
Data Masking Tools and Techniques for Amazon Athena
Amazon Athena makes it easy to run SQL over data in S3, which is exactly why teams love it and exactly why privacy problems show up so quickly. The same convenience that helps analysts answer questions fast can also expose raw email addresses, account identifiers, IP addresses, and free-text notes to notebooks, BI tools, and support workflows that were never meant to become a parade of sensitive values.
That is where data masking stops being a nice idea and becomes an operational control. In Athena, masking is not one feature and not one button. It is a toolbox. Some teams start with SQL transformations. Others rely on access restrictions. Mature programs usually begin with data discovery so they know where Personally Identifiable Information (PII) actually lives before they try to hide it.
This guide looks at the main tools and masking techniques that make sense for Athena, from native AWS options to policy-based controls in DataSunrise. If you want the Athena-specific DataSunrise references alongside this broader article, the product pages on data masking for Amazon Athena, dynamic data masking for Amazon Athena, and the setup guide for masking data for Amazon Athena are the most direct next reads.
The Athena masking toolbox in one view
The best Athena strategy is usually layered rather than dogmatic. One technique handles live query protection, another fits copied datasets, and a third helps limit who can reach sensitive columns in the first place.
| Tool or Technique | Best Fit | What It Does Well | Where It Falls Short |
|---|---|---|---|
| SQL masking expressions | Fast tactical fixes for a few columns | Simple, transparent, and easy to test | Hard to govern at scale |
| Athena views | Reusable masked projections for known audiences | Turns a masking query into a logical object | Maintenance grows with every new table and audience |
| Lake Formation filters | Strict column, row, and cell restrictions | Strong native governance for who sees what | Better at restriction than at nuanced masking output |
| Dynamic masking | Live analytics and support access | Protects sensitive values at query time | Needs centralized policy management |
| Static or synthetic masking | Dev, QA, training, and vendor datasets | Creates safer copies outside production | Requires refresh and distribution discipline |
Masking also works best when it is paired with access controls, role-based access control, and the principle of least privilege. Permissions decide who can open the door. Masking decides what a person should see once they are inside.
Start with the columns that are both sensitive and frequently queried: email, phone, IP address, account identifiers, location fields, and free-text notes. That first pass removes the biggest exposure risk without turning the dataset into something nobody can actually use.
Which masking techniques work best in Athena?
Not every column deserves the same treatment. Good masking is selective. Better masking is selective and useful.
- Partial masking is ideal for email, phone, or account identifiers when users need recognition without full exposure. DataSunrise documents several common patterns in its overview of masking types.
- Dynamic masking is the natural fit for shared Athena query paths because it protects live results without rewriting the source table. That is why it remains the flagship option for dynamic data masking.
- Static masking makes more sense when the data is leaving production and moving into QA, development, training, or contractor environments. That is the territory of static masking.
- Synthetic replacement is useful when teams need realistic but non-real values in lower environments. It pairs well with synthetic data generation.
The practical rule is simple: use the weakest transformation that still protects the field well enough for the real risk. There is no point masking an IP address so aggressively that operational teams lose subnet-level visibility. There is also no point preserving so much of an email address that anybody with context can reconstruct the original value in five seconds.
Native AWS tools for Athena masking
AWS gives Athena teams two especially useful building blocks. First, Athena views let you create logical tables that present a transformed version of the original query result. That works well for repeatable masked projections, especially when you know which audience will use the view.
CREATE VIEW analytics.masked_users AS
SELECT
id,
first_name,
last_name,
regexp_replace(email, '(^..).*(@.*$)', '$1***$2') AS email,
regexp_replace(ip_address, '(\\d+\\.\\d+)\\.\\d+\\.\\d+', '$1.XXX.XXX') AS ip_address
FROM raw.users;Second, Lake Formation data filters can enforce column-level, row-level, and cell-level restrictions. That is a powerful native control when the goal is to narrow visibility by user or team. It is extremely valuable, but it is not identical to masking. Restriction answers “may this user see this data at all?” Masking answers “what version of the value should this user receive?”
