
Data Obfuscation in Amazon Athena
Amazon Athena is excellent at turning data in S3 into something analysts, engineers, and support teams can query in minutes. That convenience is exactly why sensitive values spread so quickly once a lake becomes useful. A query written for troubleshooting can return real email addresses. A notebook used for analysis can carry raw account identifiers into a CSV export. A dashboard intended for trends can quietly expose IP addresses and free-text notes to a much wider audience than anyone originally planned.
That is why data obfuscation matters. In practical terms, obfuscation is the art of making sensitive values less revealing while keeping the result set useful. It sits in the same family as data masking, but the goal is broader: preserve enough shape, pattern, or context for work to continue while removing the parts that create unnecessary exposure. A good Athena rollout usually starts with data discovery and classification of Personally Identifiable Information (PII) before anyone decides how much of a value should remain visible.
Obfuscation also works best when it is not the only control in the room. Teams still need access controls, role-based access control, and the principle of least privilege. Those controls decide who reaches a dataset in the first place. Obfuscation decides what version of the value they should see once the query runs. In native AWS terms, that usually means combining query logic, Athena views, and Lake Formation data filters with a more centralized protection model when the environment grows beyond a few hand-maintained queries.
What obfuscation should mean in an Athena environment
Obfuscation in Athena should not be treated as a fancy synonym for hiding everything. The real aim is controlled transformation. You keep the data set analytically useful, but you change what users receive in the result set. For some columns, that means partial reveal. For others, it means deterministic replacement, bucketing, or pattern-preserving substitution. In a support workflow, an analyst may need to recognize that two tickets came from the same domain without seeing the full email address. In an operations workflow, a team may need the first two IP octets to spot traffic patterns without revealing the full host.
That is also why there is no single correct obfuscation technique. DataSunrise documents a range of masking types, and in Athena the right one depends on what the workload needs to preserve. Live access often points to dynamic masking. Lower environments often need static masking. When teams need realistic but non-real values for development or training, synthetic data generation may be the cleaner answer.
| Field Type | Useful Obfuscation Technique | Why It Works in Athena | Common Mistake |
|---|---|---|---|
| Prefix and suffix preservation | Keeps enough pattern for support and grouping | Leaving too much of the local part visible | |
| IP address | Subnet preservation with host redaction | Retains network-level troubleshooting value | Masking so aggressively that pattern analysis breaks |
| Customer ID | Deterministic substitution | Preserves joins across related tables | Using random replacement that destroys consistency |
| Address or location | Generalization | Supports trend analysis without exposing exact details | Keeping exact street-level data in reports |
| Notes or comments | Context-aware masking | Protects sensitive fragments inside free text | Treating note columns as harmless metadata |
For Athena, the best first obfuscation targets are fields that are both sensitive and frequently reused outside the query editor: email, phone number, IP address, customer identifiers, payment references, and free-text notes. Those are the columns most likely to leak into exports, dashboards, notebooks, and ad-hoc troubleshooting.
Technical solutions: SQL-driven obfuscation for Athena queries
The simplest form of obfuscation in Athena is still SQL. For small environments or tightly controlled workflows, direct query transformations can be perfectly reasonable. They are transparent, easy to test, and useful for proving which parts of a value need to remain visible. DataSunrise’s overview of data masking for Amazon Athena is a useful reference here because it highlights the practical difference between query-time transformation and broader governance.
