
Sensitive Data Protection in Amazon Athena
Amazon Athena gives teams a fast way to query data in S3 without standing up traditional database infrastructure, which is excellent for analytics and much less charming when raw customer details start surfacing in notebooks, dashboards, exports, and support queries. In Athena, the same convenience that makes data easy to explore can also make it easy to overshare. A query that looks harmless can still return full email addresses, account identifiers, IP addresses, or free-text notes that never should have traveled that far.
That is why sensitive data protection in Athena cannot be reduced to a single checkbox. It usually starts with data discovery, continues with classification of PII, and then moves into policy decisions about who should see what. Some users need the raw value. Many only need a recognizable pattern. Others should never receive the real value at all. The goal is not to make data useless. The goal is to keep it useful without turning every query result into a small privacy incident.
AWS also makes an important point in its Athena data protection guidance: the shared responsibility model still applies. That matters in practice because Athena may be serverless, but the responsibility for protecting content, permissions, and downstream exposure is still yours. That is where data masking becomes one of several controls that help keep sensitive values from appearing everywhere they do not belong.
A practical protection model for Athena
Protecting sensitive data in Athena works best when you treat it as a sequence of controls instead of a single feature purchase.
- Find the risky fields. You cannot protect what you have not identified, which is why discovery and classification come first.
- Restrict broad exposure. Use access controls, role-based access control, and the principle of least privilege so access is narrow before masking even enters the conversation.
- Mask what users do not need in full. This is where data masking for Amazon Athena, dynamic masking for Amazon Athena, and the step-by-step Athena masking guide become practical.
- Keep evidence that the control worked. Query-time protection needs monitoring, logs, and repeatable review so the policy does not quietly drift into fiction.
Athena teams often also combine masking with Lake Formation data filtering when they need native row-, column-, or cell-level restrictions. That is valuable, but restriction and masking solve different problems. Restriction answers whether a user may see data at all. Masking answers what version of the value a user should see when the query is allowed to run.
Protect the fields that are both high-risk and high-traffic first—emails, phone numbers, IP addresses, customer IDs, payment values, and free-text notes. In Athena, those are the columns most likely to leak into analytics, exports, notebooks, and support workflows before anyone notices.
Before you choose a technique, answer three questions
- Is this a live query or a copied dataset? Live access usually points to dynamic masking, while lower environments often need static masking.
- Does the workload need realistic but fake data? If yes, there are cases where synthetic data generation is the cleaner answer.
- Does the user need recognition, correlation, or total concealment? A support team may need a pattern-preserving value, while an external testing workflow may need something far more aggressive.
Tools and techniques that actually matter in Athena
| Tool or Technique | Best Use | What It Gives You | Main Limitation |
|---|---|---|---|
| Native SQL expressions | Fast masking for a few known queries | Simple string-level obfuscation with no extra layer | Hard to manage when the logic spreads across many queries and users |
| Lake Formation filtering | Restricting visibility at the row, column, or cell level | Strong native control over exposure boundaries | More about restriction than about reusable masked output |
| Centralized masking policies | Shared Athena access for analysts, support teams, and applications | Consistent policy instead of many hand-maintained query variations | Needs disciplined policy ownership |
| Protected copies | Development, QA, training, and vendor testing | Safer datasets outside production boundaries | Requires refresh and lifecycle management |
For a lightweight native approach, Athena users often start with SQL expressions that partially mask data in the result set. This is especially common for email and IP address fields because they benefit from preserving a recognizable shape. A quick example looks like this:
SELECT
id,
first_name,
last_name,
CONCAT(SUBSTR(email, 1, 2), '****', SUBSTR(email, -4)) AS masked_email,
regexp_replace(ip_address, '(\\d+)\\.(\\d+)\\.(\\d+)\\.(\\d+)', '$1.$2.XXX.XXX') AS masked_ip
FROM danielarticletable;
This is effective as a tactical fix, but it becomes tedious fast. The moment analysts duplicate that logic in multiple queries, notebooks, reports, and exports, you no longer have a policy. You have a habit, which is much easier to break. That is why teams graduate toward centralized data masking when Athena starts serving more than one narrow use case.