For small deployments, those native options may be enough. For larger ones, they become the foundation rather than the whole solution.
Applying a masking tool in practice with DataSunrise
Where Athena masking gets interesting is the moment teams want something more operational than a handful of SQL workarounds. This is where DataSunrise becomes useful: not as a replacement for good AWS governance, but as the control layer that turns masking into a policy-driven workflow.
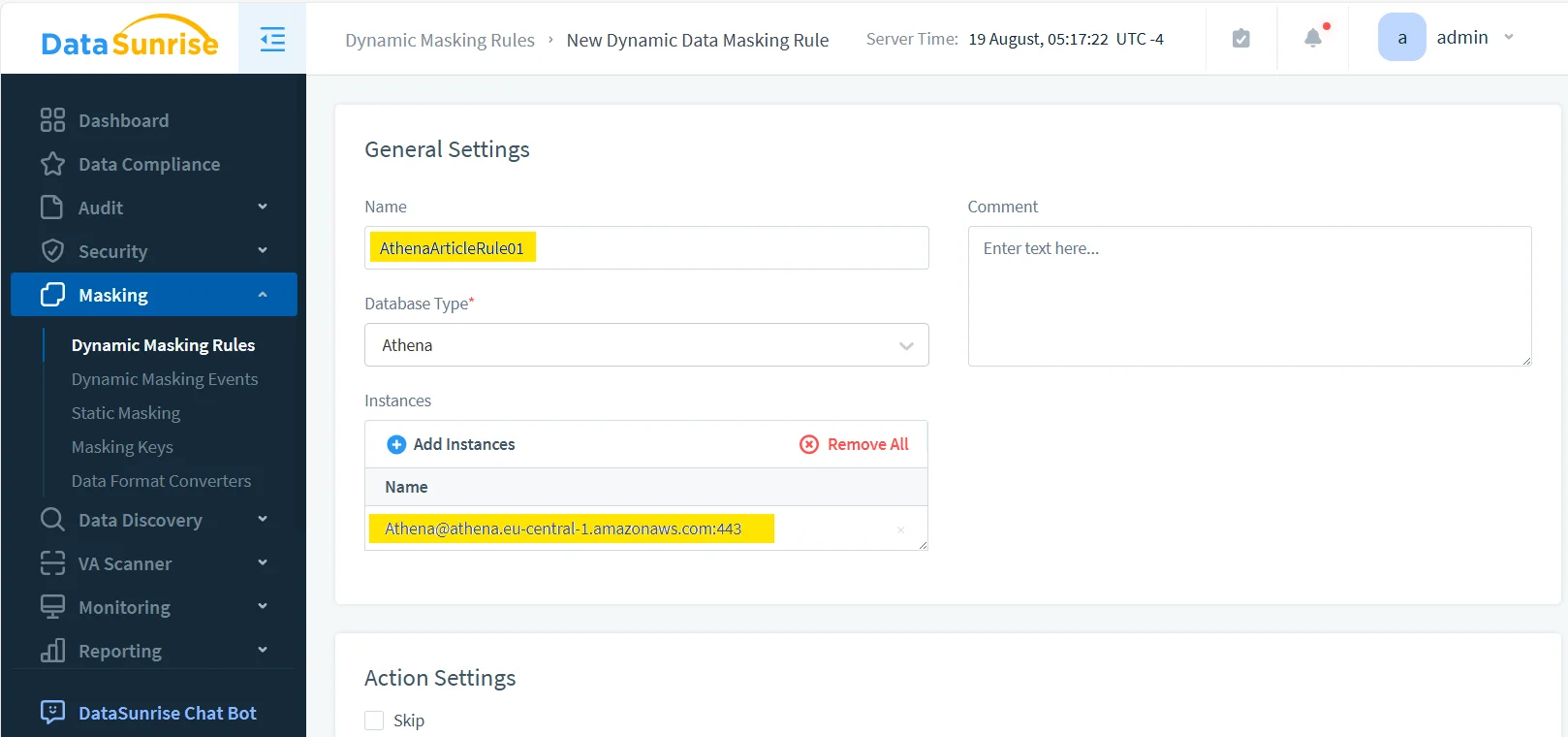
1. Create the Athena masking rule
The first step is to define the rule and attach it to the correct Athena instance. That makes the rule visible, reusable, and easier to manage later when you add more protected tables or adjust priorities.
