
NLP, LLM and ML Data Compliance Tools for Amazon OpenSearch
NLP, LLM & ML data compliance tools for Amazon OpenSearch matter because OpenSearch is no longer “just search” or “just logs.” In modern stacks it powers observability, security analytics, and even AI copilots that summarize incidents or answer questions over indexed telemetry. The moment OpenSearch data becomes a source for RAG, prompt enrichment, or ML feature extraction, compliance risk jumps: unstructured payloads can contain identifiers, secrets, and regulated context that is now queryable at machine speed.
AWS provides the managed platform for Amazon OpenSearch Service, but the responsibility to identify sensitive data, control exposure, and produce audit evidence remains with your organization. This guide shows where NLP/LLM/ML help, where they can hurt, and how DataSunrise enables automated discovery, governance, auditing, masking, and reporting for AI-driven OpenSearch environments.
Why AI Workloads Increase Compliance Pressure in OpenSearch
Classic OpenSearch compliance challenges already exist: semi-structured data, fast-evolving indices, and broad access granted for convenience. AI workloads amplify those issues because they increase both data reach and data interpretation. NLP pipelines extract entities from free text, LLMs summarize content (including sensitive snippets), and ML models detect patterns that can indirectly encode personal information. This is not theoretical—an LLM answering “what happened last night?” can unintentionally reveal user identifiers embedded in logs.
That’s why AI-aware compliance must align with data compliance regulations and common frameworks such as GDPR, HIPAA technical safeguards, and PCI DSS. In practice, regulators don’t care whether data lives in a database, a log index, or a search cluster—if it contains regulated content, it must be governed.
What “AI-Ready Compliance” Looks Like for OpenSearch
If OpenSearch feeds NLP/LLM/ML systems, compliance needs to be continuous and measurable. A practical AI-ready program focuses on five outcomes:
- Know what data exists: continuously identify PII and other sensitive patterns across indices and documents.
- Limit what AI can access: enforce access boundaries and scope to prevent “prompt equals admin.”
- Reduce what AI can reveal: mask or tokenize sensitive values before they reach prompts or model context windows.
- Record evidence: maintain defensible logs and trails that explain who accessed what and why.
- Automate reporting: generate repeatable evidence packages for audits and internal controls.
How NLP, LLM, and ML Support Compliance Controls
NLP for unstructured sensitive data discovery
Regex-only approaches fail in OpenSearch because the most dangerous data is often buried in free-text logs and nested JSON fields. NLP increases coverage by detecting entities and context within unstructured content. DataSunrise supports scalable classification through Data Discovery, helping teams locate sensitive fields early—before that data is ingested into embeddings, prompts, or training datasets.
LLMs for context and explainability
LLMs can improve analyst workflows, but they also introduce new compliance questions: what data did the model see, what did it summarize, and what did it output? LLM-enabled governance needs policy enforcement and auditability around access paths—not blind trust in the application layer. This is where centralized policy orchestration becomes critical.
ML for behavior analytics and anomaly detection
ML is well-suited for detecting abnormal query behavior: bursts of high-cardinality searches, repeated access to sensitive indices, or unusual retrieval patterns consistent with scraping. DataSunrise strengthens this with user behavior analysis, allowing teams to identify suspicious usage that traditional allow/deny controls might miss.
Reference Architecture: AI-Aware Compliance Layer for OpenSearch
The safest pattern is to enforce compliance close to the OpenSearch access layer so that discovery, policies, and audit evidence are consistent across tools—dashboards, APIs, and AI agents. DataSunrise provides a centralized compliance layer for governance and evidence collection without requiring index redesign.