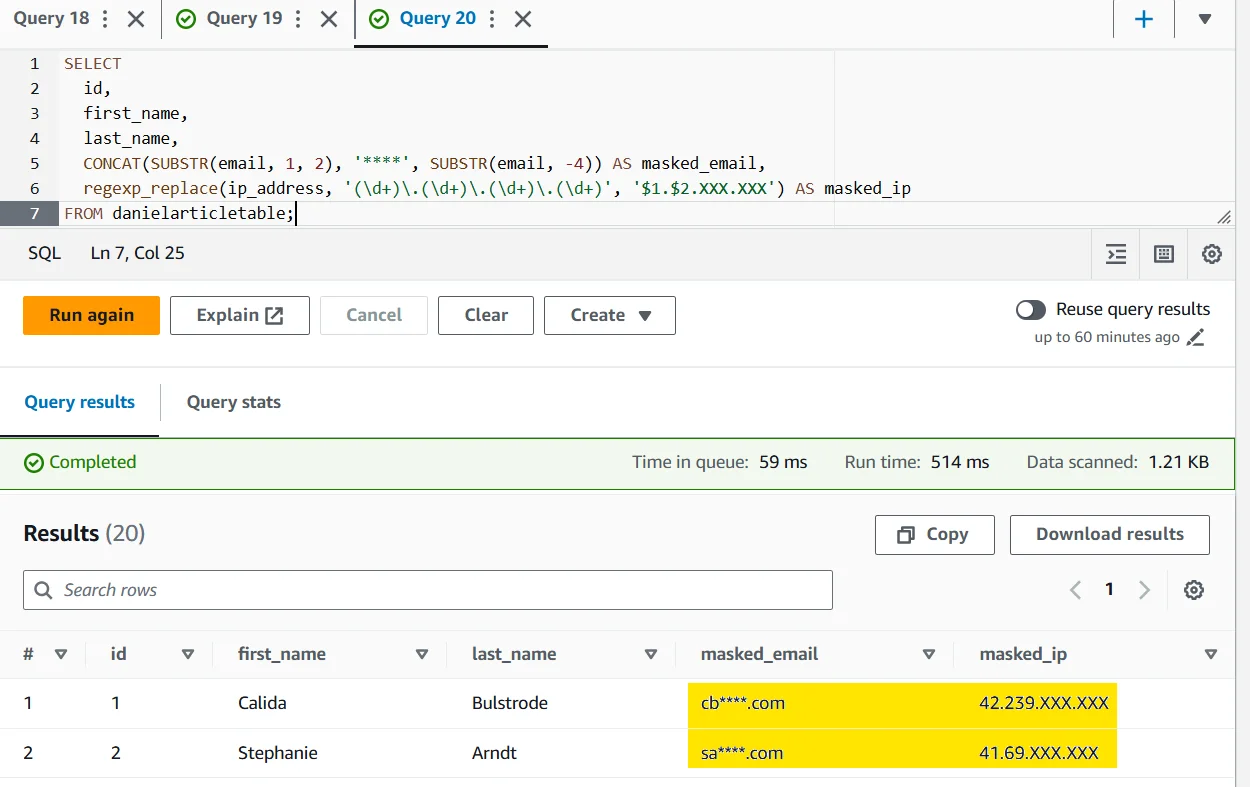
SELECT
id,
first_name,
last_name,
CONCAT(SUBSTR(email, 1, 2), '****', SUBSTR(email, -4)) AS obfuscated_email,
regexp_replace(ip_address, '(\\d+)\\.(\\d+)\\.(\\d+)\\.(\\d+)', '$1.$2.XXX.XXX') AS obfuscated_ip
FROM danielarticletable;
This approach is especially useful when you need a quick answer to a narrow problem: keep names visible, partially hide emails, and preserve only the subnet portion of IP addresses. It can also be wrapped in views for reuse. The limitation is scale. Once dozens of analysts, notebooks, and dashboards need the same protection, obfuscation should stop living as a copied SQL habit and start living as a policy.
Technical solutions: export-safe obfuscation for notebooks and scripts
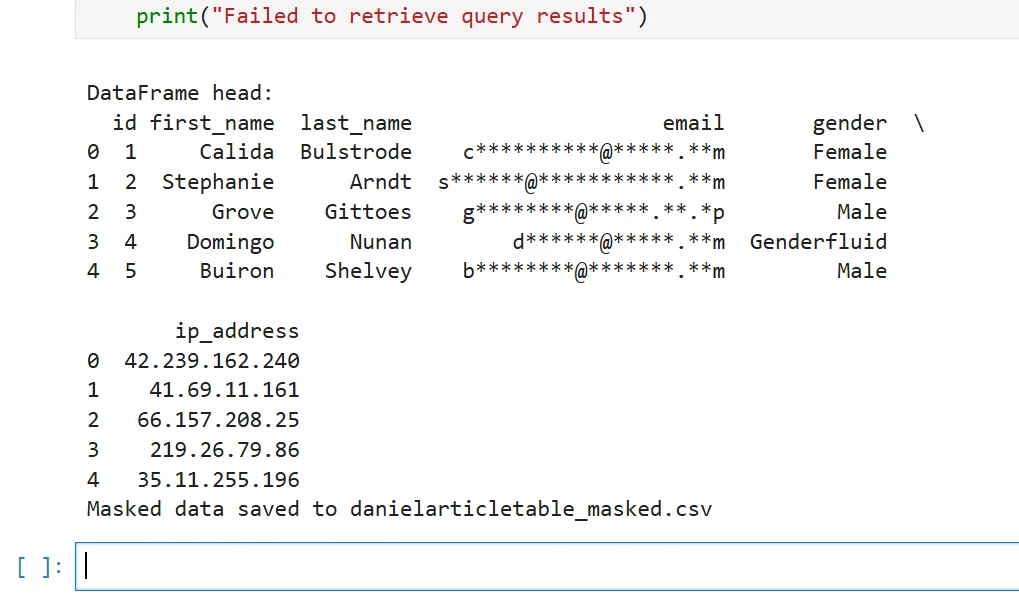
Many privacy failures happen after the query result leaves Athena. A dataset may be fine in the console and then show up unprotected in a notebook, a DataFrame, or a CSV written to shared storage. If your team regularly pulls Athena results into Python or analytics pipelines, it is worth applying export-safe obfuscation before the data is written anywhere else.