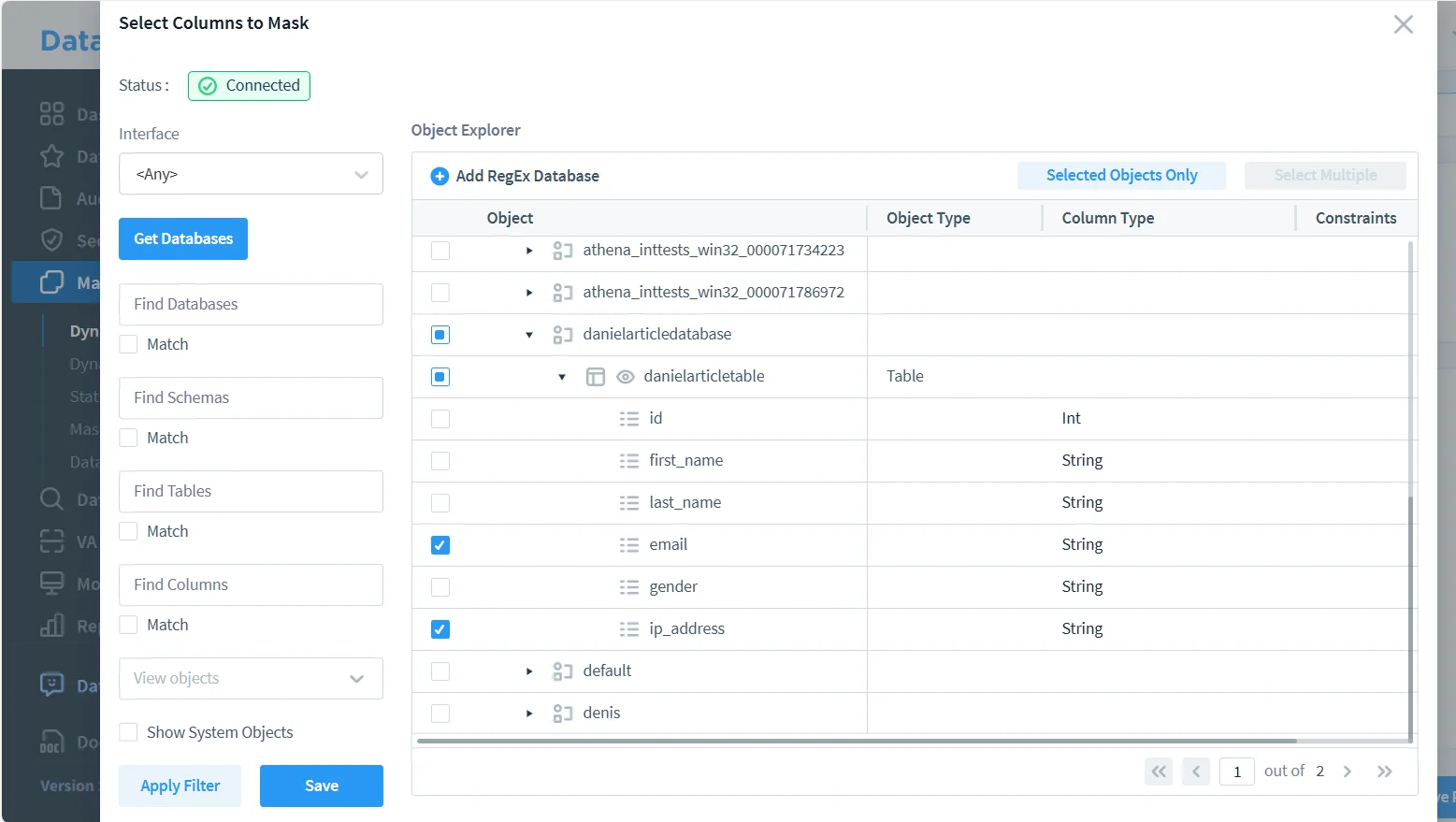
2. Select the sensitive columns
Next, choose the specific objects and fields to protect. In the example below, the rule targets the email and ip_address columns. That is a sensible combination because both fields are highly identifying but still show up often in reporting and troubleshooting queries.