Putting a policy layer in front of Athena queries
Athena protection becomes more durable when the masking rule follows the query path instead of depending on each user to remember the safe version of the SQL. That is the value of a centralized policy layer. You define the protected fields once, choose the masking behavior once, and then validate the returned result wherever the data is actually used.
Define the masking rule
The first step is to configure the masking rule and assign a method that matches the field. Email is a good example because it usually needs pattern preservation rather than total destruction. The user should recognize that the value is an email address and perhaps even infer enough to troubleshoot, but not recover the original address itself.
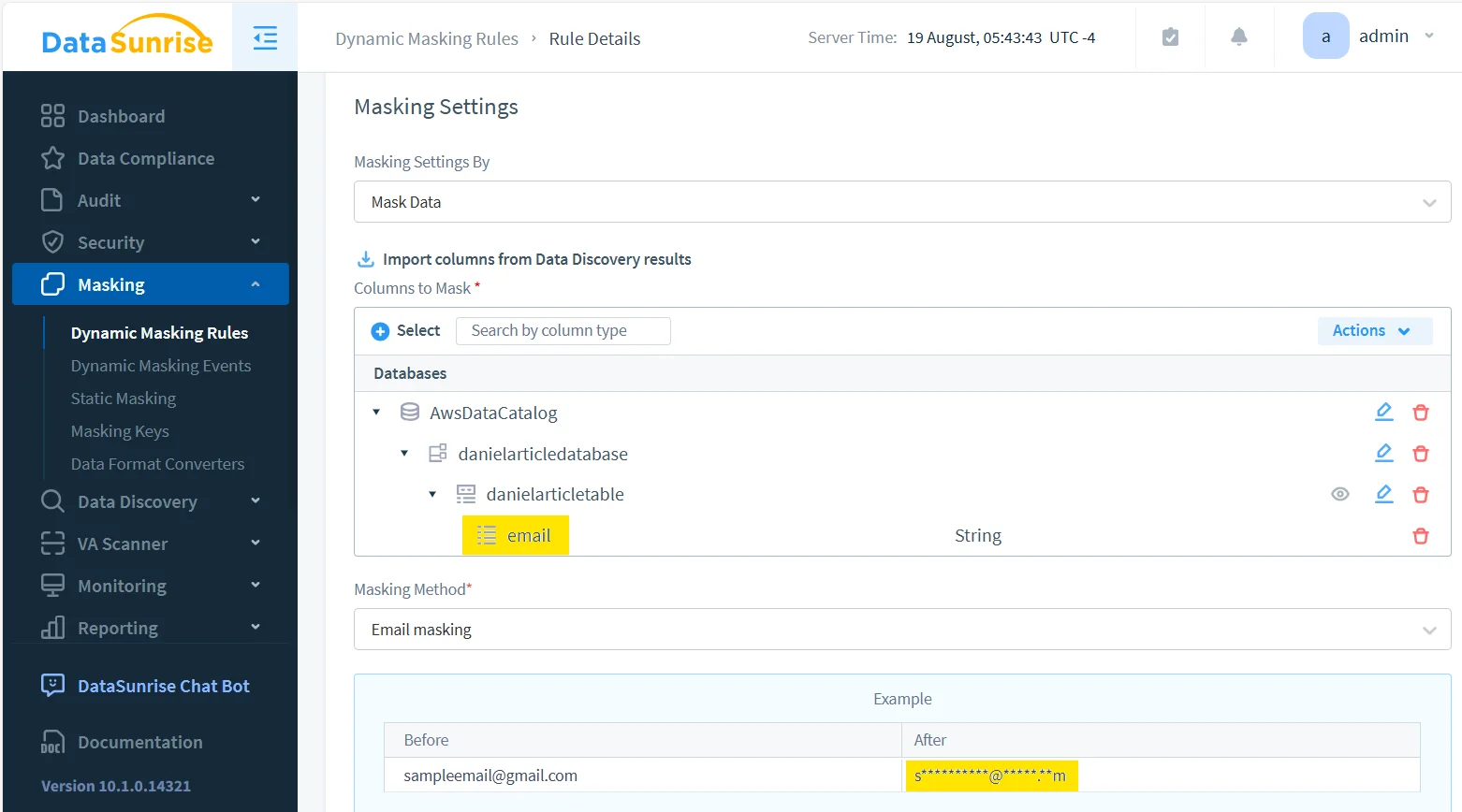
Validate the protected result in Athena itself
Once the policy is active, test it where users actually work. The Athena query below shows a familiar pattern: the record remains useful, the names remain readable, and the sensitive fields are transformed before they reach the analyst. That is the balance that usually matters most in production analytics.