import re
from typing import Dict
def obfuscate_athena_row(row: Dict[str, str]) -> Dict[str, str]:
"""Protect sensitive Athena fields before export."""
email_value = row.get("email", "")
ip_value = row.get("ip_address", "")
row["email"] = re.sub(r"(^..).+(@.*$)", r"\1****\2", email_value)
row["ip_address"] = re.sub(r"^(\d+\.\d+)\.\d+\.\d+$", r"\1.XXX.XXX", ip_value)
return row
This kind of transformation is not a substitute for policy-based masking, but it is a useful safety layer for downstream workflows. If the output is destined for development or external testing, stronger controls such as static masking are often more appropriate than light obfuscation.
DataSunrise: the unified obfuscation layer for Amazon Athena
Once Athena becomes a shared service instead of a personal SQL tool, centralized control matters more than clever query fragments. DataSunrise approaches that problem as a policy layer rather than a one-off transformation. The platform’s guidance on dynamic data masking for Amazon Athena and the implementation steps in the Athena masking guide are helpful because they turn obfuscation into something operational, reviewable, and repeatable. That fits naturally inside a broader database security program and a more durable security guide approach.
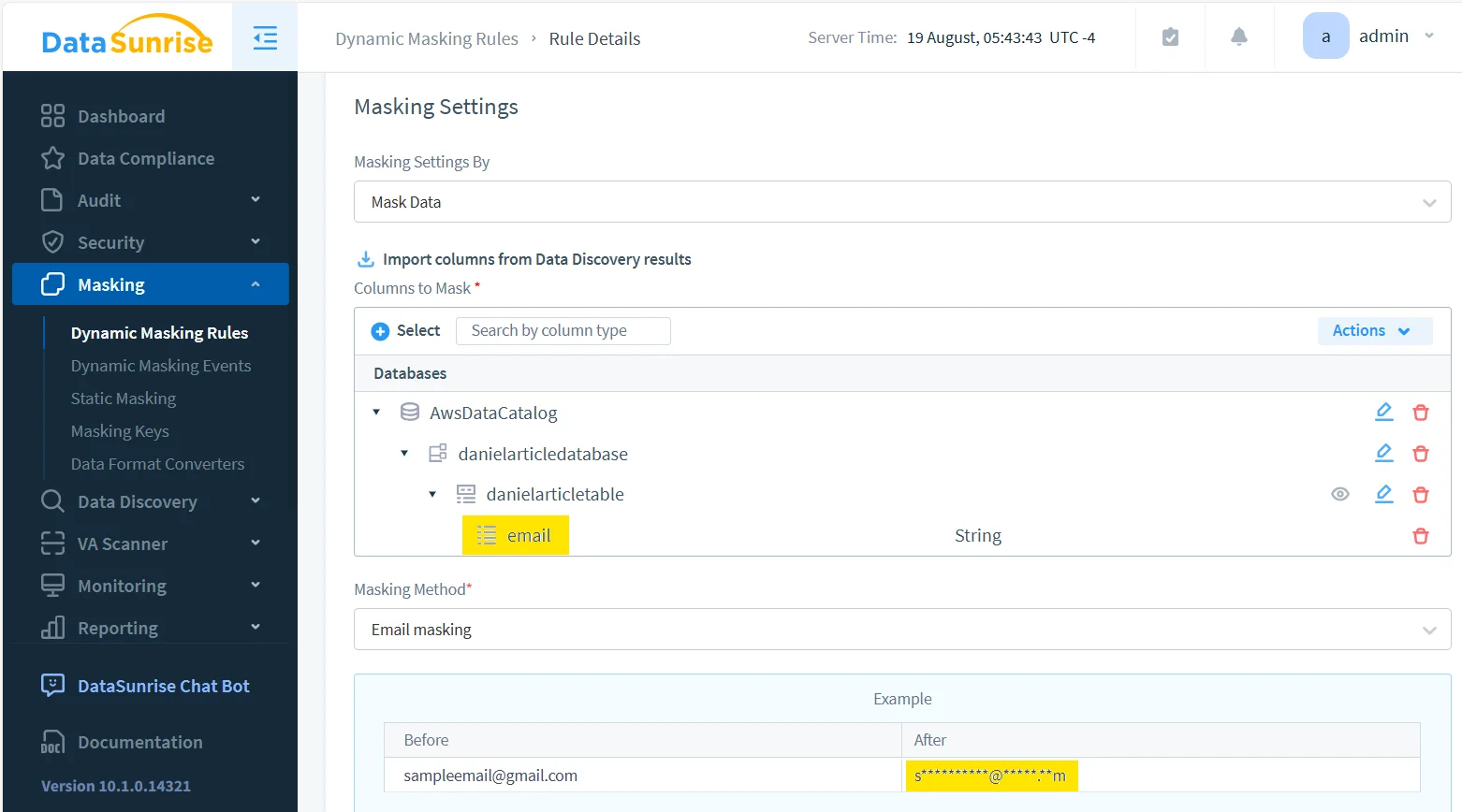
1. Discover and select what really needs protection
Policy-driven obfuscation starts with scope. Instead of hoping analysts remember which columns are risky, security teams can identify sensitive fields across 40+ supported data platforms and then apply consistent rules to the objects that matter most. In Athena, that usually means starting with email, phone, IP address, identifiers, and notes rather than trying to redesign every table on day one.