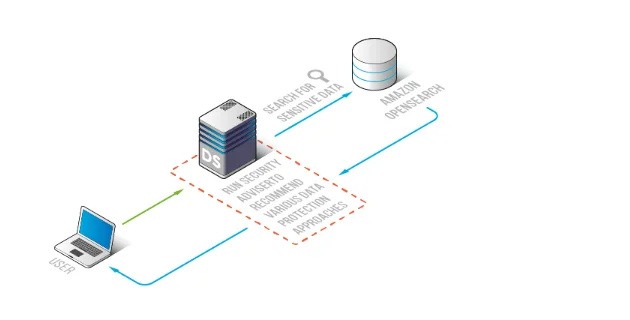
Control Mapping: Where Compliance Tools Fit in an NLP/LLM/ML Pipeline
| AI stage | OpenSearch risk | Compliance control | Outcome |
|---|---|---|---|
| Ingestion | Sensitive fields indexed into searchable docs | Discovery + scope definition | Known inventory and governed objects |
| Retrieval (RAG) | Prompts pull raw identifiers into context | Masking + least privilege | Lower exposure in LLM context |
| Analytics | Broad access for dashboards and investigations | Centralized access controls + audit logging | Traceability and accountability |
| Model training | Training datasets encode regulated data | Static masking or synthetic data | Safe datasets for ML/LLM tuning |
| Operations | Drift: new indices/pipelines appear silently | Continuous monitoring + reporting | Controls stay current over time |
DataSunrise Tools for Automating OpenSearch Compliance
1) Policy-driven compliance management
To scale governance, policies must be centrally defined and applied consistently. DataSunrise provides policy workflows through Compliance Manager, enabling teams to standardize rules across environments. Pair policies with RBAC and centralized access controls so AI tools and users receive only the access required for their role.
2) Scope selection for sensitive OpenSearch objects
Compliance tooling must be precise: govern the sensitive indices without breaking low-risk analytics. DataSunrise supports object-level scoping so policies apply only where required—especially important when the same OpenSearch cluster serves both operational dashboards and AI workflows.
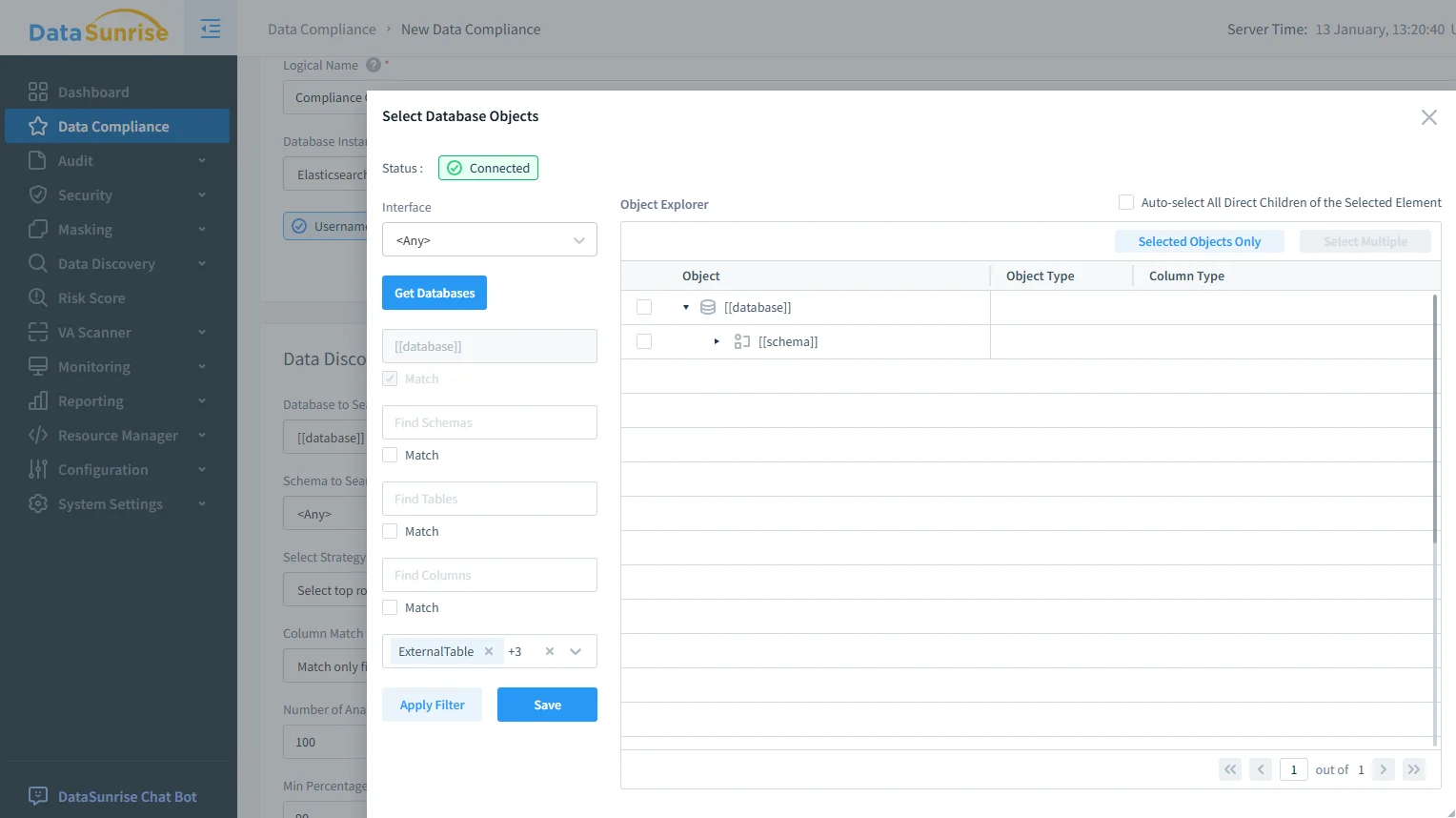