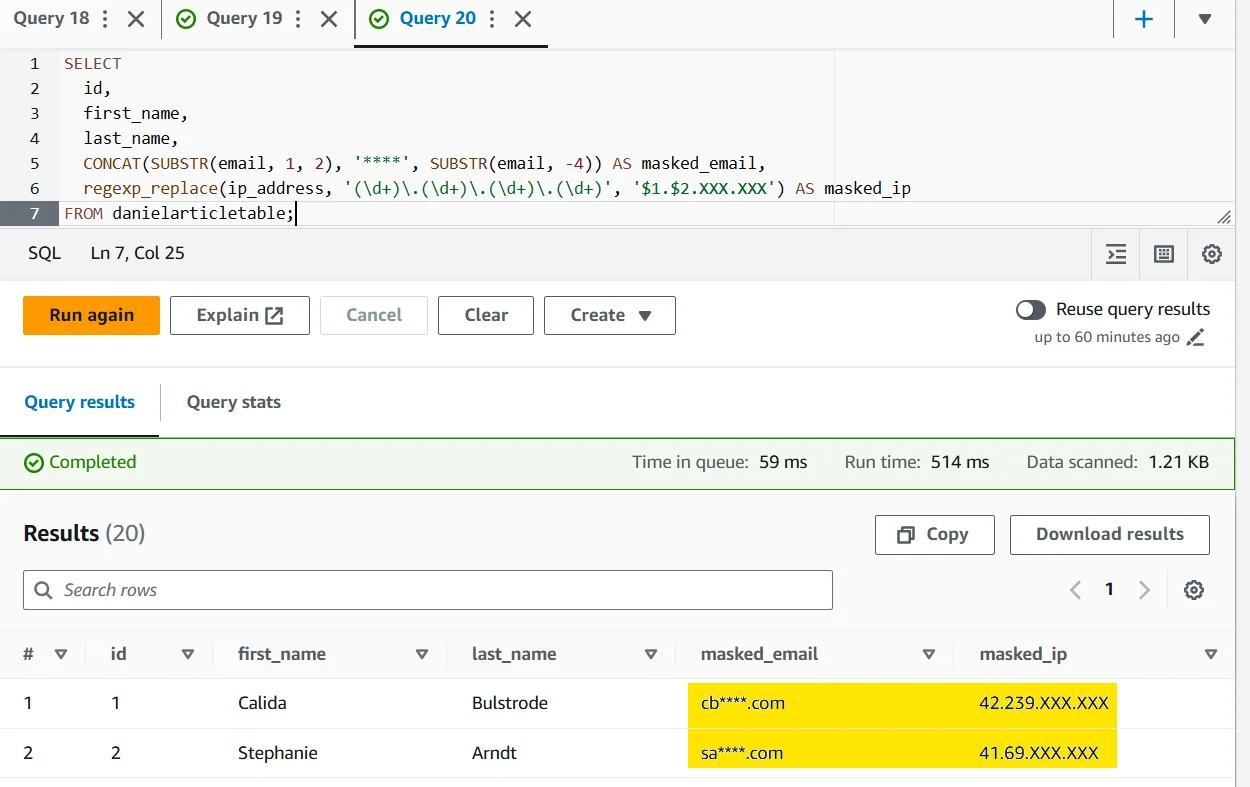
Check the downstream path too
Protection should not stop at the Athena editor. Results often move into notebooks, DataFrames, CSV exports, and downstream workflows. That means the masked version needs to survive the real path of the data, not just look good in one admin screen. The example below shows the data continuing into a notebook and then being written to a CSV, with the protected values preserved for the downstream workflow.