2. Apply runtime obfuscation instead of rewriting source data
For live Athena access, query-time transformation is usually the most practical pattern. Users get an obfuscated result without changing the underlying source records. This is also where surrounding controls matter. Obfuscation is stronger when it sits beside targeted security rules and other query-path protections instead of operating as an isolated feature.
3. Observe every protected query
Good obfuscation is visible. Teams should know who queried the data, which rule applied, and whether the protected output reached the expected clients. This is why DataSunrise pairs obfuscation with data audit, database activity monitoring, detailed audit logs, and a defensible audit trail. The result is not just a transformed field, but evidence that the transformation happened where it was supposed to happen.
4. Strengthen the surrounding control plane
Obfuscation works best inside a layered protection model. Teams often combine it with a database firewall, periodic vulnerability assessment, and centralized reporting through Compliance Manager. That broader design matters because Athena is rarely the only place sensitive data lives. The same records often move across pipelines, test environments, and reporting paths, so protection has to travel farther than one console screen.
Organizational strategies for Athena obfuscation
Even a good technical design can fail if the rollout model is sloppy. Four habits tend to separate workable Athena obfuscation from the kind teams quietly bypass a month later:
- Design by audience, not just by table. Support users, BI analysts, data scientists, and external testers usually need different visibility.
- Preserve business utility on purpose. If the obfuscated result breaks joins, filters, or dashboards, people will go hunting for the raw data instead.
- Validate the downstream path. Athena results often end up in notebooks, exports, and ETL jobs; those steps need testing too.
- Treat obfuscation as a governed policy. Assign owners, review cycles, and change controls instead of leaving it as scattered SQL snippets.
That discipline is what turns obfuscation from a developer trick into a durable control. It also reduces the chance that one enthusiastic ad-hoc export undoes a carefully designed privacy program.
Obfuscation can fail in two opposite directions. If you preserve too much of the original value, re-identification stays easy. If you preserve too little, analytics, troubleshooting, joins, and downstream reports stop working — and users start finding workarounds. Test privacy risk and data utility together.
The Compliance Imperative
| Regulation | Typical Athena Exposure | Obfuscation Objective |
|---|---|---|
| GDPR | Personal data appears in broad analyst access, shared dashboards, and exported query results | Reduce unnecessary disclosure and support data minimization |
| HIPAA | Protected health-related identifiers reach non-clinical users and support workflows | Limit exposure of sensitive fields while preserving legitimate operational access |
| PCI DSS | Payment-related values surface in query outputs, copied files, or lower environments | Protect high-risk financial data without breaking validation patterns |
| SOX | Financial records become too broadly visible across reporting and testing paths | Improve accountability and controlled handling of sensitive business data |
Conclusion: making Athena obfuscation operational
Data obfuscation in Amazon Athena works best as a layered practice:
- Identify sensitive fields before users normalize access to them.
- Apply the right obfuscation method based on what the workload must preserve.
- Enforce the control in the real query path instead of relying on copied SQL habits.
- Audit and review the result so the policy remains visible, provable, and maintainable.
That is ultimately the point of obfuscation in Athena. It is not about making data prettier, and it is not about hiding every value indiscriminately. It is about giving analysts, developers, and support teams enough data to do their jobs without handing them the full sensitive truth by default. When DataSunrise turns that principle into a repeatable control layer, Athena stays useful — and a lot less reckless.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now