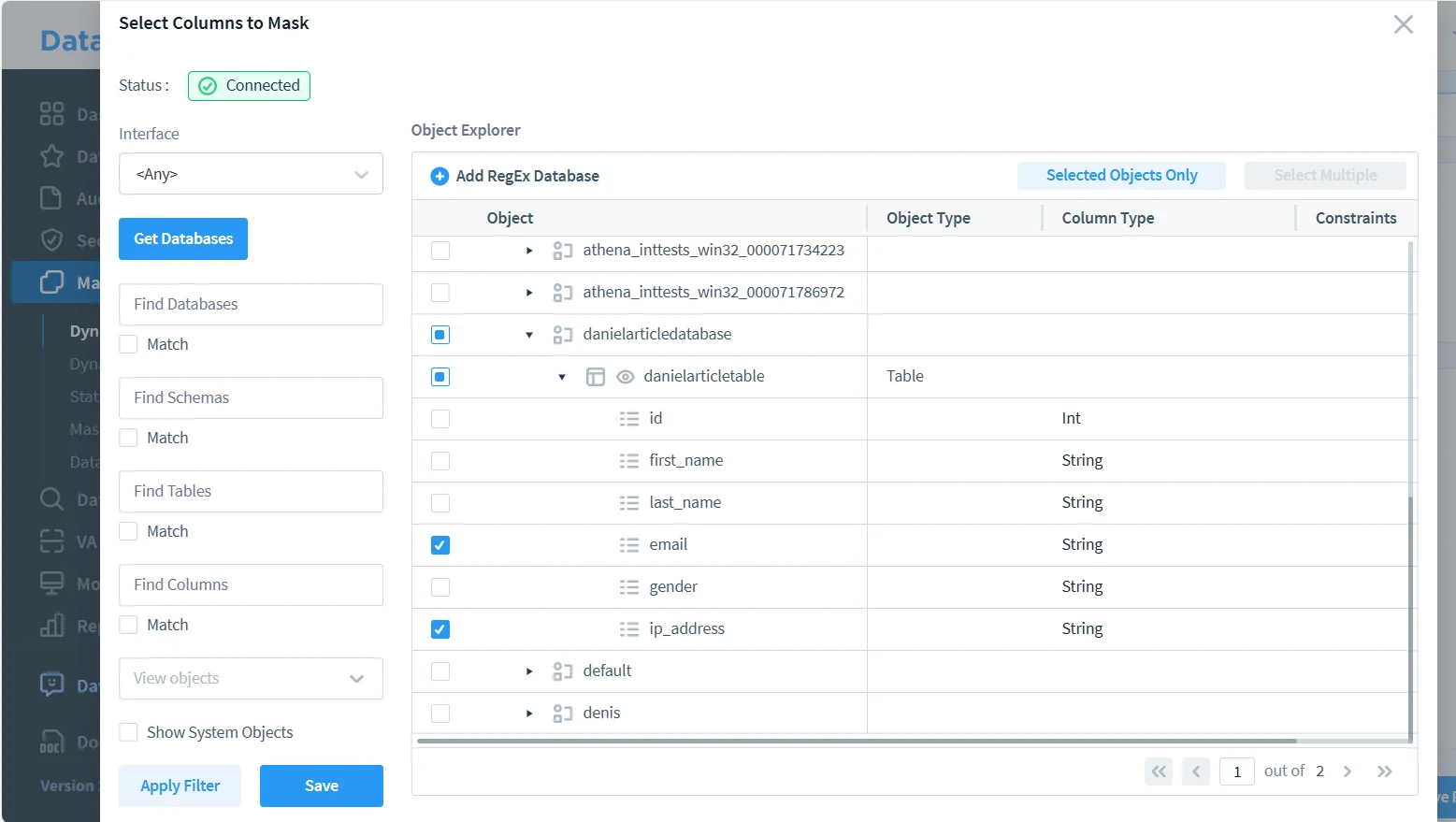
2. Precise field selection
The next advantage is selectivity. Real anonymization projects rarely protect every field the same way. A good policy targets only the columns that genuinely need transformation, which is why identifying the exact objects to protect is so important.
3. Unified visibility around every protected query
A strong control is not just applied — it is visible. This is why DataSunrise pairs anonymization with data audit, detailed audit logs, a defensible audit trail, and broad database activity monitoring. When reviewers ask who queried the dataset, which fields were protected, and whether the rule executed, the answers are already part of the system rather than a manual reconstruction effort.
The same operational model becomes stronger when paired with a database firewall, periodic vulnerability assessment, centralized Compliance Manager reporting, and the broader guidance in the security guide. At that point, anonymization stops being a narrow SQL tactic and becomes part of a wider protection program.
An anonymization project can still fail even when the transformed output looks correct at first glance. If the anonymized values still allow easy re-identification, the control is too weak. If the transformation breaks joins, filters, dashboards, or test workflows, users will bypass it. Validate privacy strength and operational utility together.
The Compliance Imperative
| Regulation | Athena Requirement | Solution Approach |
|---|---|---|
| GDPR | Personal data should not be unnecessarily exposed in analytics, exports, or shared reporting | Use role-scoped anonymization and policy-based masking to support data minimization |
| HIPAA | Protected health-related values require controlled handling in non-clinical workflows | Apply field-level anonymization and auditable access controls |
| PCI DSS | Payment-related data should not spread into query outputs or copied datasets without protection | Preserve only validation-safe patterns while restricting raw disclosure |
| SOX | Financial data access must remain accountable and appropriately limited | Combine anonymization with monitoring, auditing, and policy review |
Conclusion: Making Athena Data Useful Without Exposing the Real Thing
Data anonymization in Amazon Athena works best as a layered practice:
- Discover sensitive fields before they spread into shared query paths.
- Choose the right transformation based on whether the workload needs recognition, consistency, or irreversible protection.
- Apply the policy in the real access path so users get protected results by default.
- Audit the outcome across environments so anonymization remains visible, provable, and maintainable.
Tools like DataSunrise give Athena teams the infrastructure to do that consistently. You keep analytics usable, testing practical, and support workflows functional without handing every user the raw version of sensitive data. That is the real point of Athena anonymization: not to make datasets decorative, but to make them safer everywhere they actually travel.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now