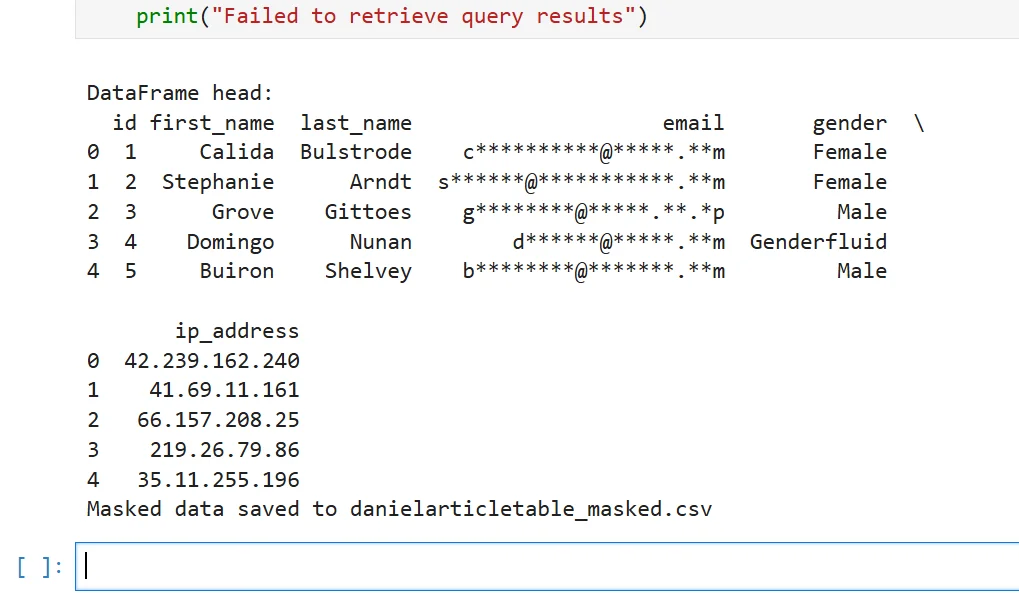
Sensitive data protection fails in two common ways: the masking is too weak, so re-identification stays easy, or the masking is too aggressive, so filters, joins, dashboards, and downstream exports stop working. Test privacy risk and operational utility at the same time.
Supporting controls that turn masking into protection
Masking is only part of the story. Teams usually get stronger results when they pair it with data audit, detailed audit logs, a defensible audit trail, and full database activity monitoring. That answers the questions security teams eventually ask anyway: who ran the query, when was the sensitive field accessed, and did the masking rule actually apply?
Beyond visibility, many teams strengthen the path with a database firewall and periodic vulnerability assessment. If the organization needs centralized evidence and policy oversight, Compliance Manager and the broader security guide help turn disconnected rules into a repeatable operating model. That matters even more when Athena is only one component in a wider stack of supported data platforms.
Compliance pressure still applies to Athena query results
| Framework | Typical Athena Risk | Protection Objective |
|---|---|---|
| GDPR | Personal data appears in broad analyst access, exports, and shared reports | Reduce unnecessary disclosure and support data minimization |
| HIPAA | Protected health-related values spread into non-clinical workflows | Restrict exposure while preserving legitimate operational use |
| PCI DSS | Payment-related data leaks into support queries or copied exports | Prevent broad visibility of high-risk financial values |
| SOX | Financial reporting data becomes too widely available across teams | Improve accountability and controlled handling of sensitive records |
Conclusion
Sensitive data protection in Amazon Athena is not one feature and not one magical product screen. It is a sequence: discover the data, limit who can reach it, mask what does not need to be fully visible, and keep evidence that the control worked in the places where data actually travels. Native AWS controls cover part of that journey. A centralized masking and audit layer makes the journey repeatable.
That is the real win for Athena teams. Analysts keep the speed and flexibility they wanted in the first place, but the raw version of sensitive data stops appearing everywhere by default. Instead of hoping every query author remembers to be careful, you build a system that is careful on purpose.
Protect Your Data with DataSunrise
Secure your data across every layer with DataSunrise. Detect threats in real time with Activity Monitoring, Data Masking, and Database Firewall. Enforce Data Compliance, discover sensitive data, and protect workloads across 50+ supported cloud, on-prem, and AI system data source integrations.
Start protecting your critical data today
Request a Demo Download Now