Scope selection for OpenSearch compliance: choose governed objects so AI workflows only touch approved indices and fields.
3) Auditing and evidence for AI-driven access
AI increases the number of access paths (dashboards, APIs, agents), so audit evidence must be centralized. DataSunrise supports detailed audit logs via Data Audit, and preserves investigation-grade traceability with audit trails. For runtime oversight, database activity monitoring helps detect risky query behavior early.
For baseline service logging guidance, AWS documents OpenSearch audit logging here: Amazon OpenSearch audit logs. In AI-heavy environments, centralized evidence is typically easier to defend than scattered logs across multiple layers.
4) Masking and dataset safety for ML/LLM pipelines
Most AI workloads do not require raw identifiers. DataSunrise reduces exposure through dynamic data masking for query-time protection and static data masking for safer extracts and non-production pipelines. When training or testing needs realistic structure without real identities, synthetic data generation helps keep AI experimentation compliant.
5) Preventive security controls and posture validation
AI agents can unintentionally amplify abuse (for example, “search everything for X”). Preventive controls help limit blast radius. Use database firewall rules to block abusive patterns and vulnerability assessment to identify drift and misconfiguration that can undermine compliance.
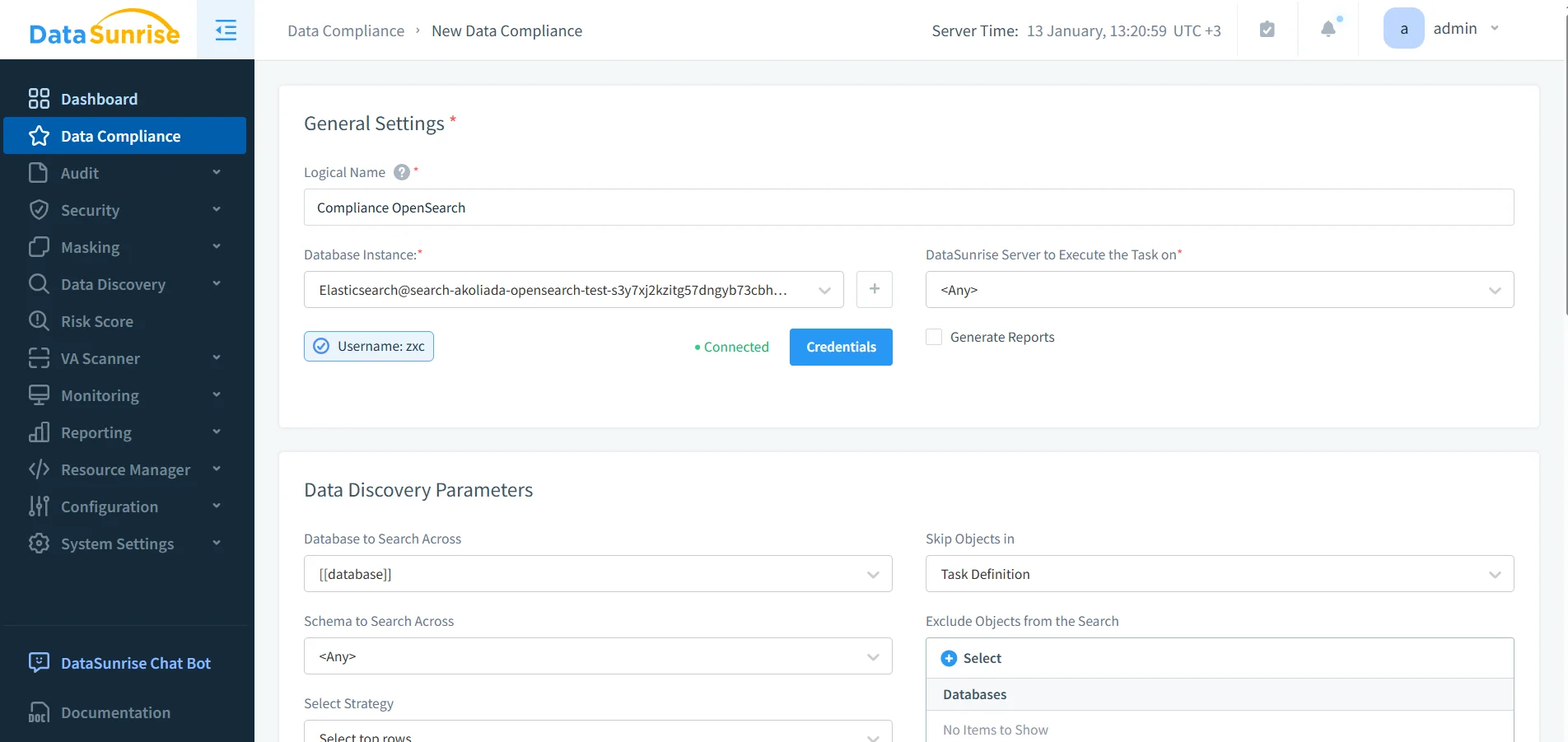
Compliance rule configuration: automate governance actions (audit, masking, reporting) for AI-assisted OpenSearch workflows.