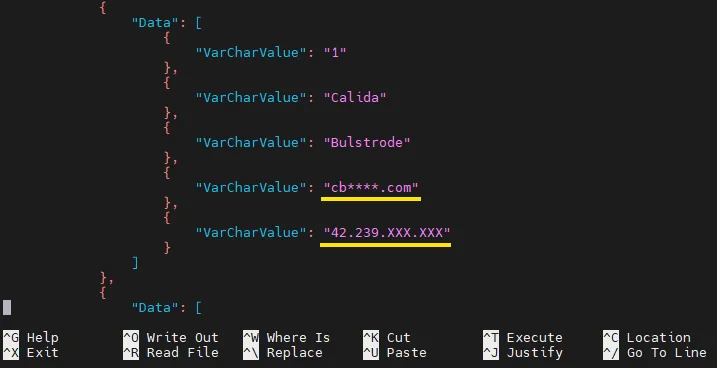
3. Validate the masked output in a real query path
Configuration is only half the job. The important part is what comes back to the user. In the output below, the original values are no longer exposed, but the result still preserves enough shape for analysis and validation.
This is also the point where visibility matters. Pair query-time masking with data audit, detailed audit logs, a defensible audit trail, and database activity monitoring. That combination tells you not only that a rule exists, but that it actually executed for the people and queries that matter.
A masking project can still fail even when the screenshots look great. If the transformed output breaks filters, joins, dashboards, or support workflows, users will work around it. If the masking preserves too much detail, re-identification risk remains. Validate both utility and privacy risk before treating the rollout as finished.
Why DataSunrise is useful beyond one masking rule
The real advantage is not a single masked field. It is the ability to combine multiple controls into one operating model for Athena and neighboring platforms:
- A policy layer for live protection in the query path
- Broader support across 40+ data platforms when Athena is only one piece of the stack
- Stronger perimeter protection with a database firewall
- Operational hardening through vulnerability assessment
- Centralized reporting and control evidence through Compliance Manager
- Better alignment to a broader security guide rather than treating masking as a one-off trick
Compliance pressure still applies to Athena query results
Moving data into a lake does not make the compliance problem disappear. It usually makes it more distributed.
| Framework | Typical Athena Exposure | Useful Masking Response |
|---|---|---|
| GDPR | Personal data shows up in broad analyst queries and shared reports | Dynamic masking and access scoping reduce unnecessary disclosure |
| HIPAA | Healthcare-related identifiers spread into non-clinical analytics | Field-level masking limits exposure while keeping workflows usable |
| PCI DSS | Payment-related values leak into copied exports and support queries | Pattern-preserving masking reduces risk without breaking validation logic |
| SOX | Financial and reporting data becomes too widely visible | Masking plus auditable controls improves accountability |
Conclusion: choose the right tool, then choose the right technique
Data masking for Amazon Athena works best when you treat it as a layered toolbox rather than a single product feature. Native AWS options such as views and data filters are valuable. They solve real problems and should be part of the design. But as teams, datasets, and reporting paths multiply, the real challenge shifts from “can we mask this field?” to “can we apply the right masking method consistently, observe it, and prove it?”
That is why a practical Athena program usually combines several elements: native query logic, precise access rules, query-time masking for live data, safer copies for lower environments, and surrounding audit evidence. Done well, the result is not merely hidden data. It is a system where useful analytics can continue without turning every query into a quiet privacy incident waiting to happen.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now