Automated Reporting for NLP, LLM, and ML Compliance
Auditors do not want screenshots; they want repeatable evidence. DataSunrise supports automated reporting with report generation and automated compliance reporting. In AI-heavy environments, automation is the difference between “we think we’re compliant” and “here is the evidence package.”
To keep compliance durable through index churn and pipeline changes, align controls with continuous data protection so discovery, policies, and evidence stay current.
Use AI where it actually helps compliance: NLP for unstructured discovery, ML for anomaly detection, and LLMs for analyst context. Then lock it down with scoped policies, masking, and audit trails so every AI-driven access remains explainable and defensible.
Do not allow LLMs, embedding pipelines, or ML jobs to consume raw OpenSearch indices without governance. Prompt-driven access to unfiltered logs can expose regulated data (and secrets) in outputs that are hard to trace. Always enforce scope, masking, and centralized auditing before AI touches OpenSearch data.
Conclusion
NLP, LLM & ML data compliance tools for Amazon OpenSearch work best when they are not “bolt-ons,” but part of a control plane: discover sensitive data continuously, scope access precisely, reduce exposure with masking, monitor for anomalies, and generate audit-ready evidence automatically. DataSunrise provides an integrated set of controls to govern AI-driven OpenSearch workloads at scale.
To plan deployment, review DataSunrise overview and available deployment modes, then start with Download or request a guided Demo.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now